Virgen de Loreto
Este espacio està reservado para los artÚculos ya publicados
Articulo
Noviembre 2013
PROBLEMêTICA DE LA SEGURIDAD DE VUELO DE LAS LëNEAS COMERCIALES Y PROGRAMAS
DE PREVENCIÆN. 1ˆ Parte Conferencia llevada a cabo en el Centro de TÕcnicas
AeronÃuticas de la Base de Torrejµn de Ardoz el 17 de mayo de 1996, debidamente
autorizada por la Direcciµn de Operaciones de Iberia a peticiµn de la Oficina
de Relaciones Publicas del Cuartel General del Ejercito del Aire Realizado por el Cte. Cosme Alvarez Cabaþes, Piloto Militar,
Comandante de Vuelo del Grupo Iberia, Licenciado en PsicologÚa y Master en
Desarrollo de Recursos Humanos, Instructor de Factores Humanos del Grupo Iberia
y especialista de Factores Humanos en Aviaciµn, por la Universidad de Southern
California. Autor del libro Manual de Seguridad AÕrea. Buenos dÚas y muchas gracias por la invitaciµn que me habÕis
hecho para que pueda exponer mis ideas, ante un foro importante para mi, por su
composiciµn y calidad. BREVE HISTORIA DE LA SEGURIDAD DE VUELO. El 7 de Diciembre de 1944 las Naciones unidas crearon la
organizaciµn de Aviaciµn Civil Internacional (OACI). El Convenio de creaciµn se
firmµ en Chicago y entrµ en vigor el 4 de Abril de 1947. Este perÚodo sirviµ para cumplir, por los Estados firmantes
las condiciones de ratificaciµn y adhesiµn establecidas en el mismo. En el PreÃmbulo, se exponen las razones y fines que dieron
lugar a su elaboraciµn. En este Convenio de Chicago y concretamente en dos de sus
artÚculos, se basa el nacimiento de la moderna Seguridad de Vuelo en se
reconocimiento internacional, ya que de hecho la Seguridad de Vuelo se estaba
llevando a cabo en el mundo aeronÃutico, tanto civil, como militar, pero su
estatus legal se encuentra en estos dos artÚculos. El artÚculo 37.-k) del capÚtulo de Normas y MÕtodos
Recomendados Internacionales, establece que la OACI adoptarà y enmendarÃ, en su
oportunidad, segºn sea necesario, las normas, mÕtodos recomendados y
procedimientos internacionales que traten de "las Aeronaves en peligro e
investigaciµn de accidentes". En el artÚculo 16 de Medidas Para Facilitar la Navegaciµn
AÕrea se recoge la necesidad de que los Estados en donde ocurra un accidente
abran una encuesta sobre las circunstancias del mismo, ajustÃndose en la medida
que lo permitan sus leyes, a los procedimientos que pueda recomendar la
organizaciµn de Aviaciµn Civil Internacional. Entre las distintas funciones del Consejo, que se establece
como µrgano permanente responsable ante la Asamblea, de acuerdo con el Art.54
del Convenio, se encuentra la de adoptar normas y mÕtodos recomendados
internacionales que se realizarÃn en forma de Anexos al Convenio de Chicago,
notificando a todos los Estados contratantes las medidas adoptadas. De acuerdo con esta normativa, el Consejo adoptµ inicialmente
las normas y mÕtodos recomendados para las encuestas de accidentes de aviaciµn
el 11 de Abril de 1951, segºn lo previsto en al Art,37, con la designaciµn de
Anexo 13 al Convenio. Las normas y mÕtodos recomendados se basaron en las
recomendaciones formuladas por el Departamento de Investigaciµn de Accidentes en
su Primera Conferencia, que tuvo lugar en Febrero de 1946, y que posteriormente
se desarrollaron durante la Segunda Conferencia del Departamento, celebrada en
febrero de 1947. La Seguridad de Vuelo està tambiÕn regulada por las Normas
FAR, IATA y actualmente por las Normas JR OPs EL SERVICIO DE SEGURIDAD DE VUELO EN IBERIA. La O.A.C.I considera de suma importancia el concepto de
Seguridad de Vuelo y como consecuencia de la misma recomienda a los Estados
miembros y las CompaþÚas AÕreas la creaciµn de Unidades especializadas en el
tema de la Seguridad de Vuelo. En cumplimiento de esta normativa emanada de la O.A.C.I, la
CompaþÚa Iberia ha desarrollado estas recomendaciones creando la unidad
correspondiente, por medio de un proceso de fusiµn y agrupamiento de otras
unidades ya existentes. El aþo 1962 fue muy importante en la historia de la CompaþÚa
Iberia, debido en gran parte a un gran crecimiento de la empresa a todos los
niveles; por ello la Direcciµn de operaciones, decidiµ la creaciµn de un
Departamento de Seguridad de Vuelo. Las funciones asignadas en un principio, se
limitaron a la prevenciµn de accidentes y a disponer de un equipo que actuara en
caso de tener que realizar alguna investigaciµn, como consecuencia de la posible
ocurrencia de incidentes graves o accidentes. Se estructurµ para poder cumplir
con estas funciones y, teniendo en cuenta la flota activa entonces existente,
constituidas por una flota combinada de aviones de Õmbolo y reactores de los
modelos DC-3, CV-440, Caravelle y DC-8. Como curiosidad y para darnos cuenta del trabajo que tenÚan
que desarrollar vanos a repasar algunos datos correspondientes a la Õpoca.
Durante el aþo 1.964 eran los siguientes; Iberia tenÚa 49 aeropuertos de
destino, empleando para ello 61 aviones que contaban a su vez con 324
tripulantes tÕcnicos, realizando con estos medios 55.047 vuelos que completaban
un total de 107.607 horas de vuelo. Un aþo mÃs tarde en el 1.965 Iberia operµ en
51 aeropuertos con 57 aviones, y con 341 tripulantes tÕcnicos se realizaron
65.634 vuelos. empleando en los mismos 126.086 horas. En el aþo 1.966 se operµ sobre 48 aeropuertos, con 50
aviones, aumentando los tripulantes a 499, el nºmero de vuelos realizados 65.813
y las horas 124.548. Durante el aþo 1.967 los destinos fueron 63, los aviones 62
las tripulaciones fueron aumentando hasta 554 y los vuelos descendieron a
59.053, haciÕndolo las horas de vuelo en 110.175. En el aþo 1.968, 76 destinos
fueron cubiertos con 76 aviones, continuando en aumento el nºmero de tripulantes
hasta los 616, los vuelos subieron a 79.511 y las horas a 149.851, al mismo
tiempo el personal de Tierra del Departamento aumentµ a 4 y el espacio
disponible a 55 m. Durante el aþo 1.969 se volaron a 74 aeropuertos, empleando
78 aviones con 682 tripulantes, los vuelos aumentaron a 96.326 y las horas lo
hicieron a 185.019. En la actualidad la Subdirecciµn de Seguridad de Vuelo cuenta
en su nµmina con 12 personas. Con ellas mantiene tres Divisiones, una Revista,
un Suplemento de Seguridad de vuelo mensual y varios programas de prevenciµn de
accidentes asÚ como el estudio de otros programas que pueden ser interesantes su
puesta en marcha, relaciones con organismos nacionales e internacionales, y todo
ello con un esquema sencillo de organizaciµn, de bajo coste operativo y basado
en interacciones y sacrificios personales. En cuanto a la situaciµn en el entorno en que ha tenido que
trabajar la Seguridad AÕrea a lo largo de los aþos, se ha llevado a cabo bajo un
clima duro, difÚcil y en medio de una gran incomprensiµn; que han soportado sus
componentes con grandes dosis de esperanza y de lucha continua, hasta conseguir
los objetivos. Basta con el siguiente ejemplo ilustrativo de lo expuesto que
serÚa un fiel resumen. Con fecha 6 de Abril de 1.979 y tras estudios sobre la
idea, se decide y ordena mediante escrito a la unidad correspondiente, la
colocaciµn de un buzµn en el aeropuerto de Barajas para su empleo por los
tripulantes exclusivamente para fines de seguridad de Vuelo. En el Acta de la 38
reuniµn de Seguridad de Vuelo, con fecha 12 de Julio de 1.984, se expresa en su
punto 3.-D-c, la necesidad de instalaciµn de los buzones, hecho que tuvo lugar,
despuÕs de varias vicisitudes y de forma que parece ser definitiva, en el aþo
1.992. FUNCIONES DEL SERVICIO SEGURIDAD DE VUELO. Vienen explicadas en la normativa legal y son las siguientes: 1.- Supervisar el conjunto de las actuaciones que afectan a
la Seguridad en la operaciµn de vuelo. Promover a travÕs de los canales
adecuados tanto de la Direcciµn de operaciones como de otras Direcciones de la
CompaþÚa, las medidas operativas, de instrucciµn, factores humanos o de otro
tipo que mejoren la seguridad de vuelo. 2.- Realizar y supervisar los programas de prevenciµn de
accidentes e incidentes. 3.- Dirigir y coordinar en la compaþÚa Iberia toda la
polÚtica que en relaciµn a la investigaciµn de accidentes e incidentes
establezcan las Autoridades AeronÃuticas o las Comisiones de Investigaciµn
Oficiales. 4.- Recopilar y analizar informaciµn interna y externa sobre
seguridad de vuelo, y realizar su difusiµn a los tripulantes y demÃs
interesados. 5.- Proponer y supervisar las normas y mÕtodos sobre equipos
y procedimientos de salvamento y emergencia. 6.- Gestionar y controlar los sistemas de AnÃlisis de la
Operaciµn de vuelo con los datos obtenidos de los grabadores de a bordo. 7.- Supervisar el Control de Calidad de la operaciµn de vuelo
en funciµn de lo establecido por la normativa oficial para el Control Global de
las CompaþÚas AÕreas. 8.- Coordinar la polÚtica de seguridad de vuelo con las
Unidades responsables de la misma en las diferentes compaþÚas del Grupo Iberia. 9.- Dirigir y realizar los programas de notificaciµn de
incidentes propio de la CompaþÚa Iberia, y planificar e implantar las Bases de
Datos necesarias al efecto, manteniendo la confidencialidad de las mismas. 10.- Asesorar y representar a la Direcciµn de operaciones en
temas relativos a Seguridad de Vuelo, ante las Autoridades y Organismos pºblicos
y privados, nacionales e internacionales. 11.- Coordinar el funcionamiento del Comite de Seguridad de
Operaciones, (COMSER) desarrollando las funciones de Secretaria. El Jefe del Servicio es miembro de: ComitÕ Asesor de Normalizaciµn de la Operaciµn de Vuelo (CANOPS). ComitÕ de Selecciµn y Formaciµn de Tripulantes TÕcnicos (COSFOTT). ComitÕ de Seguridad (COMSER).
Participa como Jefe de Seguridad de Vuelo de Iberia en los siguientes Organismos
nacionales e internacionales. -. Comite de Accidentes. DGAC. -. Comite de Aviaciµn Civil sobre AIRMISS e incidentes ATS. -. SAFAC. safety Advisory sub- committee. IATA -. ISASI. International Society of Safety Investigators. -. FSF. Flight Safety Foundation. -. AAWG. Airmiss analisys working group. -. BSCE. Bird strike committee Europe. Para la realizaciµn de los cometidos a llevar a cabo, designa
por si mismo, y con aprobaciµn del DTV, los oficiales de Seguridad que considere
adecuados, llevando a cabo esta elecciµn de acuerdo con el perfil que considere
necesario para la misiµn a desarrollar. Los Oficiales de Seguridad son los responsables de llevar a
cabo los estudios sobre los incidentes/accidentes que tienen lugar dentro del
Grupo y realizan un estudio, solos o con la ayuda que se considere necesaria, de
una manera mas profunda y prolija de aquellos accidentes/incidentes que se
consideren importantes para el proceso de Transporte AÕreo del Grupo. Dichos Oficiales, estÃn adscritos a un determinado cometido a
desarrollar con el fin de poder tener una cierta especializaciµn de los temas a
tratar, sin que esto sea µbice para tener un encasillamiento sobre los temas,
todos los Oficiales pueden sustituir en caso necesario a los demÃs. MISIONES DEL SERVICIO. a.- Publicaciµn del BoletÚn de seguridad de Vuelo.
El objeto de esta publicaciµn es dar cumplimiento a la
funciµn de recopilar y analizar informaciµn interna y externa sobre seguridad de
vuelo y divulgarla entre el personal interesado. b.- AnÃlisis de datos de Vuelo. (A.D.R.A.s), El objetivo es el recuperar y procesar los datos de vuelo
recogidos por los registradores de vuelo, definiendo de acuerdo con los
Directores de Operaciones y Jefes de Flota, las excedencias remarcables para su
estudio. Del anÃlisis posterior se extraerÃn las directrices que el Jefe de
Seguridad de Vuelo recomendara a los diferentes organismos implicados en la
operaciµn (Flotas, Instrucciµn, Mantenimiento, Aeropuertos, etc.), para prevenir
accidentes o incidentes, y corregir desviaciones de la operaciµn normal. Esta
misiµn esta cumplimentada la recomendaciµn de IFALPA de la autorizaciµn de los
Comandantes, que se obtiene por vÚa sindical, cuyo protocolo de actuaciµn esta
firmado recientemente. c.- Investigaciµn de Incidentes. Es una funciµn de
investigaciµn y anÃlisis, que comprende diferentes aÕreas de trabajo, que se
asigna a los Oficiales de Seguridad de Vuelo y comprende. .- Servicio de Trafico y Control AÕreo. Todo esto se lleva a cabo mediante: 1.- Recopilaciµn de informes de los pilotos sobre incidentes
ocurridos durante la operaciµn, bien sea por carta o por telÕfono. , 2.- Estudio de los mismos y tramitaciµn de comunicaciones
para ampliar la informaciµn con los organismos implicados (Jefes de Escala,
Directores o Subdirectores de aÕreas implicadas en el incidente, etc). AnÃlisis
con el Jefe del Servicio de todos los incidentes para tomar determinaciones y
efectuar recomendaciones que eviten la repeticiµn de los mismos. d.- Tramitar ante Aviaciµn Civil los incidentes ATS y los
AIRMISS ocurridos a los pilotos de Iberia. e.- Hacer estudios de accidentes e incidentes de otras
compaþÚas para extraer consecuencias que luego transmitirà a los diferentes
departamentos con sugerencias y consejos. f.- Todos los informes se analizan de forma periµdica con el
Jefe de Seguridad de Vuelo, para tomar decisiones. 9- Procesamiento informÃtico: de todos los incidentes ATS y,
tanto de Iberia como de las demÃs compaþÚas para hacer resºmenes estadÚsticos
que se presentan al Jefe de Seguridad de Vuelo y se envÚan luego a diferentes
departamentos interesados. h.- Elaborar estadÚsticas necesarias sobre Úndices de
accidentes e incidentes de la compaþÚa, ponderando dichos Úndices con los que se
producen en la industria en general. À.- Proporcionar a los oficiales de Seguridad el apoyo
necesario para llevar a cabo su gestiµn. j.- Elaborar y controlar la base de datos de accidentes e
incidentes, clasificÃndolos y actualizÃndolos. k.- Elaborar los presupuestos y gastos de inversiµn del
Servicio, efectuando el seguimiento oportuno de la implantaciµn de las
inversiones que se hayan previsto. l.- Apoyar al Jefe de Seguridad en lo referente a temas
econµmicos. m.- Coordinar con otras unidades de la compaþÚa los temas
referentes de su competencia. - PSICOLOGëA AERONêUTICA. Es un Ãrea con grandes posibilidades. Todas las compaþÚas del
entorno e incluso el SubcomitÕ de Seguridad de Vuelo de IATA (SAFAC) hacen
estudios sobre la incidencia de los factores humanos en la operaciµn de vuelo. Las funciones de este Ãrea vienen recogidas de forma global
en el MBO, cuando expone los objetivos de Seguridad de Vuelo. "Promover,
planificar y, en su caso, implantar a travÕs de los canales adecuados las normas
tÕcnicas de seguridad necesarias para la operaciµn de vuelo, y en especial, las
referentes a aspectos de factores humanos." La Asamblea de la OACI, adopto en 1.986 la Resoluciµn A26-9
sobre la Seguridad de Vuelo y los Factores Humanos. En virtud de esa resoluciµn,
la Comisiµn de Aeronavegabilidad formulµ el siguiente objetivo. "Aumentar la
seguridad de la aviaciµn instando a los Estados a que se muestren mas
conscientes y atentos a la importancia del factor humano en las operaciones de
aviaciµn civil, adoptando textos y medidas practicas en relaciµn al factor
humano, elaborados a partir de la experiencia adquirida por los Estados." .- Las funciones previstas son: 1.- Realizar programas de investigaciµn, tanto
cuantitativamente como cualitativamente, sobre la incidencia de la actuaciµn del
personal de vuelo en la operaciµn. 2.- Colaborar con la Subdirecciµn de Instrucciµn en el
desarrollo de programas de formaciµn en factores humanos para tripulantes
tÕcnicos, siguiendo las recomendaciones de OACI, resoluciµn A26-9 sobre la
Seguridad de Vuelo y los factores humanos. 3.- Desarrollar un programa de investigaciµn de la incidencia
que han tenido los factores humanos en accidentes e incidentes a travÕs de la
informaciµn recibida y procesada por Seguridad de Vuelo. 4.- Divulgar a travÕs del BoletÚn de S.V. informaciµn,
recomendaciones y criterios homogÕneos de actuaciµn en cabina, que pudieran
derivarse del anÃlisis de la realidad del tripulante y de la casuÚstica de
accidente/incidentes. 5.- Hacer estudios y preparar programas para tratar de
,solucionar de la mejor manera posible, el problema de los hÃbitos como
tabaquismo, alcoholismo, drogadicciµn, depresiones, etc. en los tripulantes,
buscando y negociando con la Direcciµn, en colaboraciµn con el Servicio mÕdico,
vÚas de reinserciµn y cura !e los afectados, en aras de proteger la seguridad de
vuelo. 6.- Asesorar en la creaciµn de equipos o grupos de trabajo
por tiempo determinado, para el estudio de temas concretos sobre seguridad de
vuelo y que por su complejidad no puedan ser abordados por los componentes del
Servicio de Seguridad de Vuelo. 7.- Comprobar que los programas de instrucciµn, formaciµn,
refrescos, salvamento, etc, se adecuan a las normas emanadas de los organismos
competentes, nacionales e internacionales sobre seguridad de vuelo y factores
humanos. - REVISIÆN - NORMAS. Con esta Ãrea se da contenido a las determinaciones del MBO
(Manual BÃsico de Operaciones) en cuanto a sus responsabilidades: .- "Promover, planificar, implantar a travÕs de los canales adecuados, las
normas tÕcnicas de seguridad necesarias... " .- "Supervisar el conjunto de actuaciones que afectan a la operaciµn de
vuelo..." . - " Estudiar y proponer las normas y procedimientos sobre equipos y
actuaciones de salvamento y emergencia." .- Y a ellos hay que incluir las revisiµn de las normas que emanen de los
diferentes departamentos de la CompaþÚa que tengan incidencia directa o
indirecta con la operaciµn de vuelo para: 1. Detectar desviaciones de la operaciµn normal que pueden afectar a la
seguridad de vuelo. 2. Tratar de conseguir una identidad de criterios evitando la inseguridad que
puede derivar de la dispersiµn de normas que ahora existen. - BIBLIOTECA y DOCUMENTACIÆN. Mantiene al dÚa toda la documentaciµn del Servicio, haciendo
la recepciµn y estudio de toda la documentaciµn que llega de la CompaþÚa y de
todos los organismos nacionales e internacionales, clasificando los que tienen
interÕs para Seguridad de Vuelo. Mantiene un archivo informÃtico de todos los documentos de
interÕs, que luego distribuye entre las personas interesadas, como manda el MBO.
" Recopilar y analizar informaciµn interna y externa a la compaþÚa sobre
seguridad de vuelo, divulgÃndola entre el personal interesado." Mantiene una biblioteca sobre materias se seguridad de vuelo
a disposiciµn de los tripulantes para su lectura y toma de datos para trabajos o
estudios sobre seguridad.
OPCIONES DE TRABAJO A DESARROLLAR EN SEGURIDAD EN VUELO CON
RELACIÆN A LA FUNCIÆN ESPECIFICA DE PSICOLOGëA Y FACTORES HUMANOS.
El Manual BÃsico de operaciones de Vuelo (M.B.O. 2.30/7), seþala al Servicio de
Seguridad en Vuelo como primera funciµn la siguiente: "Promover, planificar, y
en su caso implantar a travÕs de los canales adecuados las normas tÕcnicas de
seguridad necesarias para la operaciµn de vuelo y en especial las referentes a
aspectos de Factores Humanos" Es en base a esta normativa por lo que se ha
formado el Staff de PsicologÚa AeronÃutica, dentro del Servicio de Seguridad en
Vuelo. Toda Empresa esta formada bÃsicamente por cuatro grandes
êreas o Recursos (Materiales, Econµmicos, TÕcnicos y Humanos), todos ellos
interrelacionan entre si al objeto de conseguir el producto que ofrece a sus
usuarios, procurando bÃsicamente que sea ºtil y atractivo para el cliente, asÚ
como rentable econµmicamente para la Empresa. En el caso de una CompaþÚa de
Transporte AÕreo, lµgicamente hay que aþadir un nuevo factor al producto, el de
la Seguridad. Para cumplir con este reto se crean los Servicios de Seguridad de
Vuelo, que lµgicamente deben tener funcionalidad para poder cumplir con sus
objetivos. De las cuatro êreas o Recursos, quizÃs la mas dÕbil y
descuidada es la de los Recursos Humanos, no obstante tienen un papel
fundamental en la relaciµn final de captaciµn de beneficios econµmicos. ¢Como se
puede evaluar las perdidas ocasionadas por un accidente/incidente ?. De forma
primaria o inmediata con la perdida de las personas y del material, y de forma
secundaria con la perdida de la confianza por el usuario. ¢Como se pueden evaluar las perdidas econµmicas derivadas por
un uso no adecuado o incorrecto de los medios que se proporcionan a los
tripulantes?. No cabe duda de que los beneficios o perdidas de esta êrea
Humana, tiene una importancia vital en la cuenta final de beneficios de una
Empresa, por esta razµn no vamos a insistir en la importancia econµmica de este
Staff de PsicologÚa y Factores Humanos incluidos en el Servicio de Seguridad en
Vuelo. Para poder incidir sobre el êrea de Recursos Humanos, se
recurre a los estudios Ergonµmicos, o como tambiÕn se le conoce de forma no del
todo correcta en los medios aeronÃuticos; Factores Humanos. Su definiciµn mas
simple seria la ciencia de adaptar los puestos de trabajo a las personas que los
desempeþan, o bien el de formar adecuadamente al trabajador para que pueda
desarrollar su trabajo en las mejores condiciones. Por otra parte es caro el
conseguir la correcta puesta a punto de un tripulante, por lo que egoÚstamente,
se debe mantener en las mejores condiciones, para que su rendimiento sea el
adecuado. El êrea de los Recursos Humanos, es actualmente la cenicienta
y la que se ha quedado bastante rezagada en el Transporte AÕreo. Los recursos econµmicos empleados son cuantiosos, los
materiales usados en la cadena de producciµn y las tÕcnicas empleadas estÃn en
vanguardia de la industria en general, pero en cuanto a las personas no han
evolucionado, al contrario la dinÃmica de la nueva vida les ha creado nuevas
tensiones, que no logran mejorar su rendimiento, al incidir sobre sus factores
psicofisiolµgicos, causando ademÃs perdidas cuantiosas en las Empresas de
Transporte AÕreo. Por esta razµn; la O.A.C.I., ante la importancia de los
Factores Humanos, intenta potenciarlos, y asÚ en la Octava Ediciµn del Anexo I
de la O.A.C.I. referente a las Licencias al Personal, con aplicaciµn al 1 de
Noviembre de 1.989, introduce el requisito de la formaciµn en Factores Humanos
en la Instrucciµn de los Pilotos. Para ello el Grupo de Estudio de la O.A.C.I.
sobre la Seguridad en Vuelo y los Factores Humanos ha elaborado la Circular 227-AN/136:
Instrucciµn del Personal Operacional en Factores Humanos. La Circular 216-AN/136:
Conceptos fundamentales en materia de Factores Humanos. La Circular 217-AN/132:
Formaciµn de las Tripulaciones de Vuelo: Gestiµn de los Recursos en el Puesto de
Pilotaje. TambiÕn tiene en preparaciµn otras tres Circulares sobre el tema y que
se refieren a: a) Formaciµn del Personal de Operaciones en lo que ataþe a su
actuaciµn y limitaciones. La necesidad del establecimiento del programa de los Factores
Humanos por la O.A.C.I. fue decidido muy recientemente, en el aþo 1.986, durante
el 26 PerÚodo de Sesiones de la Asamblea en la que se aprobµ la Resoluciµn A26-9
sobre la Seguridad en Vuelo y los Factores Humanos. ¢Ante un nuevo enfoque de la Seguridad en Vuelo, y que ademÃs
no representa un coste econµmico elevado, seria lµgico que no nos subiÕramos al
tren del progreso y nos quedÃramos en el anden? ¢Que personal seria necesario para dicho Staff ?. La Circular
O.A.C.I. 216-AN/131, habla sobre este tema, asÚ como su nivel de pericia. En el
capitulo 4, vemos que el Nivel 3: Especialista Interno, " Serà necesario que el
especialista tenga estrecha relaciµn con las actividades de vuelo si ha de
trabajar eficazmente y con credibilidad problemas operacionales". TambiÕn afirma
sobre el nivel 4: Consultor sobre Factores Humanos. "El Consultor debe poseerÃ
un Diploma acadÕmico superior en PsicologÚa, con orientaciµn hacia una rama de
los Factores Humanos". A continuaciµn y en la misma pÃgina 26, enumera la
relaciµn de cursos disponibles. Entre las mºltiples aplicaciones de este Staff, serÚan de
destacar las siguientes: 1) Dar cumplimiento a lo indicado en el M.B.O. 2.70 pÃrrafo
1. 2) El Staff de PsicologÚa /Factores Humanos, formado por
profesionales con conocimientos y curriculum adecuados, asesorarÚan o
representarÚan por delegaciµn al Jefe de Seguridad en Vuelo y aquellos
estamentos de la Empresa que asÚ lo requirieran para su funcionamiento, con
relaciµn a actos, reuniones, coloquios, informes y estudios sobre el tema,
dentro de la Empresa, o bien en Ãmbito nacional o internacional. 3 ) Llevar a cabo y supervisar programas de prevenciµn de
accidentes/incidentes relativos a los Factores Humanos, en todo cuanto se
refiera a la Seguridad en vuelo. 4 ) Llevar a cabo programas de investigaciµn en sus
vertientes cuantitativa y cualitativa sobre la incidencia de la actuaciµn Àel
personal de vuelo en relaciµn con la operaciµn, a travÕs de Informes o mejor
autoinformes recibidos. 5) Participar dentro del Servicio de Seguridad en Vuelo en la
divulgaciµn, informaciones o recomendaciones sobre la actuaciµn de las
tripulaciones dentro de su trabajo. 6 ) Comprobar que los programas de instrucciµn, formaciµn,
refrescos, salvamento, etc, se adecuen a las normas emanadas de los organismos
competentes, nacionales o internacionales, sobre la Seguridad en Vuelo. 7 ) Colaborar y solicitar ayuda de los distintos
departamentos de la CompaþÚa, sobre problemas psicolµgicos que afecten a los
tripulantes (adicciones, problemas emocionales etc.), que pueden incidir sobre
la Seguridad en Vuelo, al objeto de darles la mejor soluciµn posible. 8) Asesorar, cuando proceda, sobre la creaciµn de equipos o
grupos de trabajo para el estudio de temas concretos y en tiempo prefijado de
actuaciµn, y que afecten a temas concretos de Seguridad de vuelo y que por
complejidad no puedan ser abordados por los componentes del Servicio de
Seguridad de Vuelo. 9 ) Todos aquellos que la CompaþÚa crea necesario se lleven a
cabo en el êrea PsicologÚa /Factores Humanos. Articulo Octubre 2013
PENSAMIENTOS PSICOLÆGICOS ACERCA DE LA LISTA DE COMPROBACIÆN.-
Una lista de comprobaciµn realizada en un aviµn con un solo tripulante, es en
realidad un monologo. Si este aviµn lleva dos tripulantes, se convierte en un
dialogo. Cuando los tripulantes son tres, la lista es un verdadero conflicto, y
cuando el nºmero
de tripulantes se incrementa, se convierte en la lectura de un bando o pregµn.
No vamos a entrar en discusiµn sobre la forma de realizarla, sino como nuestro
encabezamiento indica, solamente haremos unas reflexiones sobre la forma en que
se realiza, dÃndolo como la mejor forma de hacerlo, segºn las normas al
respecto.
El estudio que vamos a realizar no es de tipo ergonµmico, nombre moderno de esta
disciplina encuadrada dentro de la PsicologÚa del Trabajo y que ha recibido
primitivamente los nombres de IngenierÚa de los Factores Humanos, Factores
Humanos, BiomecÃnica y tambiÕn el de PsicologÚa de la IngenierÚa, y que le
define McCormick como "los objetivos
de los factores humanos que estriban en conseguir una efectividad funcional de
cualquier equipamiento o ayuda fÚsica que utilice la gente, y en mantener y
mejorar el bienestar humano (salud, seguridad y satisfacciµn) mediante un
apropiado diseþo de implementos, ayudas y entornos", Estudio que realizaremos a
su debido tiempo. El enfoque que vamos a dar esta de acuerdo con los principios
clÃsicos de la PsicologÚa Social.
Veamos someramente el modelo de campo de energÚa sobre el hacinamiento postulado
por Knowles, basado en los modelos gravitacionales de Newton. Afirma que las
fuerzas de interacciµn entre dos unidades de poblaciµn eran directamente
proporcionales al producto de sus tamaþos, e inversamente proporcional a las
distancias entre ellas al cuadrado, y a su vez multiplicada por una constante,
tenemos ∑E S =
K(Ms.Mi>) / (Dd.Si) K es una constante Podemos generalizar esta fµrmula de energÚa interpersonal a un sujeto y todos
aquellos sujetos que existen a su alrededor en el espacio
E S K.Ms.∑ni=1
(Mi) / (Dd.Si) En esta formula existen tres variables distintas: Masas de las personas, la
cantidad de sujetos y la distancia entre las personas y el sujete estudio. La cuantificaciµn o mediciµn es
fÃcil de determinar con las variables cantidades, sujetos y distancia, no siendo tan
fÃcil de determinar en cuanto a la masa social del sujeto La masa social en nuestro caso (es equivalente segºn Knowles a tamaþo social),
viene determinada por peso social, poder e importancia. En una tripulaciµn,
aparte de las diferencias individuales existentes entre los individuos, que son
fuertes en muchos casos, serÚa relativamente
fÃcil determinar, ya que loe roles de cada tripulante (mando, responsabilidades,
etc.) son o deben ser fijos e inmutables y por lo tanto fÃciles de cuantificar. Una tripulaciµn tÚpica
toma, en forma bÃsica, dos tipos de disposiciones en sus puestos de trabajo.
Durante el trabajo en operaciµn normal, la disposiciµn es en forma de triÃngulo
rectÃngulo, cuya diagonal està determinada por el Comandante y el OT/V, podemos
afirmas que el centro es el Segundo Piloto (es la distancia mÃs corta para el
Comandante y asimismo para el OT/V). La segunda disposiciµn
que se puede observar es la de lÚnea, estÃn los tres hombres en una disposiciµn
que se asemeja a una lÚnea recta y con la mirada hacia el frente. En esta
disposiciµn podemos decir que el OT/V ha "quitado" el centro al Segundo Piloto.
Esta disposiciµn es mÃs "agresiva" que la anterior. las comunicaciones son mÃs
rÃpidas v efectivas y las acciones siguen la. misma suerte que las
comunicaciones, en otro momento hablaremos sobre las redes de comunicaciµn. La masa social de un
individuo, ademÃs de de lo expresado por Knowles, como una combinaciµn de antena
de cuadro y de direcciµn, de tal forma que la radiaciµn tiene la forma de una
cardiode, siendo la parte frontal la de mayor radiaciµn.
La
fµrmula anterior vendrÚa influida por una constante que podemos llamar de
situaciµn a
(alfa) y que dependerà del Ãngulo relativo de las masas. Para una persona. determinada y en un momento fijado, podrÚamos saber con bastante precisiµn el
valor de esta constante, pasando al individuo en cuestiµn un test de atenciµn. Lµgicamente esta variable serà distinta para cada individuo y dentro del mismo
variarà de acuerdo con el estado emocional del mismo. Merton y Deustch en sus
estudios acerca de la cooperaciµn y competiciµn entre grupos, define la situaciµn cooperativa como aquella en la. que los objetivos de los individuos
participantes se relacionan de tal manera, que cada uno puede alcanzar su meta si, y solo si los otros logran alcanzar las suyas. El Õxito depende de la
eficacia del miembro menos competente. Una tripulaciµn es un equipo, en el que cada
miembro tiene una misiµn determinada y especifica que cumplir. la eficacia y el Õxito de esta misiµn està determinada por la ejecuciµn de la misma por el
miembro menos calificado. la misiµn del mÃs
inteligente y capaz no es la de su endiosamiento, subiÕndose al pedestal, sino
la mas complicada y difÚcil, de ademÃs de cumplir con satisfacciµn con su
misiµn, ayudar, sin interferir, en la consecuciµn de las tareas de los demÃs. DespuÕs de haber
establecido estas premisas, podemos pensar lo siguiente. En la realizaciµn de la
Lista de Comprobaciµn existen dos momentos diferentes, ambos son importantes. El
AOM cita de forma implÚcita y explicita, que se adopte la posiciµn " en lÚnea"
de cara a la direcciµn de actuaciµn y que obviamente es la postura de mayor
aprovechamiento.. En una que podemos definir como actuaciones
sobre el aviµn, el centro se desplaza hacia el Segundo piloto, que es el
encargado de leer, mientras que la misiµn de los otros miembros de la
tripulaciµn actºan. La segunda el centro de actuaciµn se
desplaza hacia el OTV, y la podemos definir como de actuaciµn sobre la maniobra,
quedÃndose libre el segundo piloto para actuar, y equilibrando la masa de 1a
tripulaciµn, al centrarla sobre el OTY. Conclusiones: El comandante es siempre
una pieza vital en el equipo o tripulaci6n, siempre ejecuta o participa
activamente en las operaciones. El segundo piloto, aunque
participa en todas las operaciones (como toda la tripulaciµn). Su acciµn es
importante en las actuaciones del aviµn (aproximaciones, despegues, rodajes,
etc.). El OTV (o la persona que
ejerce este puesto), es esencialmente mÃs importante en aquellas operaciones de
actuaciµn sobre los equipos (puesta en marcha, paradas de motor, emergencias,
etc.). Todo ello desde un punto
de vista psicolµgico. Articulo Septiembre 2013
ALGUNOS ESBOZOS SOBRE PSICOLOGëA SOCIAL Aproximaciones a la PsicologÚa Ecolµgica y las relaciones y composiciµn de una
Tripulaciµn de Largo Recorrido. No hace mucho tiempo oÚ decir a un radionavegante lo siguiente " el radio era el
equilibrio ecolµgico de una tripulaciµn transoceÃnica". Me eche a reÚr, considerÃndolo coso una buena ocurrencia baturra. la desapariciµn paulatina de
loa mismos ha producido, sin embargo. un desequilibrio o disonancia en las tripulaciones. Para reducir o
eliminar la disonancia existen tres formas o modos de reducciµn:
1) cambiando de conducta. 2) alterando el ambiente y 3) aþadiendo nuevas
informaciones y conocimientos que reduzcan la disonancia. En este caso se ha recurrido al primer caso; se ha sustituido el elemento que
faltaba por otro nuevo. Procedimiento: duplicar un miembro o tripulante, ya existente, y que dicho individuo asuma las funciones
del desaparecido. Consecuencias: ha desaparecido el desequilibrio existente, de acuerdo con las leyes de disonancia.
Pero ha surgido otro nuevo factor en las relaciones de la tripulaciµn, la Sobresaturaciµn del Escenario de Conducta.
Veamos ahora algunas connotaciones de la PsicologÚa Ambiental, la conducta humana se desarrolla de una forma necesaria y obligatoria en en entorno
ambiental, esta premisa ha sido causa de mºltiples explicaciones dentro de la Historia del Pensamiento. Por desgracia la PsicologÚa CientÚfica ha tardado en
incorporarse a la problemÃtica ambiental. Uno de loa trabajos pioneros en
este <rea se remonta solamente al aþo 1.961, en el que tiene lugar en Texas un Simposio sobre los " Aspectos psicofisiologicos de los vuelos espaciales ".
Durante el aþo 1.962 publica Gorbou sus trabajos sobre PsicologÚa del Espacio. El bagaje teµrico es por tanto bastante reducido.
Entre las orientaciones teµricas de la PsicologÚa Ambiental nos encontramos con el modelo de la PsicologÚa Ecolµgica, la orientaciµn es debida a R.G. Harker y
colaboradores y se deaarro a partir del aþo 1.965. Es por lo tanto una orientaciµn teµrica moderna y cuya cima no ha sido alcanzada todavÚa. Un
colaborador Wicker he. definido la PsicologÚa Ecolµgica de la siguiente forma " Estudio de las relaciones interdependientes entre las acciones de la persona
dirigidas a una meta y los escenarios de conducta en que tales acciones acontecen". Se denomina Escenario
de Conducta a la interdependencia entre el Ambiente y la Conducta. El Escenario de Conducta contiene oportunidades y es el lugar, segºn Barker, donde sus
ocupantes pueden conseguir satisfacciones mºltiples y satisfacer un nºmero de motivos personales. En nuestro caso la satisfacciµn profesional, derivada de la
buena ejecuciµn del trabajo a desarrollar como tripulaciµn , ahorro de combustible, reducciµn del tiempo de vuelo, elevada tasa de seguridad en todas
las operaciones, etc. Programa del Escenario, lo define Wicker como " Sistema limitado autorregulado y
ordenado, compuesto de elementos humanos y no humanos, reemplazables y que interactºan de modo sincronizado para ejecutar una secuencia ordenada de
acontecimientos que recibe el nombre de Programa de Escenario. Entre las caracterÚsticas de los Escenarios se encuentran:
Poseen componentes humanos y no humanos, aunque son las personas el medio esencial del funcionamiento, sin
embargo los individuos son intercambiables dentro de los Escenarios ( en nuestro caso la cabina de mando).
Los Escenarios dependen de un nºmero mÚnimo de personas para realizar su programa.
Recibe el nombre de
Infrasaturaciµn a la escasez de personas suficientes para realizar eficazmente el Programa y el mantenimiento del Escenario.
Saturaciµn µptima, significa que el nºmero de personas es el adecuado para operar y mantenerlo en los niveles mas
efectivos. Recibe el nombre de Sobresaturaciµn cuando el nºmero de personas excede a las necesarias para la
ejecuci6n del Programa del Escenario. La Saturaciµn del Escenario depende de varios factores:
1) Nºmero de aspirantes, cantidad de personas que desean participar simultÃneamente y que el propio
escenario impone sus dificultades, en nuestro caso serÚa la tripulaciµn tÚpica necesaria para la operaciµn del aviµn con seguridad. Obviamente los demÃs
participantes, al no tener un puesto adecuado de trabajo, no harÚan otra cosa que interferir en el mismo. 2)
MÚnimo de mantenimiento, es la cantidad mÚnima de personas necesarias para sostener el programa, en nuestro caso, con una tripulaciµn muy bien entrenada,
podrÚa ser esta cantidad una sola persona, el comandante del aviµn, pero teniendo en cuenta factores como seguridad en vuelo ( todos los elementos
importantes de mando van como mÚnimo duplicados ) harÚa falta tambiÕn un segundo piloto; multiplicidad, de equipos y sistemas a los que vigilar y mantener en
posiciµn correcta, un mecÃnico de vuelo es necesario para descargar la responsabilidad y aumentar la eficacia y seguridad del vuelo,
3) Capacidad del escenario, cantidad de personas que puede admitir manteniendo todavÚa eficazmente su Programa, depende exclusivamente del diseþo
de la cabina del aviµn. Resumiendo, el grado de saturaciµn de saturaciµn se debe determinar de forma sepada por dos tipos de
ocupantes, segºn proponen McGrath y Wicker, los trabajadores (responsables de operar y mantener el programa) y los que no tienen estas responsabilidades
dentro del escenario, (aunque si el diseþo y programaciµn de dicho Escenario de Conducta). Dentro de los trabajadores cada especialidad debe determinar su grado
de saturaciµn es decir, los comandantes solamente su propio grado, los segundos pilotos el suyo y los mecÃnicos y radionavegante, si procediera, los
propios, sin que exista ningºn cruza miento en los papeles, que no conducirÚan si no a un sesgamiento del problema para conseguir un logro o mejora en el
status propio de un individuo o grupo de individuos aumentando, por el contrario, los problemas al introducir nuevos factores ajenos al problema.
Estos mismos autores predicen que a nivel de trabajador , la Sobresaturaciµn darÚa como consecuencia lo siguiente:
Ejecuciµn negligente de las tareas, con el peligro que esto tiene en cuanto seguridad y operatividad del sistema, el aviµn en nuestro caso.
Un alto grado de especializaci6n en las actividades del escenario, estando celosos los individuos por mantener sus propios dominios y status profesional,
disminuyendo el espÚritu de cooperaciµn y equipo necesario para una buena tripulaciµn. Disminuciµn y escaso
interÕs entre los actores acerca de la calidad del Escenario como un todo o unidad, extrapolÃndolo al aviµn esto acarrearÚa consecuencias funestas.
Pocos esfuerzos de los trabajadores por cooperar con los otros, rompiendo el espÚritu de equipo y
tripulaciµn. Las conversaciones en el Escenario giraran sobre las personalidades y modos de ser de los demÃs
actores del Escenario, mÃs que sobre los aspectos relacionados con las actividades aeronÃuticas. Se
producirÃn unas actitudes cÚnicas de los participantes respecto al Escenario y las funciones del mismo. Una
relativa baja autoestima, con poco sentido de la competencia profesional.
Podemos resumir este pequeþo trabajo de una forma un poco mÃs clara y menos profesional en la forma siguientes:
Para evitar la Sobresaturaciµn y todos los efectos negativos de la misma, la tripulaciµn de un aviµn de largo recorrido debe ser la especificada por las
Normas de Navegabilidad del Aviµn (realizadas por el fabricante del aviµn y aprobadas por las Autoridades AeronÃuticas competentes, llevadas a cabo con
estudios profundos en la materia). BasÃndose en la caracterÚstica de intercambiabilidad de los elementos humanos en
el Escenario de Conducta (cabina de mando) se puede lograr una mejora en la operatividad y seguridad del aviµn, sustituyendo cualquier miembro que se
suponga està cansado por otro de refresco. Pero para evitar la sobresaturaciµn. estos miembros deben estar fuera del Escenario de Conducta (cabina de mando) y
situados en una zona adecuada para el descanso y cercana al Escenario de Conducta, al objeto de ser sustituidos de una forma fÃcil y rÃpida cuando asÚ
sea requerido. Cualquier permanencia de un miembro extra de la tripulaciµn en la cabina de mando nos producirÚa sin remedio
alguno una Sobresaturaciµn en la operaciµn o un doblaje innecesario del tripulante, con las consecuentes circunstancias negativas, aumento del coste de
la operaciµn y no conseguir aumentar la seguridad de vuelo.
BIBLIOGRAFIA. - Apuntes para una tesina de Licenciatura en PsicologÚa Industrial.- del mismo autor.
8arker,R.G: Ecological Psycholgy: Stanford University Presa, 1.968. Edwin E. Ghiselli,
Psicologia Industrial..- Universidad de California. Edwin E. Ghiselli New ideas in industrial
psychology. J. Appl. Peychol. 1.951 Craxford. M. P: Psychol. Reseach on Operational Training in the Continental A.F. 1.947
Jimenez Burillo F. Psicologia y Medio Ambiente. MOPU. 1.981. Thorndike. E. L The Personal Systen of
the United States Army, Wicker, A. W An intrnduction to Ecological Psychology. Brooke/Cole Publis, California Articulo Agosto 2013 TRABAJO Y MOTIVACIÆN, UN TEMA PARA CONVENIO
El trabajo viene definido por el diccionario como el esfuerzo humano aplicado a la producciµn de riqueza, y la motivaciµn como la causa o razµn que mueve para
una cosa. En el diccionario de PsicologÚa de Arnold-Eysenck, tomo 3, PÃg. 475, el trabajo lo define como: ¨Una
actividad ocupacional realizada a cambio de una recompensa£. La motivaciµn, en la misma obra, tomo 2, PÃg. 367, no es tan concisa y su extensiµn es acorde con
la gran cantidad de teorÚas y formas de motivaciµn. ¨Uno de las procesos implicado en la determinaciµn de la conducta£. ¨La motivaciµn determina la
direcciµn hacia un objeto determinado£. ¨Es un factor de activaciµn£. El trabajo (Ombredame y Faverge, 1955) es ¨un complemento adquirido por
aprendizaje y que debe adaptarse a las exigencias de una tarea£ (Leplat y Cuny, 1977). ¨ Las exigencias varÚan notablemente segºn el nivel tÕcnico
socioeconµmico de la organizaciµn en la cual se inserta la tarea£. El estudio del trabajo se debe realizar dentro de unos variados marcos de referencia. El
trabajador està inserto dentro de un sistema tÕcnico hombre-mÃquina y en el puesto que ocupa contribuye al funcionamiento del sistema, es necesario un
estudio de este entorno tÕcnico. El trabajador, como miembro de grupos formales e informales, està inserto en organizaciones variadas (tripulaciµn, flota,
empresa, grupo profesional, sindicatos, etc.), por lo que es necesario tener en cuenta las relaciones y comunicaciones en estos variados contextos. Pero, para
no extendernos demasiado en la conceptualizaciµn del trabajo, definÃmoslo simplemente como el comportamiento de los individuos que participan en una
actividad de producciµn o bien como la funciµn atribuida a Õstos. ALGUNAS DEFINICIONES La
organizaciµn la define Lawrence (1969) como ¨coordinaciµn de actividades diferentes de colaboradores individuales para llevar a cabo transacciones
planeadas con el ambiente£. Una organizaciµn es una necesidad humana, creada para poder encarar el ambiente y poder encontrar soluciones para los problemas
ambientales con que se enfrentan; por lo tanto, la organizaciµn no tiene un objetivo, Õste solamente lo tienen las personas; en nuestro caso, es el
transporte aÕreo. La organizaciµn solamente adopta una estrategia planeada, la del transporte aÕreo, que, en realidad, significa la contribuciµn de personas
que han tomado la decisiµn comºn de trabajar de manera coordinada alrededor de la estrategia del transporte aÕreo, mediante ¨la realizaciµn de actividades
diferentes£ (pilotaje, ingenierÚa, relaciones pºblicas, direcciµn, marketing, etc.). Al objeto de poder cumplir
con su funciµn, la organizaciµn debe tener inexcusablemente una ¨coordinaciµn£ asÚ como ¨mecanismos de comunicaciµn£ y ¨toma de decisiones£.
La organizaciµn, para ser efectiva, tiene que funcionar de una forma bidireccional, entre los colaboradores individuales -organizaciµn (divisiµn del
trabajo y coordinaciµn)- medio ambiente. Veamos cµmo funciona este esquema. Los colaboradores individuales de la empresa (personal de vuelo,
comercial, etc.), a travÕs de la organizaciµn, ofertan un tipo de transporte aÕreo; cuando estas transacciones con el ambiente son favorables, se cumplen los
impulsos o propµsitos de los colaboradores individuales. La direcciµn contraria tambiÕn es muy importante; el medio ambiente detecta una necesidad de transporte
aÕreo que se traslada a la organizaciµn, que, a su vez lo hace a los colaboradores individuales que ¨adaptan su capacidad de trabajo£ para lograr el
adecuado cumplimiento de estos fines de transporte aÕreo, que son suyos, y no de la organizaciµn, cuyo fin es la ¨divisiµn y coordinaciµn del trabajo£.
Uno de los muchos problemas que surgen en la organizaciµn, y que no vamos a enumerar por no salirnos del tÚtulo, es el problema que se presenta a los
gerentes de la organizaciµn en cµmo inducir a los colaboradores individuales para que ejecuten las actividades asignadas. Cµmo emplear la ¨motivaciµn£ para
que los colaboradores individuales contribuyan al logro de los objetivos de transporte aÕreo, y tambiÕn cµmo canalizar y controlar la conducta de los
colaboradores individuales en la direcciµn deseada. Anejo a estos problemas se presentan a la gerencia otro no menos grave: hallar la forma mÃs efectiva de
comunicar a los colaboradores individuales las metas de la organizaciµn de tal forma que estas metas y las necesidades de los individuos sean complementarias
y, en caso de no serlo, por lo menos que no sean antagµnicas. Es, por lo tanto, bÃsico y fundamental por parte de la gerencia el dar primacÚa a la consecuciµn
de las metas de transporte aÕreo de la organizaciµn y debe motivar y controlar a los colaboradores individuales para que realicen, de forma efectiva, actividades
especializadas y coordinadas. ACERCA DE LA MOTIVACIÆN Revisemos ahora algunas teorÚas de la motivaciµn de los individuos para que
contribuyan a las metas de la organizaciµn y los contratos psicolµgicos entre la organizaciµn y el individuo: 1.
Schein. El hombre es un ser econµmicamente racional, esto significa que està motivado por recompensas econµmicas, que son controladas por la Organizaciµn. El
contrato psicolµgico es sencillo; esfuerzo a cambio de dinero. Las relaciones hombres-trabajo y hombre-hombre o con la misma organizaciµn son irracionales y
egoÚstas. La organizaciµn, para impedir que estas actitudes y sentimientos influyan negativamente sobre el diseþo de la organizaciµn y mediante
procedimientos administrativos, para inducir a los colaboradores individuales a trabajar por las metas organizacionales, pero olvidan las necesidades humanas.
2. Elton Mayo insiste en las necesidades sociales del hombre; la motivaciµn bÃsica para que trabajen los individuos se basa en la necesidad de pertenencia
(necesidad de relaciones cÃlidas, amistosas y comprensivas con otros) y de acuerdo con Õsta los individuos prefieran que la organizaciµn asegure la
satisfacciµn de las necesidades sociales a cambio del esfuerzo, como un resultado de la racionalizaciµn del trabajo. La gerencia, en este caso, necesita
reconocer la existencia de grupos de compaþeros y, en el caso de que las expectativas de los grupos no respalden las metas de la organizaciµn, debe
procurar que se adapten por medio de recompensas financieras y controles para lograr las metas organizacionales.
3. Argyris, Maslow y McGregor, con su teorÚa del hombre que se realiza a sÚ mismo, se basan en que las necesidades del hombre estÃn ordenadas
jerÃrquicamente y son en orden creciente: seguridad y supervivencia, sociales, autoestimaciµn, autonomÚa y necesidades de realizaciµn personal; cuando las
necesidades de nivel inferior estÃn satisfechas, el individuo comienza a interesarse por satisfacer las demÃs. El contrato psicolµgico es, pues, de
seguridad, contacto social, orgullo personal, autonomÚa y realizaciµn personal a cambio del esfuerzo individual. El problema radica en que chocan las necesidades
de independencia y realizaciµn personal con las necesidades de la organizaciµn de dependencia y limitaciµn. 4.
Hombre complejo de Schein està basado en los anteriores; el individuo es un sistema de necesidades biolµgicas, motivos psicolµgicos, valores y percepciones.
Este sistema funciona homeostÃticamente, manteniendo el equilibrio interno al enfrentarse a las demandas que le imponen las fuerzas externas. El sistema
interno se desarrolla para resolver los problemas que le presenta el ambiente; Õste, a su vez, viene del trato con los superiores, compaþeros y subalternos del
trabajo, asÚ como del cumplimiento de sus tareas especÚficas. CONDUCTA Y ORGANIZACIÆN
Existen dos tipos de factores: a) Factores higiÕnicos, que no motivan y son acciones para evitar el descontento
como son las condiciones fÚsicas del trabajo, salarios, prestaciones sociales, etc. b) Factores motivadores; la
motivaciµn real del individuo es el ¨propio sentido de la realizaciµn en el trabajo£. El contrato psicolµgico
se basa en el deseo de utilizar las capacidades del individuo para resolver problemas. Existen, dentro de los
patrones de motivaciµn en cada personalidad, mºltiples motivos. McClelland identifica tres primordiales: necesidades de realizaciµn como una necesidad de
Õxito competitivo. La necesidad de pertenencia, ya definida anteriormente, y la necesidad de poder definida como la necesidad de controlar e influenciar sobre
los demÃs. Los individuos, dentro de sus diferencias personales, tienen diferentes niveles en estos motivos y, aunque dominen uno determinado, siempre
existen en mayor o menor grado los otros dos. En la realizaciµn de la soluciµn de problemas, el individuo emplearà unos patrones de conducta, que se irÃn
afianzando segºn vaya resultando positiva la resoluciµn del problema, lo que darà lugar a diferencias motivacionales en el individuo y competirà de acuerdo
con su estÃndar de excelencia (realizaciµn, pertenencia o poder). La conducta de un individuo dentro de una situaciµn organizacional determinada no es solamente en funciµn de
las caracterÚsticas de su sistema individual, sino tambiÕn de los problemas que la Organizaciµn le plantea. UN
BUEN ¨.CONVENIO£ El sistema individual, las expectativas de los demÃs, la tarea y variables formales de la
organizaciµn actºan de forma recÚproca para formar el criterio del individuo sobre lo que la organizaciµn espera de Õl. La interacciµn de todas estas
variables definen el ¨convenio£ que el individuo y la organizaciµn han de llevar a cabo. En un periodo
pre-convenio; pido encarecidamente a la organizaciµn que en sus pretensiones tenga en cuenta el carÃcter humano de todos sus colaboradores individuales.
Asimismo a los representantes de los trabajadores, que, a su vez, tengan presente que los objetivos del transporte aÕreo son nuestros, no de la
organizaciµn, y, por lo tanto, debemos conseguir a toda costa su desarrollo, competitividad, calidad y realizaciµn como una meta a conseguir, resolviendo
correctamente los problemas que se presenten como parte de una motivaciµn personal que todos ansiamos.
BibliografÚa Evaluaciµn de taras O.I.T. Ginebra, 1986. Articulo Julio 2013 La Comunicaciµn Social en la Organizaciµn y el Stress.
La sociedad actual. se caracteriza por su organizaciµn polifacÕtica y por el elevado nºmero de organizaciones que existen en la misma; la sociedad actual es
por lo tanto una sociedad organizada. Entre los factores individuales que condicionan el desarrollo de las organizaciones està la consecuciµn racional
de intereses especÚficos econµmicos, culturales, religiosos, etc, que facilitan la formaciµn de las Organizaciones para la consecuciµn de estos fines,
Todo ello nos lleva a poder afirmar que un individuo puede pertenecer simultÃneamente a una o varias
organizaciones,(empresa, sindicato, religiµn, ,partido polÚtico, etc.), pero para nuestro propµsito nos limitaremos a aquellas organizaciones de tipo
laboral, que tienen mÃs influencia. y cuyos objetivos estÃn mas en consonancia con nuestra labor de tripulante, considerando a las demÃs organizaciones como
importantes solamente en "nuestro tiempo libre". No intentamos definir la. Organizaciµn, puesto que ademÃs de su complejidad no
es el tema a tratar, solamente tomaremos aquellos conceptos que nos puedan ser ºtiles. Segºn Bernard, las organizaciones estÃn compuestas por personas y/o
grupos, se pueden considerar a los individuos como las unidades mÃs elementales de la organizaciµn. Una
organizaciµn tiene el problema de delimitaciµn de tu pertenencia, que resuelve de diferentes maneras; bien mediante signos (el sistema mÃs sencillo y simple),
como puede ser el empleo de uniformes, sÚmbolos de identificaciµn (emblemas etc.), y carnets de asociado y otros variados medios. Otra forma consiste en el
desarrollo de una mente de grupo y por el empleo de otros medios mÃs o menos sofisticados. Cuando una
organizaciµn incorpora a un miembro de acuerdo a una serie de habilidades, conocimientos y aptitudes para la. consecuciµn de sus fines, incorpora
queriÕndolo o no mucho mÃs; a la. persona entera, Los miembros de una organizaciµn son seres humanos, por lo tanto complejos y con un amplio abanico de habilidades
y aptitudes, a los que hay que aþadir una serie de necesidades, expectativa y objetivos que quieren ver realizados en la organizaciµn, pero tambiÕn tienen
vinculaciones y fidelidades, a otros grupos externos de la organizaciµn que pueden influir en su comportamiento, sus actitudes y su sistema de valores
dentro de la organizaciµn. La organizaciµn formal no logra cubrir las dimensiones del individuo, ni tampoco
pretende abarcarlas todas, razµn por la que debido a espectros no previstos dan lugar a aspectos informales que son necesarios seþalar y analizar la influencia
que pueden tener en el funcionamiento eficaz de la organizaciµn. Otro aspecto importante en las organizaciones son los grupos. Segºn Porter y
cols. los grupos estÃn compuestos por un numero limitado de individuos que tienen interacciones comunes y un cierto grado de valores y normas compartidos
(estÃndares de conducta). Los grupos a su vez pueden ser de dos tipos; los formales, diseþados por la.
organizaciµn y establecidos para apoyar la consecuciµn de sus propios fines y los grupos informales que surgen dentro de la organizaciµn, bien para satisfacer
necesidades de los miembros no cubiertas por la organizaciµn o bien para suplir las insuficiencias del diseþo de la misma, en todo caso demuestran una
deficiencia de la organizaciµn que es necesario corregir con los medios y mÕtodos de la disciplina del Desarrollo Organizacional
Los grupos formales en ente caso serian el grupo de pilotos y por una extensiµn en afinidad de objetivos el grupo
de tripulantes tÕcnicos, cuya meta final es planificar, desarrollar y ejecutar las misiones de vuelo con la mayor seguridad, eficacia, ahorro y rapidez.
Para Parsons la. primacÚa de orientaciµn hacia. la consecuciµn de fines especÚficos es la caracterÚstica de las organizaciones que las diferencia de los
demÃs sistemas sociales, estos son los fines de los miembros de la organizaciµn. La organizaciµn
tiene la. misiµn de que los fines que persigue sean asumidos por la totalidad de sus miembros y que ademÃs den su energÚa, habilidades y esfuerzos para su
consecuciµn. Es una razµn muy importante que estor, fines sean objeto del conocimiento comºn, para poder guiar los esfuerzos
de los miembros, legitimar sus conductas y establecer los niveles mÚnimos a conseguir por la organizaciµn. Es de vital importancia la. comunicaciµn entre
organizaciµn y sus miembros, sobre todo en la "sucesiµn de objetivos", que segºn afirma Sills se da en la organizaciµn por que los objetivos establecidos ya han
sido alcanzados ,y es necesario fijar otros nuevos para lograr la supervivencia; o bien, el entorno obliga a una reformulaciµn de los objetivos a fin de poder
responder de una manera. mÃs eficaz a las exigencias del nuevo ambiente. La distribuciµn de informaciµn en la organizaciµn, sus redes de comunicaciones y
sus flujos es importante, puesto que influye en la conducta de sus miembros y es 1a esencia de un sistema social o de una organizaciµn que debe perseguir que la
comunicaciµn sea lo mÃs fluida y eficaz posible al objeto de conseguir sus objetivos. Cada :miembro debe recibir de forma ininterrumpida todas aquellas informaciones
que necesita para poder actuar de acuerdo con el fin perseguido. Es tan importante el concepto de la. comunicaciµn que en la. soluciµn de conflictos, ha
sido uno de los principales medios usados el de la mejora. de las estructuras y procesos de comunicaciµn. Aunque lo normal es que los conflictos no surgen por
deficiencias en los sistemas de comunicaciµn, sino por la contraposiciµn de los intereses entre las partes. Tal es la. importancia de la comunicaciµn.
Hemos afirmado que las tripulaciones tÕcnicas funcionan como un grupo formal dentro de la organizaciµn. Atendiendo a Cooley lo podrÚamos caracterizar como un
grupo primario, ya que està caracterizado por la. relaciµn intima cara a cara, tener conciencia de nosotros y ademÃs tener un destino en comºn, caracterÚsticas
similares y ocupar un espacio determinado. Los canales de comunicaciµn son atÚpicos, debido fundamentalmente al espacio en que se desarrolla la actividad.
del grupo, sin embargo tiene una gran rapidez en la transmisiµn de la informaciµn , lo hace aproximadamente en forma. de progresiµn geomÕtrica. La
forma de comunicaciµn es predominantemente verbal. Por las caracterÚsticas de los canales de comunicaciµn, los inputs de informaciµn estÃn expuestos a
"ruidos" ajenos a la informaciµn a tratar, que obviamente distorsionan la salida o los outputs de la informaciµn a transmitir. Este tipo de informaciµn puede
compararse a los rumores, muchas de cuyas caracterÚsticas, leyes y formaciµn siguen. Knapp define el rumor
como una proposiciµn para creer un tµpico difundido sin verificaciµn oficial, contemplÃndolo como un caso especial de la comunicaciµn informal.
Allport lo define a su vez como una proposiciµn especifica para. ser creÚda que pasa de persona a persona,
generalmente por vÚa oral, sin medios de prueba serios para demostrarla. . Las condiciones bÃsicas para que surja un rumor son: ambig■edad informativa
acerca de su contenido y que sea un asunto importante. La ley fundamental del rumor de Allport. y Postman afirma que la ambig■edad e importancia del rumor
tiene un efecto multiplicador R = A.I, no habrà rumor si uno de los factores es cero. Esta formula la ha retocado
Chorus, aþadiendo el sentido crÚtico del individuo 1/C con lo que el rumor R es funciµn (f) de la, importancia I, la ambig■edad A e inversamente del sentido
critico del sujeto C. R= (f) I.A.1/C. Entre las caracterÚsticas del rumor, siguiendo a Knapp tenemos:
.- El rumor no excede ni en complejidad ni en longitud la capacidad de memoria del grupo en que se da., es corto, sencillo e importante.
.- Con el tiempo el rumor acaba cristalizando en una buena historia, .- Por humildes que sean las fuentes primarias, pronto se atribuyen a fuentes
prestigiosas con lo que consiguen honorabilidad y apariencia de veracidad. .- El rumor encaja con las tradiciones culturales del grupo en cuyo seno
circula. .- Expresa y gratifica las necesidades informativas y emocionales de la comunidad. El rumor se transmite por medio
de tres leyes. Ley de nivelaciµn, durante la transmisiµn el rumor tiende a acortarse y a hacerse mÃs conciso.
La ley de acentuaciµn, consiste bÃsicamente en la percepciµn, retenciµn y narraciµn de forma selectiva de una
parte del . contexto. Ley de asimilaciµn, loe individuos tienden a reorganizar los contenidos dÃndoles una forma y haciÕndoles
congruentes con el sistema. central de acuerdo con su: propias caracterÚsticas, ¢ Que influencia tiene el rumor en el trabajo.? Una muy importante "el stress".
Veamoe como lo definen diversos autores. Fuff, el stress es un esfuerzo agotador para mantener las funciones esenciales.
Lypowsky, es aquella informaciµn que el sujeto interpreta como amenaza de peligro. Bonner la define como
frustraciµn y amenaza que no puede reducirse y para Grom es la imposibilidad de predecir e1 futuro. Conceptos todos ellos desarrollados anteriormente.
Como aplicaciµn didÃctica sobre todo lo expuesto podrÚamos hacer una aplicaciµn sobre alguna nota informativa que tengamos a mano y sin nombrar ninguna al
objeto de que no parezca mÃs una crÚtica que un estudio sobre el tema; que en la actualidad està teniendo una cierta importancia en los estratos de la. sociedad
y que puedo constatar personalmente, ya. que he estudiando y siguiendo varios casos de stress producidos por este tipo. Caracterizados por cuadros clÚnicos de
apatÚa, falta de entusiasmo en el trabajo, indefensiµn ante los problemas cotidianos, aumento de los niveles de colesterol, mayor actividad de las
glÃndulas suprarrenales con aumento de noradrenalina, insomnio, alteraciones psicosexuales, irritaciµn incluso con perdida de amigos, resentimiento,
suspicacia, baja autoestima, depresiµn y ansiedad; lo que nos puede dar una idea de la importancia del stress. Tengo a mano la. que ha
originado este pequeþo estudio y que a pesar de su aparente perfecciµn, (rapidez de trasladar la informaciµn, abundancia de datos, razones, informes tÕcnicos,
etc), adolece de la. falta de no ser completa, (falta de firma, organismo remitente, datos incompletos o inexistentes, etc), introduce en factores
causantes de rumores y lo que es mÃs grave productores de stress entre, los miembros. Este estudio debido a su gran extensiµn lo tengo como un ejercicio
individual de autoterapia. Para, terminar el trabajo y no hacerlo mÃs extenso, veamos algunas reglas para
controlar y reducir los rumores segºn Knapp y Rouquette. Ofrecer una exacta y completa informaciµn a travÕs de los medios regulares de comunicaciµn, en nuestro casa a
travÕs de notas informativas, escritas y con lenguaje claro. Fomentar la confianza en los dirigentes de la organizaciµn.
Difusiµn mÃxima y rÃpida de las noticias importantes, procurando que la informaciµn llegue a todo el mundo.
Resumiendo, la. organizaciµn està formada por grupos, para la. consecuciµn de sus fines es imprescindible una correcta informaciµn. Los tripulantes tÕcnicos
son uno de los grupos formales de la organizaciµn, su sistema de comunicaciµn dentro del grupo es atÚpico, semejante a los rumores. Una falta de comunicaciµn
entre la organizaciµn y el grupo de una informaciµn incompleta, da lugar a travÕs de una elaboraciµn de procesos a stress en los miembros del grupo. Es
necesario impedir que esto ocurra mediante un tratamiento adecuado de la informaciµn,
ArtÚculo Junio 2013 INSOMNIO EL INSOMNIO Y LA AVIACION A pesar de los continuos cambios de aviones,
tripulaciones, maletas, nºmeros de lÚneas, que presentaban una dificultad en la comunicaciµn entre la tripulaciµn, cuestion vital en el funcionamiento del
sistema, no tardÕ mucho en observar conductas en tripulaciones que sÚ me inquietaron; Õstas estaban relacionadas con el insomnio y, naturalmente, la
seguridad de la operaciµn està dentro de los lÚmites establecidos. El trabajo realizado en estas condiciones, con lÚneas de madrugadas y durante una serie de dÚas continuados, aunque con el
descanso reglamentario sobrepasado con exceso, sin embargo, a veces, parte de la tripulaciµn se encuentra cansada, "atontada" y somnoliente al empezar el
trabajo. Era para mÚ una nueva experiencia. RAZONES Aparentemente ninguna, han tenido el suficiente
tiempo de descanso, entendiendo el tiempo libre segºn la programaciµn, empleado en : a) descansar, b) desconcentrarse del vuelo y c) dedicarse a sus
entretenimientos : leer, teatro, cine, deportes, TV, preparar el vuelo del dÚa siguiente, etc. Sin embargo, existen; vamos a elegir de forma puntual una,
quizÃs la mÃs importante. INSOMNIO. Segºn el Dr. Dement " la gente que ha acumulado una gran cantidad de deuda de sueþo es peligrosa en las carreteras,
peligrosa en el aire, peligrosa en cualquier sitio en que estÕ ". Esto es debido a que un ataque de sueþo incontrolado es impredecible, como ocurre con un dolor
de cabeza y sus efectos pueden ser devastadores. El profesor Martin, Profesor de FisiologÚa en la
Universidad de Harvard y que ha realizado extraordinarios estudios sobre el insomnio, afirma que , aunque las lÚneas aÕreas continºan siendo una de las mÃs
seguras formas de transporte, el insomnio del piloto es una cosa real y con una certeza tal que raramente se discute. TambiÕn describe el desgaste y uso de los
ritmos circardianos de las tripulaciones que vuelan dÚa y noche a travÕs de mºltiples zonas horarias. " Ellos duermen dos horas menos que lo usual en los
viajes, asÚ estÃn deprivados de sueþo y, ademÃs, operan en el estrecho, monµtono y oscuro medioambiente de la cabina ". Pone como ejemplo a un piloto volando un
reactor comercial en aproximaciµn final al Aeropuerto de Chicago O'Hare, estaba virando hacia el edificio terminal de American Airlines, en lugar de efectuarlo
sobre la pista. Despiste que fue avisado por los demÃs miembros de la tripulaciµn, el copiloto se encontraba en un estado zombie. La respuesta fue
" no hay problema ". E1 comandante tuvo que tomar el control del aviµn. La Gerencia de otra compaþÚa aÕrea intentµ
seþalizar la fatiga del piloto. Lo primero fue revisar la programaciµn de las tripulaciones, llegando a la conclusiµn de que era totalmente impensada y
errÃtica. Se gastan billones de dµlares en optimizar el equipo, mientras tenemos una baja inversiµn en la mÃs compleja pieza en la maquinaria del aviµn : " el
cerebro del piloto ". Formulemos una hipµtesis . El tripulante llega cansado al hotel, sin ganas de otra cosa que la simple de estar sentado y con la
mente en blanco, alejarse de sus problemas cotidianos. Se encierra en su habitaciµn, se pone cµmodo. Enciende la TV e incluso para no salir, pide algo de
comer en la habitaciµn, ve con el interÕs del momento los programas, si son de su agrado; lee su libro favorito o bien se entretiene con uno de los muchos
"hobbies" que se prodigan en esta profesiµn. Existen tripulantes que pasan una lÚnea prÃcticamente entre el aviµn y la habitaciµn. Problemas : la habitaciµn y
la cama se van asociando con una conducta determinada y no con la de dormir. Resultado : insomnio. En una lÚnea larga los efectos del insomnio se acumulan.
Consecuencias : "stress" en el trabajo, bajo rendimiento... INSOMNIO El insomnio es uno de los sÚntomas mÃs frecuentes
en la clÚnica, se estima que un 30% de la poblaciµn general acude alguna vez al aþo a una consulta mÕdica a causa de problemas con el sueþo ( Kaplan y Sadock ).
Otros autores afirman que afecta a mÃs de un 10% de la poblaciµn mundial. Para Laberge, mÃs de 50 desµrdenes distintos y diversos son consecuencia de los
millones de durmientes nocturnos. Estos porcentajes son mucho mÃs elevados en nuestra profesiµn debido al sistema de vida desarrollada. El sueþo, segºn el autor anteriormente citado,
consiste en un estado regular, recurrente, fÃcilmente reversible, caracterizado por una tranquilidad relativa, un gran incremento en el umbral o en la respuesta
a estÚmulos externos en comparaciµn al estado de vigilia. Hay que distinguir entre dormir y soþar. El acto de dormir es independiente del de soþar, aunque en
el idioma castellano no se distingue semÃnticamente el hecho de dormir y el de soþar. Durante la fase de dormir es cuando tienen lugar
los sueþos o ensueþos que, debido a la gran vivencia de los mismos, las neuronas en el cerebro detienen desconectando muchos de nuestros mºsculos, de tal forma
que estamos efectivamente paralizados. Dorff afirma que de algºn modo puede sobrepasarse este sistema que està correctamente designado por una naturaleza
sabia para prevenir el funcionamiento de los mismos. En el Hannepin County Medical Center de Minneapolis han estudiado casos de personas de maneras suaves
durante el dÚa y que en los sueþos llegan a ser violentos, por fallos en este mecanismo. Las razones por las que esto ocurre son todavÚa desconocidas y estÃn
en estudio. A partir de ahora tomaremos el tÕrmino sueþo por dormir, mientras que lo que hemos denominado sueþo, lo llamaremos ensueþo. Los medios actuales para el estudio del sueþo
emplean, principalmente, los registros poligrÃficos ( electroencefalograma ), la observaciµn conductual del individuo. TambiÕn se tienen en cuenta los propios
informes del individuo, e incluso los de su acompaþante en el lecho. Gracias a estos medios se han catalogado las caracterÚsticas del sueþo normal, tales como
las fases electroencefalogrÃficas, sueþo REM y sus componentes, ciclos de dormir ( sueþo - vigilia, REM - no REM ). Las caracterÚsticas fisiolµgicas y
conductuales, tanto del sistema vegetativo ( ritmo cardÚaco, respiratorio, presiµn arterial, flujo sanguÚneo, funciones digestivas, resistencia elÕctrica
de la piel, respuestas sexuales, infartos, ºlceras, etc. ), como del sistema neuromuscular y endocrino. TambiÕn se han estudiado el sustrato neuroanatµmico y
bioquÚmico del sueþo y la actividad psÚquica durante el dormir. Por todo ello, el sueþo ya no se considera como un mero estado de pasividad, sino como un
estado en que la actividad nerviosa ofrece un patrµn diferente al que realiza durante la vigilia. Tampoco se considera como una total desconexiµn con el mundo
exterior, ya que las personas poseen algºn mecanismo activo para el filtraje semÃntico de la informaciµn que funciona incluso cuando estÃn dormidas, como
ocurre, por ejemplo, a una madre que se despierta al llanto de su hijo y no lo hace ante ruidos mÃs intensos de otra naturaleza. TambiÕn se puede afirmar que,
aunque el individuo reaccione ante estÚmulos significativos con cambios en el EEG, sin embargo el aprendizaje apenas es posible, solamente y de forma leve en
las fases de sueþo ligero. Investigadores norteamericanos han llegado a la conclusiµn de que entre 7 y 7,9 horas de sueþo correlacionan positivamente con
una mayor longevidad. Los que duermen menos de esta cantidad tienen mÃs anginas de pecho 0 dolores de cabeza. Los mÃs dormilones tienen mÃs infartos de
miocardio o ataques cerebrales. Esto no significa que el sueþo por sÚ mismo sea la causa de estas condiciones. Sin embargo, la muerte y particularmente la
muerte repentina se produce en las primeras horas de la maþana. TIPOS Y CLASIFICACIÆN
1) INSOMNIO Consiste en las alteraciones del sueþo que pueden
ser en general de dos tipos : 1) sÚntoma primario y 2) sÚntomas secundarios asociados a otros como depresiµn, estados del organismo ( ansiedad, etc. ). El
insomnio es, despuÕs del resfriado comºn, la dolencia mÃs normal de la salud.
Existe una gran variedad de tipos de insomnio, cuya lista sobrepasa los 50 items. Clasificaciµn. Las alteraciones del sueþo pueden
clasificarse en una forma general como : Insomnio a) de carÃcter primario o idiopÃtico
b) de etiologÚa ( o causa fundamental ) conocida, bien de tipo orgÃnico ( cerebral o no cerebral ) o de origen exµgeno o externo.
El insomnio puede caracterizarse por : a) un aumento en la latencia en el dormir ( insomnio predormicial ), Õste es el mÃs
frecuente y es debido a causas exµgenas; b) elevado nºmero de despertamientos durante la noche (insomnio intermitente ), y c) despertarse tempranamente (
insomnio postdormicial ); estos tres tipos se pueden dar de forma conjunta o separada.
Subjetivamente existen personas que, a pesar de dormir bien, se quejan de no hacerlo bien ( pseudoinsomnes ) y lo contrario, a pesar de dormir menos de lo
que se considera normal, no lo toman en consideraciµn ( insomnes sanos ). En la exploraciµn del insomne se debe investigar el
tipo de insomnio, recabar datos sobre la persona y tambiÕn de su familia, puede ser necesario llevar a cabo algºn anÃlisis poligrÃfico. AdemÃs del examen
fÚsico, tambiÕn es necesario un estudio anamnÕsico . ritmos de comida, ritmo de trabajo, edad, situaciones ambientales y aquellos otros que se consideren
necesarios. El insomnio idiopÃtico o primario puede ser debido a factores etiolµgicos exµgenos como el calor, los cambios de horarios, ruidos,
cambios meteorolµgicos. Una causa hÚbrida es el exceso de trabajo mental (insomnio funcional). El miedo al insomnio crea ansiedad y Õsta, a su vez,
aumenta el insomnio. Entre los factores orgÃnicos, la etiologÚa es mºltiple, pueden ser causas del mismo alteraciones orgÃnicas, afecciones
cerebrales como lesiones o tumores, procesos encefalÚticos, afecciones no cerebrales como hipertiroidismo, insuficiencias cardÚacas o hepÃticas, dolores,
etc. TambiÕn son causa del insomnio, del mismo modo que las problemas conscientes dificultan el dormir y prolongan la vigilia, los
conflictos inconscientes y, a menudo, la mÃs comºn de este problema. Este estado es, frecuentemente, uno de los sÚntomas mÃs tempranos e inespecÚficos de enfermedad, bien orgÃnica o mental.
2) HIPERSOMNIO Es un sÚntoma poco frecuente y puede clasificarse como: a) Hipersomnio idiopÃtico, que se caracteriza por
un aumento en la actividad en el tiempo que se pasa durmiendo durante la noche, una vez despertado se encuentra rÃpida y plenamente recuperado; en compensaciµn
durante el dÚa sufre una hipersomnolencia que compensa el sueþo nocturno, parece ser una alteraciµn hereditaria en el metabolismo que regula las estructuras del
ciclo sueþo-vigilia. b) La narcolepsia es un cuadro de hipersomnio y viene caracterizada por una exagerada tendencia a la somnolencia diurna,
acompaþada, a menudo, por ataques irreversibles de sueþo en cualquier situaciµn; es comºnmente hereditaria. Entre los sÚntomas accesorios tenemos la cataplejia o
pÕrdida sºbita del tono muscular de varios mºsculos o de todos ellos. La parÃlisis durante el sueþo es una angustiosa incapacidad de moverse justo al
dormirse o al despertarse. ImÃgenes hipnogµgicas, el individuo se siente atemorizado. 3) TRASTORNOS NOCTURNOS
EPISÆDICOS Bajo este tema se integran una serie de conductas que suceden durante el dormir, sin que exista una alteraciµn cuantitativa del
dormir. Pueden clasificarse en : a) Antes del dormir, miedo a dormirse y rituales o
hÃbitos de tipo obsesivo. b) Durante el sueþo. Sonambulismo es un fenµmeno tÚpico infantil. Terrores nocturnos, es tambiÕn de carÃcter infantil y se
distingue por ataques sºbitos de terror y agitaciµn. Eneuresis, cuando el individuo no se despierta durante la misma, la humedad se incorpora entonces al
ensueþo. Somniloquia, consiste en hablar por la noche, es un fenµmeno infantil normal. Pesadillas, tambiÕn conocido como sueþos angustiosos, un gran nºmero de
pesadillas se da en personas que son proclives a la esquizofrenia y suelen ser mÃs frecuentes en estados de ansiedad o de depresiµn. Bruxismo, fenµmeno que
consiste en rechinar los dientes, en los adultos se da con mÃs frecuencia en estados de ansiedad, el alcohol agudiza esta crisis. Jactatio capitis, son
movimientos rÚtmicos y balanceantes de la cabeza y tienen su apariciµn antes o durante el sueþo. 4) SëNDROMES QUE CURSAN CON APNEA
Se caracterizan por una serie de cuadros de trastorno del sueþo y crisis apnÕicas recurrentes en el mismo sueþo. La apnea
consiste en una falta o suspensiµn en la respiraciµn, razµn por la que hay que detectar con precisiµn estos cuadros, ya que si se trata al paciente con
tranquilizantes y depresores de los centros respiratorios, se corre el peligro de arriesgar su vida. Hasta aquÚ, de forma escueta, las principales alteraciones
primarias del sueþo. OTRAS ALTERACIONES DEL SUEîO Veamos ahora algunas de las alteraciones del sueþo
en varios cuadros psicopatolµgicos. Debido a la alta labilidad ( frÃgil, dÕbil ) del dormir, se observan notables alteraciones y una gran diversidad, tanto
mÕdicas como neurolµgicas. Los datos disponibles no son homogÕneos ni uniformes, por los criterios nosolµgicos empleados o por el tipo de psicofÃrmacos
empleados, lo que dificulta las replicaciones. 1) Depresiµn, aunque existe un insomnio apreciable
de los tres tipos, sin embargo hay cuadros depresivos con una clara hipersomnia. En el caso de las psicosis maniacodepresivas circulares, el paso de la depresiµn
a la manÚa, que puede durar de minutos a varios dÚas, durante este paso existe una pÕrdida de sueþo. 2) Psicosis, antes de un brote psicµtico se produce
un aumento en la intensidad y nºmero de las pesadillas nocturnas. 3) Estados de ansiedad, Õstos se caracterizan por
un mayor grado de activaciµn, lo que origina una alteraciµn del ciclo sueþo-vigilia. El insomnio estarà en relaciµn directa con los
elementos ansiµgenos ( fobias, obsesiones, enfermedades mÕdicas,stress, etc. ), aunque el stress tiene situaciones en que llevan consiqo un aumento del
tiempo del sueþo, que produce una recuperaciµn del desgaste producido por el stress. 4) ManÚa, es un caso extremo de insomnio. El
individuo apenas descansa, el tiempo del sueþo està reducido al mÃximo. 5) Drogodependencias, las drogas que crean
dependencia, como anfetaminas, morfina, heroÚna, alcohol, barbitºricos, etc., disminuyen el tiempo de sueþo tipo REM. 6) Otros cuadros, como el retraso mental, se puede
apreciar una disminuciµn en el tiempo total. El autismo, el insomnio se atribuye a un hipotÕtico retraso madurativo de tipo neurolµgico.
VIDA REGULAR El horario regular, evitar la cafeÚna y el fumar
por la noche; està probado que los muy fumadores nocturnos tardan mÃs en dormirse y, ademÃs, se despiertan durante la noche con mÃs frecuencia que los no
fumadores. Un trago a ºltima hora ayuda a dormir, pero no si es con exceso. TambiÕn seguir el ritual de realizar las mismas actividades se convierte en un
ensayo de dormir. La alimentaciµn es importante, el calcio, el magnesio y las vitaminas B, sobre todo la B1, ayudan a relajar los nervios.
TRATAMIENTO DEL INSOMNIO El tratamiento tradicional para mejorar el insomnio
ha sido el de tipo farmacolµgico, pero con resultados poco alentadores, ya que la mayorÚa de los medicamentos perdÚa su efectividad al cabo de cierto tiempo de
uso continuado, siendo necesario un aumento en las dosis a aplicar, derivando en problemas de adicciµn o dependencia, con el peligro de que una dosis excesiva o
retirada de las mismas, generen consecuencias graves. En el tratamiento hay que tener en cuenta la
distinciµn entre los dos tipos primario y secundario. En el primario, la dificultad para dormir es el
ºnico sÚntoma de anormalidad; en el secundario, esta dificultad es el resultado de otros tipos de trastornos fÚsicos y psÚquicos. El primer tipo suele ser consecuencia de tres tipos
de circunstancias : a) Pobre aprendizaje de los hÃbitos de dormir, dificultando el ritmo de dormir y ademÃs favorece la ruptura de los ciclos del
cuerpo, tales como la regulaciµn de la temperatura o el sistema endocrino de tipo circardiano. b) El desarrollo de actividades en la cama y en la
habitaciµn, que son incompatibles con el dormir, como ver la televisiµn, leer libros, comer, etc., asÚ como pensar en los problemas del dÚa que acaba y los
del que viene. c) El esfuerzo positivo que supone la atenciµn de los demÃs, como puede ser el no poder dormir. En cuanto al insomnio secundario, las causas son
diversas y como mÃs principales estÃn el stress y los trastornos afectivos, que, en muchos casos, suelen ser consecuencia del propio insomnio. TambiÕn existen muchas teorÚas y tÕcnicas de
relajaciµn y que tienen como comºn denominador que cuanto mÃs relajada se encuentre una persona en el momento de acostar se, menos tiempo consumirà en
quedarse dormida. Entre las muchas tÕcnicas, resumiremos una, la utilizada por Bootzin y otros varios, que afirma : Acostarse para dormir
ºnicamente cuando se tenga sueþo. No utilice la cama para nada que no sea dormir, no lea, no vea la televisiµn, no coma o repase los problemas en la cama.
LevÃntese siempre a la misma hora, aunque no se haya dormido ( dÚficil en nuestra profesiµn ). No duerma durante el dÚa. Volviendo al principio vemos
que, precisamente, la propia conducta del tripulante, habitaciµn - aviµn - habitaciµn, es una importante fuente de producciµn del insomnio. El cambio de
este tipo de conducta es primordial para romper el cÚrculo del insomnio en que, sin querer, nos podemos ver metidos; pasee, coma fuera de la habitaciµn, haga
deportes y cualquier hobbie que no incluya estar encerrado como un monje cartujo y su salud se lo agradecerÃ. ArtÚculo Mayo 2013 MOTIVACIÆN:
ANGUSTIA Y MIEDO: Ya va siendo vulgar la distinciµn entre lo que es angustia y miedo. La Angustia, la define el
diccionario refiriÕndose a la aflicciµn, y Õsta, a la pena y a la tristeza. Es decir, el lenguaje reconoce las transiciones entre los estados de Ãnimo. Lo
conocido siempre produce un impacto menor pues existe la posibilidad de evadirse, por lo tanto la transformaciµn de la angustia en miedo es un mecanismo
de defensa. Mucho se ha discutido si angustia y ansiedad es lo mismo; hay que recordar que Lµpez Ibor, lo considera
como matices de una misma experiencia. Vamos a tratar sµlo de la angustia y a dµnde nos conduce ya que es mÃs profunda, mÃs fÚsica, en cambio la
ansiedad es mÃs elevada, mÃs noÕtica y libre. Un estado determinado de la angustia, puede revelarse de dos formas: .- una extrÚnseca, es decir, basada en diversos
contenidos, y .- otra intrÚnseca, dada por la sucesiµn de momentos. La extrÚnseca: yo puedo pensar
en mi trabajo en el aviµn, en mis compaþeros, responsabilidad, mujer, hijos, etc. Pero cuando nuestras ocupaciones no aparecen distintas con algunas
novedades, surge el aburrimiento, que podrÚamos llamar exµgeno, y para defenderse de Õl, el sujeto trata de "MATAR EL TIEMPO", y actºa de modo
diferente a su forma normal de conducta. La intrÚnseca consiste en lo
siguiente: en una recta, los puntos son iguales entre sÚ, pero en la recta de la
vida no, sino que se suceden como engendrados unos por otros. La vida es
proyecto y cada momento trae una nota de novedad, pues si no fuera asÚ,
aparecerÚa el aburrimiento, que a diferencia de la anterior, podrÚamos llamar
endµgeno. ¢Son iguales la angustia normal
y la anormal?. Para mÚ la diferencia entre ambas consiste en lo siguiente: El sujeto normal puede
experimentar miedo ante una situaciµn concreta mientras que el anormal lo
experimente cuando entre en el concepto de lo inacabable o incomprensible. Es
frecuente la tesis de que la angustia es anormal cuando no puede soportarse y el
sujeto escapa mediante mecanismo de defensa. Lµgicamente la igualdad de la
angustia normal y anormal se diferencia en los distintos medios de defensa. Las
realidades clÚnicas en el psicoanÃlisis nos enseþan que si los medios de defensa
son anormales, es porque la angustia es PRIMARIAMENTE ANORMAL, pues el sujeto la
percibe de una forma anormal, y a veces pone medios de defensa anormales como
pueden ser el alcohol, los tµxicos y las drogas. El sujeto se encuentra en un
ansia de poder y euforismo que tienden a darle confianza en sÚ mismo, y asÚ
oculta las grietas de su personalidad. El alcohol: El beber
social es una de las tradiciones mÃs difundidas. Aparte de ello, se efectºa una
constante publicidad por los medios de comunicaciµn masiva. La promociµn de los productos
alcohµlicos no constituye, un acto lesivo para la salud del consumidor, pues
exalta las cualidades del artÚculo de venta, su procedencia, su nobleza y
calidad degustativa. Es bien sabido por todos, que un
sujeto normal no precisa beber alcohol para convivir y disfrutar de la vida,
tanto en el plano individual como en el social. En cambio existen seres
diferentes de la mayorÚa, con caracterÚsticas en su personalidad que los colocan
en un plano opuesto al de la normalidad. Personas profundamente sensibles, a
quienes se les dificulta por sus hiperetersias, tanto emocionales como
afectivas, el poder entablar un adecuado contacto con el mundo que los circunda,
y el cual no ha sido creado para contenerlos, superan el umbral de lo aceptado y
razonable. El que un auxiliar de vuelo
arroje sobre un pasajero cualquier producto alimenticio, no tiene mÃs
importancia que la de haber estropeado el traje del seþor. Esto, para mi
entender, la mayor transcendencia que puede tener es un parte por escrito a la
flota de operaciones y punto. La cosa queda ahÚ. Si me aprietan podÚa decirles
que es un problema de imagen de empresa. Pero el tripulante que necesita tomar
un estimulante para poder empezar su labor, està claro que tiene un principio de
anormalidad, pues si fuera normal no lo necesitarÚa para desempeþar su funciµn. Como los casos que se pueden dar
normalmente dentro del alcoholismo son trastornos menores, quiero explicar en
sÚntesis las diferencias que existen entre los mismos. Consecuencias: Trastornos de humor. Son los que
se manifiestan con hipermotividad, llanto fÃcil, fases depresivas que alternan
con cordialidad y jovialidad. Trastornos de carÃcter. La
irritabilidad es constante, la cµlera sºbita, violenta, seguida de remordimiento
y resoluciones efÚmeras. Trastornos afectivos. Se insiste
en el carÃcter egocÕntrico del alcohµlico y la disminuciµn de su sentido moral,
a veces, el alcohol aplaca la ansiedad. Trastornos intelectuales.
Aparecen mÃs tardÚamente, descenso de la atenciµn y de la eficiencia
intelectual, alteraciones que acaban dando un aspecto de obstrucciµn
intelectual. El sueþo es casi siempre agitado, interrumpido por pesadillas o
insomnio. Trastornos sexuales. Descenso de
la potencia sexual en el hombre y va parejo con los temas de celos. Trastornos neurolµgicos.
Calambres, dolor a la presiµn de las masas musculares y temblores. Trastornos orgÃnicos. NÃuseas
matutinas, sudores nocturnos, inapetencia y estado saburral. TambiÕn se ha observado cµmo los
tripulantes al llegar de lÚnea al hotel, se han ido a cenar con la tripulaciµn y
cuando han regresado al hotel, bien en el bar o bien en el hall han seguido
tomando algunas copas mÃs. Ustedes dirÃn "no solamente estamos nosotros tomando
unas copas, sino el resto de la tripulaciµn auxiliar ...". Pero, yo les contesto
que el hecho de que un auxiliar no vaya sereno y descansado al aviµn, no tiene
mayor transcendencia que daþar la buena imagen de empresa, pero ustedes que
llevan la responsabilidad de todo un pasaje, sÚ que tienen la obligaciµn de ir
completamente sobrios y descansados para desempeþar su trabajo, pues
precisamente su labor es una de las pocas que no admite equivocaciones, pues un
error de ustedes trae consigo poner en peligro la vida del pasaje, y para ello
no existe una segunda oportunidad. En general, existen dos tipos de
personas: El que nace tonto y el que nace con sentido comºn. El primero, como no conociµ otro
entorno, fue feliz en el medio en que se desarrollµ, viviµ y muriµ, y no pasµ
nada. Pero el que naciµ con un sentido
comºn y la presiµn del medio le hizo desarrollarse, conocer, vivir y
experimentar distintas emociones, se manifiesta de una forma completamente
diferente al que naciµ tonto, y si quisiera volver al estado de letargo que
viviµ el primero, serÚa un costo tan sumamente elevado el que tendrÚa que pagar
por ello, que, tarde o temprano se lo cobrarÚan en vida. La persona a medida que va
siendo grande, se va enriqueciendo con nuevas experiencias, y esto por ley de
vida va unido a un mayor bienestar socio - econµmico, pero esto no quiere decir
que sea ajeno a una serie de problemas psÚquico-emocionales. Aquellas personas que tuvieron
unas etapas normales en su vida, las superarÃn sin mayor problema, pero aquellas
otras a las que la presiµn del medio, les ha desbordado y el desarrollo
socio-econµmico que han obtenido en su vida profesional, y si no han adquirido
una madurez psÚquica, entran de lleno sin darse cuenta en un campo conflictivo. REACCI0NES 1. Evasiµn de su mundo. ¢CuÃntos tripulantes desean
salir de lÚneas?. El salir de lÚnea tiene dos vertientes, una el realizarse
dentro de su profesiµn y otra el intentar salir de un entorno que les agobia.
Claro està para muchos de ustedes la primera manifestaciµn esta ya superada,
pero la segunda es una huida de la realidad circundante que comienza a
manifestarse precisamente en el momento en que la primera va decreciendo,
creÃndoles un estado aparente de euforia y estabilidad. Eso es lo que la persona
cree, cuando verdaderamente nada mÃs lejos de la realidad. Los tripulantes pueden estar
fÚsicamente en el puesto de trabajo pero mentalmente muy lejos del mismo. Los
estados de Ãnimo difieren de unas personas a otras segºn el tipo de autocontrol,
una persona con un alto sentir tiene tendencia a una mayor estabilidad emocional
y una con baja puntuaciµn significa mayor inclinaciµn a la depresiµn. No entramos en el campo
exhaustivo del significado de lo que es la depresiµn, pero sÚ anotar a tÚtulo
informativo que, puede ser motivado por problemas cotidianos que llegan a
agobiar de tal forma al sujeto que le transforman su estado de Ãnimo y carÃcter. Un tripulante, sintiµ un estado
depresivo en el momento de aterrizar en un aeropuerto espaþol y pudo salir
felizmente del trance gracias a la ayuda de los dos tripulantes restantes. Dicho
tripulante, horas mÃs tarde manifestaba a sus dos compaþeros que el hecho de no
poder reaccionar cuando iba en el aviµn fue sentir una paralizaciµn de reflejos
y lo achacaba a los problemas familiares que le habÚan estado agobiando durante
todo el dÚa. El percance sucediµ en el ºltimo salto que efectuaba aquella
jornada. Los estados de Ãnimo (vamos a
llamarlos asÚ) no cambian de la noche a la maþana, sino que son consecuencia de
problemas que van agravÃndose a medida que va pasando el tiempo. "Si una persona
no aporta una soluciµn al problema entonces forma parte de esa problema". Lo
ideal serÚa que cuando el sujeto notase indicios de inestabilidad, lo comunicase
a los servicios mÕdicos de la compaþÚa, para que Õstos a su vez pudiesen poner
los medios necesarios para que dicho problema se solucionase de lleno en sus
comienzos. Ahora bien, como, algunos de ustedes pueden ser reacios a este tipo
de consulta dentro de la empresa, y el fin que perseguimos es la seguridad en
vuelo tanto del tripulante como del pasaje, mi opiniµn es que solucionen el
problema aunque para ello tengan que visitar a un profesional ajeno a la
compaþÚa. 2. El segundo interrogante,
trata de la forma distinta de manifestarse dentro y fuera de su trabajo. Hace
unos momentos veÚamos que existen dos tipos de personas, el tonto y el que tiene
sentido comºn. Si a un tonto lo despertamos a
un mundo que es completamente nuevo y sabemos que no tiene le suficiente
capacidad como para poder asimilar nuevas experiencias, en el fondo lo que
estamos haciendo es inhumano pues le estamos variando su sistema de vida. Pero
el que tiene sentido comºn y va acompaþado de una madurez deberÚa tener
capacidad suficiente para medir todos los tipos de situaciones, le sean o no
conocidas en principio. Estos sujetos suelen gozar de una buena imagen en su
vida particular, pero lo que no sabemos es si su mundo circunstancial es el que
le obliga a mantener dicha imagen por lo que al huir de esa realidad y pasar a
un contorno donde le es factible, dado su nivel jerÃrquico, mostrarse de una
forma menos racional, entonces se proyecta agresivo, colÕ rico, irµnico ... y
por quÕ no incluso "LIG0N", AcogiÕndome a esto ºltimo, ya que por lµgica siempre
serà mÃs fÃcil, en caso de intentarlo, ligar con las personas con quien solemos
pasar mÃs tiempo, podrÃn ustedes comprender que tenemos que pensar en que las
escogidas son las tripulaciones auxiliares y, no para aquÚ el asunto, pues ahora
hay que buscar el camino por el cual uno se pueda acercar a dicho entorno en el
que quizÃs no se tienen las mismas costumbres ni los mismos gustos, ni siquiera
el mismo sentido de lo que es divertirse. Pero como dijimos al principio que el
sujeto se manifiesta de una forma diferente, tambiÕn - se proyecta distintamente
para conseguir el fin deseado y esto trae consigo el tener que adaptarse a unas
nuevas vivencias e incluso tener que hacerlas suyas. Es sabido que en las
tripulaciones hay muy pequeþos porcentajes de adictos al alcohol o drogas. Si el
sujeto intenta meterse de lleno en estos grupos, tendrà que seguir de cerca
estas experiencias corriendo el peligro de iniciarse, en un principio con drogas
blandas. A tÚtulo de ejemplo vamos a
explicar la similitud que hay entre un cerebro humano y la memoria de un
ordenador. Si en un "K" hemos introducido unos datos y los almacenamos en la
memoria central, Õstos no saldrÃn a relucir en la impresora hasta que no metamos
nuevos datos que tengan relaciµn con lo registrado. Asi pues, si un individuo tiene
tendencia a fumar drogas blandas, aunque sea esporÃdicamente, la memoria del
cerebro humano no lo olvida jamÃs y le reclama dosis superiores o drogas mÃs
fuertes con el paso del= tiempo. En definitiva estos casos suelen
darse en aquellas personas que no tienen ni madurez ni sentido comºn, y los que
lo tienen y entran de lleno en el caso anteriormente explicado, se manifiestan
con agresividad con sus subordinados e incluso compaþeros de cabina dando lugar
a momentos de gran tensiµn dentro de la misma, olvidando pasos tan fundamentales
como un minucioso chequeo instrumental que puede dar lugar a sucesos
desagradables ya que la lµgica del razonamiento brilla por su ausencia. 3. El tercer punto sobre cuantos
viven de su trabajo y no para su trabajo, diremos que hay sujetos que consideran
el trabajo sµlo y exclusivamente un medio de vida y no les preocupa un mayor
perfeccionamiento dentro de su profesiµn. En estas dos vertientes,
encontramos personas identificadas al 100% con su trabajo y otros que son
inadaptados al puesto de trabajo. Los primeros se ocupan de
alcanzar un mayor perfeccionamiento dentro de su profesiµn y los segundos estÃn
sµlo por el dinero que ganan. La inadaptaciµn trae consigo el
creerse tan autosuficiente que el exceso de confianza en sÚ mismo le hace caer
en fallos primarios y elementales en vuelo. El no tener una plena
identificaciµn con su profesiµn le hace evadirse y esta evasiµn se transforma en
miedo. Segºn los datos de dos CompaþÚas
Americanas, la American Air-Lines y la Eastern, que tienen un departamento de
psicologÚa clÚnica, donde comprueban dos veces al aþo los estados de Ãnimo de su
personal tripulante y esto lo efectºan a travÕs de una serie de pruebas
psicolµgicas como pueden ser el famoso TEST DE ROCHARD. En realidad lo ºnico que
perseguimos con este pequeþo comentario es con seguir que ustedes tomen
verdadera conciencia de la importancia que tiene la seguridad en su trabajo y la
responsabilidad que contraen en el momento de pilotar un aviµn, teniendo por
tanto que dar mÃs importancia que cualquier otra persona a lo que vulgarmente se
le conoce como Altibajos ArtÚculo Abril 2013 GESTIÆN DE LAS OPERACIONES DE
VUELO II III CARACTERëSTICAS PSICOLÆGICAS DEL MANDO 3.- CaracterÚsticas del Mando
3.1.- Autoridad 3.4.- La relaciµn Mando-Subordinado 3.4.1.- Dependencia 3,5,- Integraciµn 3.- CARACTERëSTICAS DEL MANDO 3.1.- Autoridad
QuizÃs podamos plantearnos en primer lugar la pregunta : ¢los jefes nacen o se hacen?
Durante el primer tercio del siglo pasado era comºn la idea
de que la autoridad era una caracterÚstica innata de determinadas personas. Como
consecuencia de este criterio se han publicado numerosos trabajos en los que se
indican los factores esenciales del verdadero jefe. Posteriormente los estudios
han ido encaminados a averiguar la conducta de los Jefes.
No parece que haya un solo patrµn fundamental de cualidades y
caracterÚsticas personales de todos los Jefes. Lo que no quiere decir que la
personalidad de estos carezca de importancia.
Son distintos los requisitos de un jefe en una empresa, de
los exigidos para un mando militar. Incluso son diversos los requisitos para
empresas diferentes e incluso dentro de la misma empresa, pensemos por ejemplo
en las diversas funciones a. realizar (producciµn, administrativa ... ).
A veces se han seþalado como esenciales, para ser jefes,
ciertas caracterÚsticas que no nos sirven para diferenciar al verdadero jefe del
que no lo es. Por ejemplo la ambiciµn : puede encontrarse no solo en el Jefe
sino tambiÕn en .muchos otros miembros de una empresa.
Hay factores esenciales para el mando que pueden aprenderse,
por ejemplo la capacidad de planificar, aceptar responsabilidades. Estos
factores no se heredan, ni es preciso para adquisiciµn que se posean especiales
caracterÚsticas innatas.
Podemos considerar que hay por lo menos cuatro factores
principales que deben tenerse en cuenta para que exista autoridad. Estas depende
de las caracterÚsticas de :
1) El propio Jefe
2) los subordinados
3) La organizaciµn (empresa)
4) El medio en que se desenvuelve (social, econµmico ...)
Las cualidades personales para que sea efectiva la actividad
del Jefe, varÚan en funciµn de los otros factores.
La consecuencia do lo anterior, es que la autoridad no es una
caracterÚstica del individuo sino la relaciµn estos cuatro factores. Es decir,
la autoridad es una relaciµn.
Los tipos de mando que son aceptables en una compaþÚa van a
depender de las directrices dadas por la alta gerencia. Una nueva legislaciµn
social, los cambios del mercado nuevos valores sociales. etc, pueden obligar a
revisar el tipo de se requiere.
De lo anterior deducimos que una autoridad eficiente depende
de que el jefe innatas que puedan valer en todas las ocasiones, y que las
cualidades necesarias, pueden ser adquiridas por individuos completamente
distintos.
3.2 - Cualidades del Mando
En el proceso so do selecciµn del piloto tratamos do buscar en el aspirante,
entre otros, los siguientes aspectos fundamentales de su personalidad : Su actitud Sus motivaciones (positivas y negativas) La calidad de su vocaciµn y su capacidad de liderazgo
Ahora vanos e referirnos brevemente al primero y al ºltimo factor.
Respecto a la estabilidad emocional, solo diremos que por ejemplo una persona
iracunda es una persona peligrosa, tambiÕn lo son el sºper ansioso y la persona
que se siente poco importante, es decir, que tiene un sentimiento de
inferioridad.
El sujeto inestable emocionalmente tomarà decisiones poco objetivas, se
precipitarà o tardarà en decidirse, es decir, no tendrà en cuenta la realidad,
tambiÕn su capacidad de improvisaciµn estarà afectada por esta falta de
objetividad. En cuanto a su capacidad de liderazgo, es
importante conocer si los espirantes tienen capacidad para influir, es decir,
sus dotes de dirigir y motivar a los demÃs. AdemÃs se observan otros aspectos
relacionados con esto, como el control de si mismo etc. Se trata pues de ver en que medida el aspirante
puede cumplir la doble misiµn de Comandante y lÚder natural del su grupo de
trabajo. Por otra parte, se han seþalado como
caracterÚsticas mas relevantes del mando en las empresas, las siguientes: Efectividad : Planear, decidir bien, ordenar, saber
hacer trabajar a la gente. Trato con los demÃs : apoyar y dar la cara por los subordinados, amabilidad,
estimular el progreso . Actividad : actuar, sugerir mÕtodos e ideas nuevas, delegar detalles. Dotes de mando directo : mandar explicando, dar buen ejemplo y tener palabra,
juzgar bien a los demÃs e informar a los subordinados de como van, 3.3.- Estilos de Mando Se ha hecho clÃsica la clasificaciµn de los tipos
de mando que ponemos a continuaciµn : Parte del supuesto que el jefe fundamentalmente
tiene dos parÃmetros . - Los objetivos a lograr (productividad) - Los medios humanos (equipo de trabajo) Debe existir un equilibrio entre dichos factores,
si existe una inclinaciµn hacÚa cualquiera de ellos, el otro se resentirÃ. El
jefe integrador es el que consigue que su energÚa se distribuya entre ambos
adecuadamente. Partiendo del grado en que ambos factores estÃn
presentes se ha llegado a establecer los cinco estilos de mando siguiente : - Jefe autoritario - Jefe protector - Jefe indeciso - Jefe compromiso - Jefe integrador El Jefe Autoritario.- ( TambiÕn denominado
explotador). Piensa que existe una contradicciµn entre conseguir
una alta productividad y las necesidades del personal, sacrificÃndose a estos
para conseguir los objetivos. Es un esclavo del trabajo y se considera obligado
a hacerlo todo Õl. Su lema es " obedecer y callar", ya que las
personas tienen repugnancia hacia el trabajo y hay que robustecer la
autoridad. Los subordinados actºan bajo el temor. Consecuencia de ello es que disminuya
la calidad del producto o servicio y la integraciµn de los subordinados
En caso de conflicto entre los subordinados o de estos con Õl, se reprime con mano dura. Todo ello
genera hostilidad. Jefe Protector.-
Como en el caso anterior, se parte de que los intereses de la producciµn se
oponen a los intereses de las personas, pero este tipo de jefe piensa quo las
personan estÃn por encima de los intereses de la productividad. Y como las
personas necesitan ser ayudadas, recurre a la persuasiµn. Es tolerante con las faltas, los objetivos son
elaborados de comºn acuerdo con los subordinados, su lema es que la empresa ha
de ser una gran familia. En los
conflictos apela a los sentimientos y a la razµn no a las µrdenes duras, hay una
actitud paternalista y protectora. Consecuencia do lo anterior es que la producciµn
sufre y los conflictos son enterrados, no resueltos. El Jefe Indeciso.- Como en los dos casos anteriores, tambiÕn parte de
la incompatibilidad entre las necesidades de la producciµn y del personal, pero
no se inclina por ninguno de los dos. Su actitud es rutinaria de mero
espectador, en definitiva predomina la pasividad. Ni busca la autoridad ni la amistad con los
empleados, no quiere responsabilidades, echa las culpas a otros. No tiene mÃs
objetivo que su seguridad. Intenta evitar los conflictos, retrasa la respuesta a
un asunto Naturalmente una empresa basada en este estilo de mando desaparece. El Jefe Compromiso.- Tiene interÕs por el personal y por la producciµn,
obtiene una producciµn (o presta un servicio) aceptable o incluso excelente,
basado en buscar las soluciones posibles en el compromiso; utiliza la lµgica y
la persuasiµn, anima y motiva. Los subordinados saben quÕ se espera de ellos,
mantiene la disciplina pero con comprensiµn, marca objetivos proporcionados a la
capacidad media de las personas, se anima la mediocridad en todo, la empresa
tiende a ser burocrÃtica y legalista. En sus relaciones con el personal
prefiere el contacto directo, con sus superiores es oportunista y diplomÃtico.
Al decidir procura captar la opiniµn de la mayorÚa. Trata de evitar los
conflictos, aceptando un termino medio. Una de las consecuencias de este estilo
de mando, es que la empresa quedarà atrasada en comparaciµn con las otras. El Jefe Integrador.- Concede gran importancia tanto al personal como a
la producciµn, no considera ambos intereses cono contrapuestos, sino que se
pueden unir y trata de crear una mentalidad dirigida hacia la eficiencia. Se
preocupa mucho do la motivaciµn de sus subordinados y responsabiliza a cada uno
de lo que hace consiguiendo que los subordinados se sientan implicados en el
objetivo final. Cuando hay faltas se preocupa sobre todo por
encontrar las causas y no defiende falsos criterios por amor propio, por tenor
razµn. Respecto a la toma de decisiones, es participativo. Tiende a resolver los
conflictos haciÕndoles frente, no a evitarlos. La consecuencia de este estilo de mando es la
mejora de los beneficios, creatividad, eficacia del trabajo en grupo y ausencia
de conflictos. 3.4.- La Relaciµn Mando- Subordinado.- Habitualmente el Jefe es el centro de la atenciµn
de sus subordinados. Por una parte, su palabra pesa mÃs que la de ellos, por
otra, generalmente es mÃs capaz en algºn aspecto. Por esta razµn le es difÚcil
no suscitar en los subordinados, al menos en algunos, una variedad de
sentimientos que no parecen tener nada que ver con la relaciµn de Jefe y
empleado. Con frecuencia se encuentra que el mando genera en
los subordinados sentimientos de envidia, necesidad de atenciµn personal, deseo
do ayuda y asistencia, anhelo de elogios, etc., manifestÃndose por tanto deseos
de confiar Sus dificultades a ese hombre cuya atenciµn o interÕs personales le
complacen, cuyo elogio desea y cuya crÚtica teme. En definitiva tales
sentimientos no son diferentes de los que se tienen por el padre. 3.4.1. Dependencia.- La dependencia. de un mando provoca sentimientos
satisfactorios es grato que lo atiendan a uno, sentirse seguro. Pero tambiÕn
provoca descontento, supone limitaciµn de la libertad, sujeciµn a influencias
que muchas veces son arbitrarias, o por lo menos asÚ se consideran. TambiÕn la
independencia produce satisfacciones. Es agradable tomar decisiones por propia
cuenta, llevar una vida personal. Ahora bien, la independencia encierra riesgos. En todos los aspectos de la vida dependemos unos de
otros para realizar nuestros objetivos. Al incorporarnos a una organizaciµn
o empresa nos colocamos en una relaciµn de este tipo. No son solo los subordinados quienes dependen de
sus superiores en la empresa para conseguir sus objetivos personales, tambiÕn
los mandos tienen que cortar con los de abajo para conseguir los suyos, asÚ como
los de la organizaciµn. Por ºltimo, la relaciµn existente entre el personal de
lÚnea y el administrativo o de servicio es tambiÕn de dependencia. Esta situaciµn de interdependencia, junto con la
necesidad do una mayor eficacia en los resultados, influyµ decisivamente en el
cambio de los mÕtodos de direcciµn, pues el uso exclusivo de la autoridad no
bastaba para conseguir los objetivos. Es decir, se vio la necesidad de
otros recursos, completando la autoridad con la persuasiµn Esto no quiere decir que la autoridad :haya de ser
abandonada, lo que producirÚa el desorden, que conviene que sea utilizada can
menos intensidad. En numerosas ocasiones es posible recurrir al
convencimiento de las personas para logran una efectividad, que con el recurso
de la autoridad no se conseguirÚa. 3.4.2.- Participaciµn y Decisiµn
La participaciµn es uno de los temas mÃs debatidos.
Con respecto a ella hay diversas posturas, entre las que se cuentan desde el
considerarla como una fµrmula mÃgica, con la que se acabarÃn todos los
conflictos, hasta. el formado por los que piensan que es una abdicaciµn por
parte de la gerencia El problema de la participaciµn està muy ligado al
de la decisiµn. Un mando eficaz debe tomar decisiones razonables, pero para que
una decisiµn sea efectiva. debe ser eficientemente ejecutada y una decisiµn se
puede ejecutar con mÃs eficiencia si se acepta emocionalmente por las personas
que van a llevarla a cabo. En el pasado se ha dado mayor consideraciµn a la
calidad de la decisiµn que a su aceptaciµn. Se valoraron bastante las soluciones
de los problemas de la organizaciµn cientÚfica del trabajo relacionados con los
mÕtodos de trabajo, planificaciµn etc, que las soluciones y los problemas
de las relaciones humanas. Para la calidad se crearon departamentos tÕcnicos.
Sin embargo en los ºltimos aþos se va dando gran importancia al problema de la
aceptaciµn. El grado de la participaciµn vendrà dado en funciµn de diversos
factores: la calidad del problema, la experiencia de los subordinados y la
destreza del mando. 3.4.3.- Clima de la Relaciµn
El Jefe debe tener interÕs por las personas y estar
emocionalmente equilibrado. Hay una correlaciµn positiva entre la actitud de
interÕs por los subordinados y la productividad y espÚritu de trabajo de estos. El ambiente que crea el superior es mas importante
que el tipo de autoridad. Puede ser autocrÃtico o democrÃtico, frÚo o duro de
tratar, pero estas caracterÚsticas personales tienen menos valor que su actitud
hacia los subordinados. La confianza en el hombre es la tendencia actual de
los modernos sistemas do direcciµn. Estos se basan en la libertad para actuar y
por lo tanto en la posibilidad de cometer errores, lo cual es normal, ya que el
error es una fuente indispensable de conocimiento y trae como consecuencia un
reajuste del comportamiento. se opone a la concepciµn de los sistemas
tradicionales que parten de la base de que la se deben consentir errores, y como
el hombre no sabe discernir lo que le conviene, hay que protegerle contra los
riesgos de errores por un sistema de normas considerando ademÃs que una decisiµn
es tanto mejor cuanto mÃs elevado es el nivel en que se toma. En la relaciµn mando-subordinado, es el primero
quien, salvo casos especiales, determina la calidad de la relaciµn. Es decir,
que el superior ejerce mÃs influencia que el subordinado en la Úndole de la
relaciµn. Y esto porque està en su mano el que los subordinados puedan realizar
sus propias aspiraciones. Para que se den las condiciones de seguridad que
precisa el subordinado no basta una atmosfera de aprobaciµn sino que ademÃs es
preciso que sepan claramente que se espera de ellos respecto a su trabajo
(deberes, responsabilidades como lo realizan), tambiÕn deben saber de antemano
los cambios que pueden afectarle. Son tambiÕn requisitos indispensables, que haya una
disciplina consistente ya que si no hay disciplina hay insubordinaciµn asÚ como
que los subordinados cuenten con el respaldo del jefe, que si no habrà la
tendencia a escurrir el bulto, a no aceptar responsabilidades 3.5.- Integraciµn Tradicionalmente se habÚa considerado que el hombre
es perezoso para el trabajo, teniendo que ser obligado a trabajar obligado por
la fuerza, , que prefiere ser dirigido, no quiere responsabilidades y sobre
todo, desea seguridad. Hoy dÚa se van desechando tales puntos de vista, y
manteniÕndose actitudes mucho mas positivas. El procurar satisfacer las necesidades
individuales, demostrÃndose un autentico interÕs por los subordinados son,
entre otros, factores que estimulan a las personas, elevan la moral, evitan
conflictos y mejoran el rendimiento. Se trata pues de integrar a los hombres y a
los grupos de la empresa en un objetivo comºn ArtÚculo Marzo 2013
GESTIÆN DE LAS OPERACIONES DE
VUELO I
I ASPECTOS GENERALES
1.- PsicologÚa del Mando
II LA MOTIVACIÆN. EL GRUPO SOCIAL.
2.1.- La Motivaciµn
2.1.1.- Frustraciµn
2.2.- Los Grupos Sociales
2 .2.1,,- Normas del grupo
III CARACTERëSTICAS PSICOLÆGICAS DEL MANDO
3.- CaracterÚsticas del Mando
3.1.- Autoridad Jefe Autoritario
Protector
Indeciso
Compromiso
Integrador
3.4.- La relaciµn Mando-Subordinado
3.4.1.- Dependencia
3,5,- Integraciµn I.- PSICOLOGëA DEL MANDO Aun cuando las atribuciones y
responsabilidades del Comandante de Aeronave vienen determinadas por las leyes,
nos vamos a referir ºnicamente al problema psicolµgico del mando. Mandar no consiste,
psicolµgicamente hablando, en usar de la autoridad
conferida por la ley. Cuando en psicologÚa se habla de mando, se piensa, mas bien, en
las aptitudes del lÚder para integrar
a los miembros del grupo para conseguir los fines comunes; esto es lo que se
denomina dotes de mando. Con este fin, trataremos los aspectos bÃsicos de la conducta, tales como la
motivaciµn, la
frustraciµn y el grupo social; y a
continuaciµn entraremos mas propiamente en psicologÚa del mando, analizando
la autoridad, la dependencia, los estilos de mando, etc. No obstante, estos aspectos generales del enfoque
psicolµgico, han de ser
aplicados a las especiales circunstancias del trabajo del Piloto. El ejercer las
funciones de mando sobre personas que normalmente estÃn a. sus ordenes solo
unas horas, incide de una manera decisiva en sus posibilidades de actuaciµn, que unas veces facilitaran su tarea, pero
quizÃs las mas la
dificultaran. AsÚ por ejemplo, la naturaleza especifica de muchas de las decisiones
que ha
de tomar, no permiten un mando participativo, ni puede delegar mas
responsabilidades que las que estÃn marcadas. Y la existencia bajo su
supervisiµn directa de dos grupos de trabajo con misiones muy diferentes, le
exigen una gran capacidad de adaptaciµn y conocimiento de las personas. Estos y otros aspectos (por ejemplo, los legales),
configuran la figura del Comandante con perfiles muy especÚficos, que lo separan
de la de un mando tÚpico empresarial. Por tanto no se le pueden aplicar
Úntegramente las modernas teorÚas de direcci6n de hombres en la empresa. Pero
ello no obsta para que sean discutidas e incluso buscada cual puede ser su
posible aplicaciµn. Vamos a ver seguidamente algunos aspectos de la
conducta (individual y social) en el trabajo, es decir, de las relaciones
humanas en la empresa. Sin embargo la brevedad de la exposiciµn nos obliga a
prescindir de temas tan importantes como la adaptaciµn del hombre a la tarea y
de la tarea al hombre, los incentivos, etc. Es decir, nos ocuparemos
preferentemente de aquellos aspectos en los que el mando tiene una influencia
mas directa. II.- LA MOTIVACIÆN. L0S GRUPOS SOCIALES 2.1 .- La motivaciµn 2.1.1.- Frustraciµn Podemos considerar que hay dos elementos bÃsicos en
la situaciµn de motivaciµn : una necesidad (impulso o deseo) y un objetivo
(incentivo o fin). Debe haber una necesidad y un incentivo adecuado para quo se
produzca la conducta. La fuerza de las necesidades y de los incentivos
varia de momento a momento y de individuo a individuo. La presentaciµn del mismo
incentivo producirà una situaciµn de motivaciµn mas fuerte en individuos en los
que la necesidad es intensa, que en los individuos en los que la necesidad es
mas dÕbil. Podemos deducir por tanto, que la intensidad de la motivacion puede
alterarse por cambios en la necesidad o por cambios en el incentivo. Por otre. parte, el hombre es un animal
insatisfecho, en cuanto queda satisfecha, una de sus necesidades, tendrà otra
para la que exija el mismo trato. El esquema es interminable, no se interrumpe
desde el nacimiento hasta la muerte. El hombre esta constantemente esforzÃndose
por satisfacer sus necesidades. La conducta tiene un sentido o propµsito
determinado. este propµsito es la anticipaciµn de alcanzar ciertos objetivos
por medio de formas aprendidas de conducta, es decir, es adaptable. La
calidad de la adaptaciµn se pone en juego : cuando dos o mas posibles conductas conducen a incentivos
diferentes, incluso satisfaciendo algunas veces distintas necesidades, y tambiÕn
cuando un obstÃculo bloquea o impide que una conducta aprendida sea expresada. En
el primer caso
debemos decidir el camino a seguir, en el segundo debemos buscar una soluciµn. Si el incentivo deseado no se alcanza se
experimenta un fracaso es decir, una frustraciµn; si se alcanza se satisface la
necesidad. Sin embargo el Õxito y el fracaso no determinan por si solos si la
respuesta es adaptada o no. La conducta no es necesariamente inadaptada cuando
fracasa en conseguir el objetivo anticipado. La conducta motivada es un medio
para un fin; en cambio la conducta frustrada es un fin en si misma, porque las
consecuencias de tal conducta no influyen sobre su carÃcter bÃsico. La. conducta
motivada acaba cuando el incentivo se alcanza, y en cambio, la conducta
frustrada se consume en ella, misma. La primera da lugar a una saludable
actividad no emocional, variable: y constructiva, pero cuando una situaciµn
llega a ser de frustraciµn para el individuo, su conducta sufre un cambio, se
torna muy emocional y falta de razµn, es decir, se convierte en estereotipada: y
destructiva. Las principales caracterÚsticas de la conducta
frustrada son : la, agresiµn, la regresiµn y la fijaciµn. Ejemplos de las mismas
en la vida de las empresas son : a) de la agresiµn : criticas excesivas, quejas
frecuentes, averÚas, el absentismo, b) de la regresiµn: perdida del control emocional
(tal es el caso del alumno que durante una clase "suelta los mandos"). la
tendencia al rumor, los jefes que rehºsan delegar responsabilidades o son
indecisos para cosas sencillas o no pueden distinguir entre solicitudes
razonables o irrazonables. c) de la fijaciµn ; los individuos incapaces de
aceptar cambios. 2,1.2.- Las necesidades Los impulsos o necesidades : Estos forman una
jerarquÚa, por orden de importancia. En el nivel inferior se encuentran los
denominados impulsos fisiolµgicos o necesidades orgÃnicas, que tienen una
extraordinaria importancia si no estÃn satisfechos, si el estomago esta vacÚo,
las necesidades de "status" prestigio o amor (salvo excepciones), pasan a un
segundo termino, por el contrario, cuando una persona satisface adecuadamente
sus necesidades alimenticias, el hambre deja de ser una necesidad importante. Lo
mismo ocurre con las demÃs necesidades fÚsicas. La necesidad satisfecha ya: no
estimula la conducta del hombre. Cuando las necesidades orgÃnicas empiezan a
estar satisfechas, comienzan a dominar la conducta humana las necesidades de
orden superior, es decir empiezan a motivarla. Se trata de las necesidades de
seguridad, protecciµn contra el peligro, etc. Para el empleado de una empresa las necesidades de
seguridad pueden adquirir para Õl una gran importancia. La injusticia de un
jefe, la conducta que refleja favoritismo asÚ como las decisiones imposibles de
predecir de la autoridad pueden ser poderosos elementos motivadores de las
necesidades de seguridad en la relaciµn laboral a todos los niveles, desde el
simple obrero a los mas altos puestos. Satisfechas las necesidades materiales y de
seguridad, sus necesidades sociales adquieren importancia principal En este grupo se encuentran : la de asociaciµn, la
de sentirse miembro de un grupo, la de dar y recibir afecto y amistad. Muchas
veces se piensa que estas necesidades constituyen un peligro para la empresa.
Esta demostrado que un grupo de trabajo muy unido puede, en las debidas
circunstancias, ser mas eficiente que los mismos individuos trabajando
aisladamente, y sin embargo, con frecuencia priva el temor a que el grupo sea
hostil para los objetivos del jefe, y este se empeþa en controlar la conducta de
los mismos de manera opuesta a la tendencia natural de las personas a agruparse.
En este caso las personas, suelen mostrar formas de conducta que tienden a
frustrar los fines de la empresa, mostrÃndose hostiles y sin deseos de cooperar. En el nivel siguiente, encontrarnos las denominadas
necesidades del yo, tanto en lo que se refiere al concepto personal (necesidades
de autonomÚa, confianza en si mismo, perfeccionamiento), cono las referentes al
propio prestigio (de reconocimiento del propio valer o categorÚa, de estimaciµn
y respeto por parte de los compaþeros). Este tipo de necesidades, a diferencia de los que
ocurre con las necesidades inferiores (fÚsicas, de seguridad y sociales),
normalmente no estÃn satisfechas, buscÃndose cada vez mayor satisfacciµn de las
mismas, una, vez que el hombre ha advertido y sentido su importancia. Sin
embargo el mundo de la empresa brinda escasas oportunidades para su satisfacciµn
en los niveles inferiores, piÕnsese por ejemplo en las personas que ocupan
puestos en una cadena de producciµn en serie. Por ultimo, estÃn las necesidades de realizaciµn
personal. El hombre siente el impulso de desarrollar sus propias facultades, de
progresar continuamente. Con frecuencia este tipo de necesidades no estÃn
desarrolladas, debido a que las inferiores no estÃn adecuadamente
satisfechas. Lo mismo que ocurre con las necesidades orgÃnicas
cuando no estÃn satisfechas, es decir, el hombre esta dÕbil, tambiÕn lo esta si
no estÃn satisfechas las necesidades superiores, y esto se reflejara en su
conducta, esta se mostrara como apÃtica, hostil, negÃndose a acertar
responsabilidades etc. Al elevarse el nivel de vida, como consecuencia del
desarrollo de un paÚs, las empresas cubren las necesidades orgÃnicas y de
seguridad, desplazÃndose la fuerza motivadora hacia las necesidades sociales y
de la personalidad. 2.1.3.- El Conflicto A veces se presenta el problema de tener que elegir
entre dos tipos de motivaciµn. Existen tres clases de conflicto : El primer tipo
es un conflicto entre dos atracciones positivas. Por ejemplo, el adolescente que
duda entre hacerse piloto o marino. Cuanto mayor sea la igualdad de equilibrio
entre las fuerzas de atracciµn, mas difÚcil serà la ejecuciµn, Un segundo tipo
de conflicto de motivaciones se asocian incentivos positivos y negativos con la
misma acciµn, por ejemplo, el estar "destacado" no suele gustar por las
incomodidades que produce, por ello en tal situaciµn se incrementan los haberes
adecuadamente y hay muchas personas a las que les interesa.. Por ultimo, hay un
tercer tipo cuando dos incentivos negativos actºan en direcciones opuestas, en
este caso la persona ha de escoger el menor de los dos. Tal seria el caso de un
piloto que debe escoger entre volar un aviµn poco seguro o perder el empleo,
cualquiera de las dos soluciones son desagradables. El mando, al poder introducir premios y sanciones
en una situaciµn, puede influir sobre las elecciones que hagan los subordinados,
los premios harÃn que las personas elijan. hacer cosas agradables, y las
sanciones desalentaran conductas que de otra forma se inclinarÚan a efectuar. El
mando debe procurar dar la posibilidad de elecciµn entre dos alternativas ya que
una persona se siente tiranizada cuando se le niega toda posibilidad de
elecciµn. A veces surgen desavenencias porque los empleados
ponen reparos a un cambio por ejemplo en el sistema de trabajo, aun cuando ello
suponga una mejora. Con frecuencia hay en esta conducta un problema emocional,
basado en miedo u hostilidad a la direcciµn. La participaciµn de los mismos en
el proceso de cambio, ayudara sensiblemente a que tal resistencia disminuya. La resistencia al cambio a nivel personal, seria
por ejemplo el caso del piloto que es incapaz de cambiar a un tipo de aviµn mas
evolucionado; aquÚ vemos como la capacidad de adaptaciµn influye decisivamente
sobre las posibilidades de las personas. 2.1.4.- Factores que motivan
y eleven la moral. Nos vamos a referir brevemente a algunos puntos
importantes, pero de todos conocidos, para la puesta en practica de la
motivaciµn. Excluimos los que el mando no puede utilizar directamente por estar
ya establecidos, como la remuneraciµn, etc. La utilizaciµn del elogio es una forma de
satisfacciµn del yo. Con frecuencia ocurre que si bien el Jefe quiere que se
trabaje bien, se olvida de expresar su opiniµn cuando tal ocurre y, sin embargo,
ataca los errores porque estos le frustran en su programa de trabajo. Con frecuencia se utiliza mas el incentivo negativo
que el positivo, es mas fÃcil castigar que motivar positivamente. El castigo es
efectivo para motivar la evitaciµn de una conducta, pero plantea algunos
problemas que conviene considerar. El castigo puede frustrar a la persona,
especialmente si es emocionalmente inestable. La amenaza de castigo pone de
relieve lo que no se debe hacer y es mejor seþalar lo que se debe hacer. TambiÕn
produce temor y reduce la aceptaciµn de ideas. Todo lo cual significa que el
castigo debe utilizarse reflexivamente. Para conseguir la cooperaciµn de las personas, es
necesario un clima de tolerancia, lo cual no se logra regaþando constantemente
por pequeþos detalles. La justicia del Jefe es otro factor importante.
Cuando a ciertas personas se otorgan privilegios especiales o se muestra
favoritismo, las otras se desmoralizan. El sentimiento de que se esta progresando hace
subir el espÚritu de equipo, pero para que sea experimentado como tal es
necesario que las personas conozcan la mejora. Se ha encontrado que existe una alta
correlaciµn
entre el entusiasmo del mando y el de los subordinados. Este es un punto
quizà no suficientemente valorado, se ha dicho que el ingrediente bÃsico del
Õxito es el entusiasmo, y en la aviaciµn con mas intensidad por !as
responsabilidades que comporta, piÕnsese por ejemplo en la necesidad de asegurar
!a vida de las personas.
2.4,5.- La Motivaciµn y los Tripulantes. En el piloto que empieza, su motivaciµn para el
vuelo (como para cualquier otro comportamiento), rara vez se deriva de una sola
motivaciµn. Junto al "placer" de volar, que es una de las motivaciones
principales, hay otras tales como la autorrealizaciµn y la afiliaciµn. Pero
dichas motivaciones deben ser mantenidas con experiencias satisfactorias y
tratando de que no surjan motivaciones de adversiµn. (Por ejemplo, miedo al
vuelo). En el transcurso de la vida, los distintos
cometidos a desarrollar por cada uno de los miembros de la tripulaciµn, algunos
aspectos del vuelo (por ejemplo largas ausencias), y la personalidad de
los mismos, incidirÃn de distinta forma sobre la motivaciµn surgiendo
situaciones conflictivas. El comandante al tener una gran identificaciµn con
su profesiµn elimina con mas facilidad los conflictos, no logrÃndolo con la
misma facilidad los restantes miembros de la tripulaciµn tÕcnica. La azafata al
no tener basada su motivaciµn en una participaciµn tÕcnica y por problemas
derivados de su condiciµn de mujer, es la mas expuesta a descompensaciones
psicolµgicas. Es decir, la calidad de las motivaciones profesionales y la
directa participaciµn en el trabajo aÕreo figuran entre las mejores defensas
contra las descompensaciones neurµticas.
2.2.- Los Grupos Sociales Cada uno de nosotros pertenece a una serie de
grupos, entre ellos se cuentan los siguientes : familiar, profesional,
religioso, etc. Psicolµgicamente un grupo es un conjunto de
personas que tienen una interacciµn. El rasgo mas caracterÚstico en todos los
grupos es su condicion basica de tipo emocional. Esto provoca en el grupo
necesidades de comprobaciµn de constatar que existen en el grupo determinados
requisitos que la vida emocional requiere. Nuestra conducta afecta al grupo y
este afecta y controla nuestra conducta. 2 .2.1,,- Normas del grupo La forma mas intensa de influir el grupo sobre las
personas es a travÕs de las normas de grupo. Podemos decir que una norma es un
modelo de conducta. Un grupo puede "esperar" cierta conducta de sus miembros y
desaprobar la conducta de una persona si esta no se ajusta a lo que se espera de
ella. Como casi todos tenemos el deseo de ser aceptados por los demÃs, tendemos
a realizar lo que el grupo exige de nosotros. Como las personas pertenecen a
mºltiples grupos, han de cumplir mºltiples conjuntos de normas, y en el caso de
que no las cumplan, sufrir la desaprobaciµn de los miembros del grupo cuyas
normas deje de cumplir. Cuanto mayor sea la relaciµn o interacciµn, mayor serÃ
la tendencia a adoptar formas comunes de interpretar el mundo y patrones comunes
de conducta para cada miembro del grupo. Existen dos buenas razones que explican porque las
personas tienden a adaptarse a las normas de grupo. Una de ellas ha sido ya
comentada . Las personas que van contra las normas sufren la desaprobaciµn
social o algºn otro castigo. Nuestro deseo de aprobaciµn social incluso se
manifiesta ante personas completamente ajenas al grupo. La otra razµn que tambiÕn actºa obligÃndonos a
conformarnos a las normas del grupo, consiste en que los sujetos tienden a
considerar que las opiniones de su grupo son las correctas o por lo menos las
que mas se acercan a la verdad Las dos razones expuestas actºan en la mayor parte
de las situaciones en las que las personas se adaptan a las normas del grupo. Existen tambiÕn otros factores que afectan a la
conducta adaptativa al grupo : Atracciµn hacia el grupo; acuerdo general
percibido en el grupo y aceptaciµn por el grupo. 2.2.2.- Atracciµn hacia el grupo
Cuanto mayor es la atracciµn que siente una persona
hacia el grupo, se halla mas inclinada a conformarse a sus normas. Esto lo
podemos comprobar fÃcilmente ya que generalmente poseemos una opiniµn mas
elevada de las personas que estimamos que de las demÃs. El castigo que podrÚamos sufrir al ser rechazados o
desaprobados por un grupo es tanto mas grave cuanto mas deseamos pertenecer a el 2.2.3.- Acuerdo El que exista mucha o poca concordancia entre los
miembros, afecta a la conformidad. Si hay unanimidad sobre cierta opiniµn
tendemos a adaptarnos mas a esa opiniµn que si se ven discrepancias. La no
unanimidad deja a un sujeto en mayor libertad para expresar sus propias
creencias, aminorando el riesgo de ser desaprobado. 2,2.4.- Aceptaciµn. Liderazgo
El grado segºn el cual un sujeto se siente aceptado o rechazado por
el grupo, determina si una persona se adapta real o ficticiamente al consenso colectivo. Por ejemplo, si
un sujeto se siente
rechazado, solo se adaptarà a las opiniones de la colectividad por el temor
al castigo, aunque interiormente pensara de otra manera. Por el contrario, la persona que se siente aceptada tendera a adoptar las
opiniones del grupo de una. manera sincera. Es decir, la conformidad
originada por el miedo a la desaprobaciµn es solo superficial, no es real.
Por tanto se debe lograr que todas las personas
sientan que sus esfuerzos son importantes ya que cuando una persona se
considera indispensable se inclina mas fÃcilmente a cooperar. En el grupo surge espontÃneamente el
lÚder, a este
se le otorga un margen de
confianza para que decida en su nombre; a su vez el lÚder debe mantener la
cohesiµn
y asegurar la continuidad el grupo.
2.2.5.- Los Grupos en la empresa Un grupo de trabajo tiene una estructura formal, la
establecida por la empresa, y otra informal o espontÃnea, la que resulta de los
intercambios entre ellos. Este grupo, formado para realizar una tarea o un
servicio, tiene un objetivo impuesto por la empresa : cumplir con la mÃxima
eficacia su trabajo.. A esta exigencia, el grupo tendera a responder
estableciendo unas normas como la de fijar determinados niveles de actividad, es
decir, impondrà un control interno sobre sus miembros fijando un rendimiento.
Los miembros que vayan contra esta norma (tanto por exceso de rendimiento, como
por defecto), sufrirÃn la desaprobaciµn social. TambiÕn exigirà el grupo una distribuciµn
equitativa de las tareas, sospechando favoritismos si piensan sus miembros que
la distribuciµn que ha hecho el jefe es arbitraria: Otro tipo de conducta, como
hemos dicho anteriormente, es el resistirse a los cambios Estos tres aspectos citados, control del
rendimiento, deseo de justicia y resistencia al cambio, son una consecuencia de
los lazos que se establecen entre ellos, al mismo tiempo que le sirven de
protecciµn. Un buen jefe es el que partiendo de estos hechos,
consigue elevar el nivel de rendimiento, es justo en el reparto de las tareas y
si hay necesidad de cambios, procura que el grupo intervenga de manera adecuada en ellos. Aunque los fines de los grupos formales y
espontÃneos son diferentes puede hacerse que coincidan, a lo que contribuirà en gran medida el que los jefes de ambos grupos sean la misma persona,
consiguiÕndose asÚ una alta moral de trabajo.
ArtÚculo Febrero 2013 LA COMUNICACIÆN INTERTERPERSONAL
SU NATURALEZA Y SUS FASES Objetivo 1.- Conocer la importancia que tiene la comunicaciµn como fundamento de toda vida social y su incidencia en el clima de la organizaciµn.
En la actualidad se observa una creciente interÕs por el complejo fenµmeno de la comunicaciµn. La sociedad ha empezado a tomar conciencia de la importancia, de
la complejidad y de las dificultades que encierra este fenµmeno de las diferentes esferas de nuestra vida social: problemas de comunicaciµn entre
generaciones, en la familia, en el trabajo, etc. El fuerte incremento de los medios de comunicaciµn hace que cada dÚa recibamos
informaciµn mÃs Ãgil, cuantiosa y que nos encontremos inmersos e influenciados por mºltiples y variados procesos de comunicaciµn a los que, a veces, nos
resulta difÚcil enfrentarnos con cierta coherencia y responder a sus mensajes con criterios previamente elaborados.
A continuaciµn vamos a reflexionar sobre lo que es comunicaciµn y a tratar de conocer algunos de los principios que rigen este proceso.
¢QUE ES LA COMUNICACIÆN ? La comunicaciµn la podremos definir como un proceso por medio del cual una
persona se pone en contacto con otra a travÕs de un mensaje y espera que esta ºltima emita una respuesta, bien sea una opiniµn, actitud o conducta.
Por tanto, la. comunicaciµn es en proceso y puede contribuir a hacer mas eficaces nuestras relaciones con los demÃs.
Comunicarse es
¢Cµmo nos
comunicamos?
La dificultad, y
tambiÕn la riqueza de la comunicaciµn entre las personas se encuentra en el
hecho de que, cuando nos comunicamos lo hacemos con toda nuestra personalidad.
Cuando dos personas se comunican estÃn presentes en ellas sus conocimientos, su experiencia, su modo de ver a las personas, la opiniµn que tienen de sÚ mismos,
etc. La comunicaciµn no es, ºnicamente pronunciar palabras y esperar que ocurra lo mejor. Mas aºn, no es necesario hablar para comunicarse con los demÃs. Cuando en un pasillo, en on
aviµn, en un despacho ... dos personas se encuentran
en silencio, ya se estÃn comunicando; con una simple mirada a la forma de vestir puede que una de ella conozca o intuya algo acerca de la otra.
Queramos o no nos comunicamos
Es imposible vivir rodeados de personas sin
comunicarnos con ellas, la gran diferencia entre hacerlo voluntaria o involuntariamente està en que, cuando nosotros decidimos que queremos
comunicarnos, el proceso es mÃs agradable.
¢Sabemos comunicarnos?
Todos sabemos comunicarnos, aunque esto no significa que siempre lo hagamos bien o de la forma mÃs adecuada.
Saber comunicarse bien no se aprende solamente con la experiencia que vamos
adquiriendo en los procesos de comunicaciµn que mantenemos. Recuerde que
practicar algo no siempre implica perfeccionarlo, "haciendo las cosas
repetidamente mal, sµlo aprendemos a hacerlas mal, no a hacerlas bien".
Toda comunicaciµn està compuesta de varias partes que precisan de armonizarse
entre si para que resulte efectiva. Si no nos ajustamos a unos esquemas bÃsicos
es posible que no consigamos el resultado esperado y lleguemos, incluso, a un
deterioro en nuestras relaciones interpersonales
Las buenas prÃcticas se basan en buenas teorÚas
Existen unas series
de tÕcnicas que pueden ayudarnos a superar los fallos y dificultades que se nos
presentan en nuestras comunicaciones, pero para aprender a manejarnos con ellas
es importante que primero examinemos el PROCESO COMUNICATIVO y descubramos cµmo
funciona y cuÃles son sus principios fundamentales.
Objetivo 1.2.- Conocer cuÃles son los elementos que han de tenerse en
cuenta para que la comunicaciµn resulte efectiva.
ELEMENTOS que intervienen en un PROCESO DE COMUNICACIÆN:
EMISOR------ MENSAJE---- RECEPTOR
* EMISOR: persona que emite un mensaje
* RECEPTOR: persona a la que se dirige el mensaje
* MENSAJE: contenido de la comunicaciµn. Forma que se da a una idea que se da a
una idea o pensamiento que el emisor desea transmitir.
Una vez que hemos decidido quÕ queremos comunicar el paso siguientes consistirÚa
en codificarlo.
CODIFICACIÆN - Una forma de transmitir el Mensaje por parte de quien lo emite.
Cuando queremos transmitir una idea, opiniµn, sentimiento .. tenemos que
utilizar un CÆDIGO para el receptor, y aquÚ es donde empieza el proceso de
comunicaciµn propiamente dicho.
El cµdigo puede estar constituido por:
.- PALABRAS: comunicaciµn verbal o escrita.
No debemos olvidar que las palabras son sÚmbolos y que cada persona las darà un
significado en funciµn de sus actitudes, experiencias y el contexto.
.- EXPRESIONES DEL ROSTRO
GESTOS, DIBUJOS, ETC: comunicaciµn no verbal
.- UNA MEZCLA DE COMUNICACIÆN VERBAL Y NO VERBAL
Elecciµn del MEDIO o CANAL de comunicaciµn
.- Es el vehiculo por el cual el mensaje viaja del emisor al receptor. A la hora de
su elecciµn el comunicador deberà prever las dificultades que puede surgir con
su utilizaciµn.
.- Igualmente, elegiremos la forma (canal) que consideremos mas idµneo para
transmitir nuestro mensaje; por telÕfono, por carta, por el olor,
personalmente... Ya
estamos preparados para transmitir nuestro mensaje. El proceso continua a la
inversa, ahora serà el RECEPTOR quiÕn deberà actuar: descifrara el mensaje y lo
convertirà en una idea.
* DECODIFICACIÆN -Una forma de entender el mensaje por parte de quien loÀ
recibe. Es muy
importante que el receptor entienda lo que el emisor quiere decir con el mensaje
y que conozca su marco de referencia y los propµsitos que alberga.
Hasta aquÚ , el ESQUEMA DEL PROCESO queda como sigue:
EMISOR -> CODIFICACIÆN -> EMISIÆN -> TRANSMISIÆN -> RECEPCIÆN -> DECODIFICACIÆN
-> RECEPTOR Pero,
frecuentemente sucede que la idea que el receptor recibe no sea la que
nosotros tratamos de enviar ya que, en nuestras comunicaciones pueden aparecer
ciertas "barreras", a las que mÃs adelante no referiremos, que dificultan y
distorsionan los mensajes.
Al objeto de paliar en lo posible este problema, vamos a introducir en nuestro
esquema un nuevo elemento: la RETROALIMENTACIÆN o FEED BACK.
* RETROALIMENTACIÆN o FEED-BACK - Es una respuesta por parte de quien
recibe el mensaje, que indica al emisor quÕ y cµmo ha sido recibido.
Con este elemento tan importante y que va a poner de manifiesto nuestra eficacia
comunicativa, podemos completar el esquema de proceso.
EMISOR <=> CODIFICACIÆN <=> EMISIÆN <=> TRANSMISIÆN <=> RECEPCIÆN <=>
DECODIFICACIÆN <=> RECEPTOR
2 - COMO FUNCIONA LA COMUNICACIÆN - INTERFERENCIAS
Como funciona la Comunicaciµn
Objetivo 2.- Conocer los diferentes factores que van a influir en la
comunicaciµn, que pueden producir distorsiones en el contenido de los mensajes y
problemas en nuestras relaciones interpersonales.
La comunicaciµn depende de las personas. Nuestro modo de comunicar y , por
consiguiente. los problemas que se nos presentan en nuestras comunicaciones, van
estrechamente vinculados a nuestra personalidad.
La forma en que una persona percibe su propio mundo, los mensajes que recibe y
la manera en que se comunica con otras personas, se hallan influidas por un
conjunto de factores interrelacionadas que varia de una persona a otra.
En general, las interferencias presentes en nuestros procesos de comunicaciµn,
se manifiestan en distorsiones en la recepciµn o interpretaciµn de nuestros
mensajes. Es decir, en las diferencias que constatamos entre lo que hemos
querido comunicar a nuestro interlocutor y lo que este realmente recibe.
Arco de distorsiµn. A esa diferencia la denominamos el "arco de distorsiµn" de
la comunicaciµn. Viene definido por la diferencia entre lo que trata de
comunicar el EMISOR a lo que oye el RECEPTOR
"SÕ que crees que
entiendes lo que piensas que dije, pero no estoy seguro de si te das cuenta de
que lo que oÚste no es lo que yo querÚa decir".
Debemos ser conscientes de que un nuestros procesos de comunicaciµn existen
mºltiples "FILTROS", tanto en el emisor como en el receptor que llevan a la
distorsiµn del mensaje.
¢DE DONDE PROCEDEN LOS FILTROS QUE INTERFIEREN NUESTRAS COMUNICACIONES?
* Del Comportamiento Verbal.
TODA PERSONA LLEGA AL PROCESO DE COMUNICACIÆN CON:
UN CAMPO DE EXPERIENCIA Si los campos de experiencia del receptor no son los
mismos que los del emisor, no se comprende el significado del mensaje. Cuando
mÃs grande sea el campo de experiencia comºn mÃs eficaz serà la comunicaciµn.
Por lo tanto, estaremos levantando verdaderas murallas de incomprensiµn en
nuestras comunicaciones: - SÚ al
dirigirnos a nuestro interlocutor, lo hacemos sobre cosas o ideas que estÃn
fuera del alcance de su experiencia, es evidente que no nos entenderÃ.
- Si olvidamos que cada persona va a interpretar o percibir los mensajes que
recibe de forma distinta, en funciµn de sus experiencias, de sus creencias,
valores y necesidades.
La experiencia en comunicaciµn Dentro del campo general de nuestra experiencia,
està incluida la referida a nuestras comunicaciones anteriores: cuÃles fueron
los resultados obtenidos, que errores cometimos, cµmo nos sentimos, etc. que
tendrà incidencia en los procesos futuros.
Unas Actitudes. Como consecuencia de las experiencias que vamos acumulando y del
entorno en que nos desenvolvemos vamos elaborando una serie de creencias. Estas
creencias hacen que desarrollemos unas Actitudes que:
- nos condicionan
Compartir Actitudes no necesariamente implica compartir Creencias. Podemos
mantener idÕntica actitud que otra persona ante determinado asunto, pero haber
llegado a ella por razones diferentes.
Actitudes ante la comunicaciµn Tienen gran incidencia e importancia en la
comunicaciµn, dado que, cuando llegamos a ella lo hacemos con unas Actitudes
hacia: - Nosotros mismos: lo que pienso
sobre mi, lo que siento acerca de mi propia imagen. Es
importante tener en cuenta que nuestras actitudes y creencias son parte de
nosotros mismos y por ello somos reacios a cambiarlas a no ser que nos
demuestren que estamos en un error.
Un Componente Afectivo. Cuando nos comunicamos con otra persona le estamos
transmitiendo nuestros Sentimientos: un estado de Ãnimo, una disposiciµn..., y
es precisamente esa parte del mensaje, la que vamos a transmitir con mayor
precisiµn. TambiÕn
cuando el objeto de nuestra comunicaciµn es el de persuadir de nuestro
interlocutor, vamos a dirigir nuestro mensaje hacia la afectividad de nuestro
interlocutor, es decir, hacia sus sentimientos y emociones.
Por consiguiente, los sentimientos de atracciµn o rechazo entre los
interlocutores, hacia otras personas, hacia objetos, situaciones, estarÃn
presentes en toda comunicaciµn interpersonal implicando afectivamente a emisor y
receptor. Sus
dificultades Si siempre fuÕramos conocedores y conscientes de nuestros
sentimientos no surgirÚan problemas en nuestras comunicaciones.
Las dificultades aparecen cuando los sentimientos, de los que no somos
conscientes, se "filtran" por nuestro tono de voz, las miradas, los gestos
(lenguaje no verbal) y, sin darnos cuenta, estamos enviando a nuestro
interlocutor un mensaje ambiguo o dos mensajes diferentes e incongruentes.
La Situaciµn. Cada comunicaciµn se va a desarrollar en una situaciµn determinada
que va a influir en el resultado de la misma.
En toda comunicaciµn se crea una situaciµn nueva y, dependiendo del contexto en
que se desarrolle, del papel social que ocupemos, de nuestro estado de salud y
de Ãnimo, del objetivo que esperemos obtener, etc., vamos a dejar traslucir unos
sentimientos y adoptar unos comportamientos determinados.
No saber o no querer adaptarse a la situaciµn, es decir, mantener una postura de
rigidez, va a ser una barrera fundamental en el proceso de comunicaciµn.
Tener en cuenta la influencia de los factores hasta aquÚ vistos, puede
resultarnos de gran ayuda para conseguir COMUNICACIONES EFECTIVAS, en las que
habremos obtenido los resultados esperados (cambios en tos conocimientos,
actitudes o conducta de nuestro interlocutor) .
FACTORES A TENER EN CUENTA PARA MEJORAR NUESTRO PROCESO DE COMUNICACIÆN
ELEMENTOS
Fuente o emisor.
Factores a tener en cuenta: CaracterÚsticas del emisor
Capacidad comunicativa Disposiciones y actitudes Codificaciµn.
Factores a tener en cuenta: Hacia sÚ mismo Hacia el asunto que comunica Hacia el proceso comunicativo Hacia el receptor Preparaciµn y dominio Posiciµn Contenido Mensaje.
Factores a tener en cuenta: Destinatario (identificaciµn) CaracterÚsticas del mismo Status Fines que propongo Canal.
Factores a tener en cuenta: Apropiado a que, cµmo, a quien Mensaje.
Factores a tener en cuenta: CaracterÚsticas del receptor Experiencia Habilidades Decodificaciµn.
Factores a tener en cuenta: Actitudes Conocimientos Status Receptor.
Factores a tener en cuenta: Que entendÚ (experiencia) Importancia que tiene Para que ArtÚculo Enero 2013 ANêLISIS Y DESCRIPCIÆN DE PUESTOS DE TRABAJO,
Anexo II.- Lista de Chequeo Valoraciµn de la Actuaciµn Profesional .- Confidencial
Instrucciones Le rogamos que cumplimente la hoja de respuestas de cada Informe de Valoraciµn a
partir de este Cuestionario. Para ello, debe marcar con una cruz la casilla que figura bajo la respuesta que
Vd. considera correcta. Utilice lÃpiz o rotulador rojos.
Por ejemplo: Pregunta 10 SI NO X En este caso, Vd.
considera que la respuesta adecuada a la pregunta numero 10 es SI.
En caso de error, tache completaente la casilla equivocada. Seþale luego con la
cruz a respuesta adecuada. Por ejemplo:
Pregunta 90 SI NO X X En este caso, Vd.
considera que la respuesta adecuada a la pregunta nºmero 90 es N0.
Dado el sistema de correcciµn del Cuestionario, es necesario que sean
contestadas todas las preguntas.
Repase el nºmero de orden de las cuestiones al contestar.
1.- Conoce perfectamente las tareas propias de su puesto, y està al corriente de
las innovaciones que se producen. 2.-
Si las circunstancias lo requieren ,sus conocimientos le permiten cubrir
satisfactoriamente varios puestos dentro de su centro de trabajo.
3.- DeberÚa mejorar su imagen y
presentaciµn personal. 4.- Si causara
baja en esta plantilla, el ambiente de trabajo se resentirÚa negativamente.
5.- Sabe como actuar ante problemas difÚciles e imprevistos.
6.- Le faltan aspiraciones para asumir tareas de mayor responsabilidad.
7.- Su capacidad de trabajo supera
ampliamente los lÚmites normales. 8.-
Se observan defectos en la presentaciµn de los trabajos.
9.- DeberÚa adquirir mayor seguridad en su resoluciµn profesional.
10.- DeberÚa consultar mÃs antes de decidir.
11.- Excelente dominio de si mismo. Destaca por su seguridad en situaciones
difÚciles. 12.- En algunas ocasiones se
le ha detectado algºn error, aunque de escasa importancia.
13.- Su interÕs por el trabajo es ejemplar para los demÃs componentes de su
equipo. 14.- Con cierta frecuencia, se
retrasa al entrar en el trabajo. 15.-
Su dedicaciµn es notable, mÃs allà de los horarios establecidos.
16.- Conoce los trabajos mÃs
corrientes de su Secciµn o Departamento.
17.-Està al corriente de las
innovaciones que se introducen y que afectan a la esfera de su actuaciµn
profesional. 18.- Posee excelentes
modales compostura. 19.- DeberÚa
hallarse mÃs dispuesto a colaborar en ciertos momentos.
20.- Comprende rÃpidamente y con pocas explicaciones. Es Ãgil mentalmente.
21.- Sus aspiraciones son mayores que el esfuerzo desarrollado para alcanzarlas.
22.- Muy veloz y dinÃmico. Excelente en cuanto a cantidad de trabajo
(prescindiendo de su calidad). 23.- Es
muy metµdico y preciso en su trabajo.
24.- Evita tomar decisiones. Prefiere buscar el apoyo de un superior o compaþero
25.- Sus decisiones profesionales destacan por la ponderaciµn y la sensatez.
26.- DifÚcilmente acumula tensiµn, incluso en circunstancias comprometidas.
27.- Se ausenta en ocasiones de su puesto de trabajo (aunque los motivos sean
justificados). 28.- Vive personalmente
las vicisitudes del trabajo. Le preocupan los problemas de la Secciµn o
Departamento. 29.- Cuando no tiene una
tarea que le obligue, pierde el tiempo.
30.- Raramente se distrae o ausenta del puesto.
31.-.Domina perfectamente la operativa de su puesto de trabajo.
32.- Posee tacto y flexibilidad ante clientes y compaþeros.
33.- Es algo celoso de sus prerrogativas y tiende al individualismo.
34.- Sus criterios son prudentes e inspiran confianza.
35.- Actºa sin necesidad de supervisiµn, excepto ante problemas difÚciles
36.- Es reacio a procedimientos rutinarios. Propone nuevos mÕtodos que mejoren
su labor habitual. 37.- DeberÚa
esforzarse mÃs para alcanzar el nivel de competencia que actualmente se precisa.
38.- Realiza una cantidad de trabajo considerable, en comparaciµn con los demÃs
compaþeros. 39.- Es muy exacto. Nunca
comete errores apreciables. 40.- Suele
consultar ante cualquier problema que se aparte de la rutina diaria.
41.- Es muy realista en sus opiniones. Destaca por su sentido comºn.
42.- Es animoso y emprendedor. 43.-
Realiza ciertas tareas con mÃs agrado que otras.
44.- Demuestra aspiraciones para
conseguir funciones de mayor responsabilidad.
45.- Con frecuencia, deben recordÃrsele las µrdenes e instrucciones.
46.- Conoce todas las tareas del Departamento a Secciµn. Es capaz de sustituir,
con Õxito, a cualquiera de los denÃs empleados.
47.- Posee excelentes dotes de argumentaciµn y persuasiµn.
43.- Los compaþeros reconocen su amabilidad y apoyo en el desarrollo del
trabajo. 49.- Posee un verdadero
ascendiente sobre sus compaþeros. 50.-
Tiene dificultades cuando se altera su rutina de trabajo.
51.- Aporta muchas ideas y, en
general, aceptables. 52.- Exige mucho
de si mismo. 53.- Su capacidad de
trabajo es satisfactoria 54.- Deberia prestar
mas atenci6n con lo que su exactitud en el trabajo mejorarÚa. 55.-
Solo requiere asesoramiento ante problemas difÚciles. 56.- En el plano profesional, sus opiniones
inspiran confianza. 57.- En ocasiones se deja agobiar por el
trabajo. Acumula tensiµn. 58.- A veces,
utiliza el telÕfono para su uso particular. 59.- Parece poco
complacido por su puesto y funciones (independientemente de su
cumplimiento en el trabajo). 60.- Su
dedicaciµn, durante el horario de trabajo, es continua e ininterrumpida. 61.- Le faltan dotes de persuasiµn ante los superiores y
compaþeros. 62..- Va mas allà de sus
obligaciones para ayudar a otros. 63.- Los
demÃs compaþeros confÚan en el y acuden a consultarle los problemas de
trabajo. 64.- Es reservado y escasamente comunicativo. 65.- Requiere
supervisiµn ante cualquier cambio en las pautas de trabajo. 66.- Le cuesta
adaptarse a nuevas situaciones. 67.- Posee una
inteligencia creadora. Aporta muchas soluciones que inciden en
su labor y en otros puestos de trabajo. 68.-
Destaca por su elevado nivel de aspiraciones y por sus esfuerzos para
superarse profesionalmente. , 69.- El volumen de trabajo que realiza es
inferior al que requieren
las circunstancias actuales. 70.- Presenta sus trabajos en forma pulcra y ordenada. 71.-Adopta siempre
decisiones rÃpidas y seguras. 72.- Le falta mayor madurez en su
evaluaciµn de situaciones profesionales. 73.-
Demuestra nerviosismo en las situaciones comprometidas. 74.- En algunas ocasiones
conversa con sus compaþeros sobre cuestiones ajenas
al trabajo. 75.- Para Õ1, el trabajo es solo un medio
para ganar un sueldo. 76.- Por su forma de trato
consigue ganarse las simpatÚas de sus compaþeros. 77.-
No solo ayuda sino que impulsa y anima a los compaþeros. 78.- En situaciones
difÚciles, sabe imponer su criterio con gran aceptaciµn. 79.- En ocasiones es
dominante y no consigue siempre la aceptaci6n del grupo. 80.- Tiene alguna dificultad
para comprender. Su asimilaciµn es lenta.
81.- Trabaja rutinariamente y precisa que le den ideas.
82.- Destaca por su capacidad para encontrar soluciones ante problemas
imprevistos. 83.- Se esfuerza por realizar funciones de mayor
responsabilidad. 84.- Es algo lento en su trabajo, en
comparaciµn con los demÃs compaþeros. 85.- Con
frecuencia comete errores aunque sean de escasa importancia. 86.- Su
intervenciones decisiva cuando surgen dificultades. Tiene mucha confianza en si mismo.
87.- Es algo subjetivo en sus juicios. DeberÚa ser mas ecuÃnime.
88.- RequerirÚa ser mas resolutivo en los momentos de fuerte carga de trabajo.
89.- EsporÃdicamente se le han observado retrasos de unos pocos minutos. 90.- Seria deseable que demostrara un mayor
interÕs frente a sus funciones.
VALORACIÆN DE LA ACTUACIÆN PROFESIONAL
Numero de Matricula..... Apellidos ....
Nombre ..... Fecha de Nacimiento...
Fecha de Ingreso.... CategorÚa...
Cargo.... Oficina....
Provincia.... Tiempo de Permanencia en el Puesto de Trabajo..... Fecha de la
Valoraciµn .... Cumplimente la presente hoja de respuestas, en base al Cuestionario de Valoraciµn
1.- Si - No 2.- Si - No
3.- Si - NO ..........
......... 90.- Si -No
Descripciµn del Tipo de Trabajo que actualmente desarrolla
¢Cuanto tiempo lleva desarrollando
estas funciones? ¢Por que.?
Determine la adecuacion de este
empleado a las siguientes tareas
1.- ......... no adecuado adecuado optimo
2.- .......
.- APTITUDES GERENCIALES no adecuado adecuado
optimo
(Capacidades para organizar el trabajo o la acciµn del personal, y para tomar
decisiones con un razonable margen de error)
.- PROFESIONALIDAD no adecuado adecuado optimo
(Fiel cumplimiento de las normas establecidas para los empleados en el
ejercicio de sus funciones)
Entre las siguientes funciones, seþale de que - en su opiniµn- puede
desarrollar actualmente este empleado
¢Desea Vd. conservar a este
empleado en su plantilla.?. (Exponga los motivos)
Otras observaciones que desea formular
sobre este empleado
Aspectos de proyecciµn social del informado
Dedicaciones extralaborales
Valoraciµn efectuada por Don.
CategorÚa/Cargo Fecha
Firma
CUESTIONARIO DE EVALUACIÆN DEL DESEMPEîO
INSTRUCCIÆN
Este cuestionario tiene dos clases de preguntas. La primera
pÃgina le presenta una serie de preguntas sobre el puesto y situaciµn del
empleado. Su misiµn consiste en expresar su opiniµn en los espacios en blanco.
El resto de las preguntas deben ser calificadas
numÕricamente, colocando el nºmero que expresa su opiniµn en la columna en el
margen de la pÃgina.
La escala de calificaciµn serà de 1 a 10, segºn la siguiente
clave:
1.- Muy bajo mÚnimo
2 - 3 Necesita mejorar
4 - 5 - 6 - 7 Bueno
8 - 9 Muy bueno
10 Excelente
PRIMERA PARTE
Nombre del Empleado:
Puesto que desempeþa actualmente: ..
Tareas que realiza en la actualidad:
¢QuÕ tareas realiza con grado excelente?
¢QuÕ tareas realiza simplemente bien?
¢En quÕ tareas se presentan deficiencias?
En su opiniµn, ¢merece ser promocionado?
Explique su respuesta
En caso afirmativo, ¢a quÕ puesto?
SEGUNDA PARTE
Seþalar lo que proceda
Cl - T
1) Descubre las causas de los errores de su trabajo y procura remediarlas con
prontitud. Si - No
2) Se esfuerza en mejorar la calidad de su trabajo. Si - No
3) Posee un alto grado de conciencia profesional. Si - No
4) De vez en cuando se le consulta sobre problemas que surgen en la marcha del
servicio.
5) Sabe prever las dificultades que pueden presentarse y remediarlas a tiempo.
6) Procura mejorar, en la medida de su posibilidad, los mÕtodos de trabajo.
7) Se considera capaz de enseþar a otros empleados.
8) Rinde cuentas de su trabajo a plena satisfacciµn y mantiene informadas a las
personas de la empresa.
9) No necesita que se controle frecuentemente su trabajo.
10) Previene a su Jefe con tiempo suficiente de cualquier dificultad que se
presente.
CN - T
1) Obtiene resultados positivos en su trabajo.
2) Habitualmente no tiene retrasos en su trabajo.
3) Es una persona organizada, sabiendo programar en el tiempo los trabajos que
se le encomiendan.
4) Ocasionalmente realiza trabajos suplementarios (aquellos que no le competen
directamente).
5) Cuando realiza horas extraordinarias, Õstas se dedican fundamentalmente a
trabajos urgentes (es decir, no necesita horas extraordinarias para realizar su
trabajo).
6) Siempre que se le necesita para asistir a una reuniµn, visitar un cliente,
etc., està siempre disponible.
7) Cumple a la perfecciµn los objetivos de su trabajo.
8) Trabaja mucho, sin necesidad de estar encima de Õl continuamente.
9) Cuando se acumula el trabajo sabe escalonar las tareas.
10) Si se le acaba el trabajo antes de tiempo, pide mÃs de forma espontÃnea.
E. D. E.
1) Es una persona disciplinada y tiene un gran interÕs en el servicio.
2) Acepta de buena gana ayudar a un compaþero cuando Õste està sobrecargado de
trabajo.
3) Es capaz de hacer un esfuerzo cuando asÚ lo requiere el servicio.
4) Realiza a veces tareas que no le agradan, mostrando buena voluntad.
5) Se adapta fÃcilmente a las otras personas del equipo.
6) Entra siempre a la hora.
7) Sus ausencias son poco frecuentes y siempre estÃn justificadas.
8) Utiliza su tiempo al mÃximo y de forma ordenada.
F.A.P
1) Comprende rÃpidamente y bien todo lo que se le dice.
2) Acepta con facilidad las novedades y cambios que se introducen en el
servicio.
3) No tiene inconveniente en aceptar las ideas de otra persona, obteniendo
partido de ellas para mejorar - su trabajo.
4) Interpreta correctamente las instrucciones y sabe llevarlas adelante sin
necesidad de insistirle.
5) En pocas ocasiones se ve sorprendido por situaciones inesperadas.
6) Sabe definir y ordenar los asuntos segºn su urgencia.
7) Cuando se presenta una dificultad, sabe resolverlo por sÚ mismo.
8) Se adapta con rapidez a los cambios introducidos en su trabajo.
9) Saca partido de su experiencia (de los Õxitos o de los fracasos).
C. P.
1) Conoce con precisiµn sus tareas y las relaciones que tienen dentro de la
Caja.
2) Yo le calificarÚa como una persona de gran competencia profesional.
3) SabrÚa realizar con responsabilidad las tareas de dos puestos de trabajo (por
lo menos).
4) Tiene una visiµn de conjunto de su servicio y està motivado en su trabajo.
5) Toma buenas iniciativas.
6) Puede sustituir a su jefe mÃs inmediato en caso de ausencia o urgencia.
7) Realiza su trabajo perfectamente.
8) Tiene capacidad para realizar trabajos mÃs complicados.
9) Se le ha ocurrido alguna idea sobre la forma de simplificar su trabajo.
10 Tiene conciencia del costo que implica los trabajos que realiza.
LA ELECCIÆN FORZADA
Ficha de valoraciµn para la elecciµn forzada mediante grupos de cuatro frases (Tetradas)
Nombre
Calificaciµn
Numero matricula
Unidad de la que depende
Periodo de valoraciµn.- desde ........hasta..... Fecha
Secciµn I.- RENDIMIENTO EN EL TRABAJO
Dentro de cada grupo de 4, seþalar, la elecciµn de dos con
mas y menos:
Grupo I
A.- No transige sobre su propia autoridad
B.- Descuidado y negligente
C.- Nadie duda de cu capacidad
D.- Bien preparado en todos los aspectos
Grupo II
A.- Critica a sus superiores
B.- Los demÃs no pueden trabajar con Õl
C.- Si tiene la culpa lo admite
D.- Se puede confiar en su juicio
Grupo III
A.- Respeta las instrucciones de sus superiores
B.- Trata de engaþar
C.- Critica sin razµn
D.- Inclinado a asumir la responsabilidad
Grupo IV
A.- No trabaja por el mayor interes de todos.
B.- Tiene mucha iniciativa
C.- No pide nunca excusas por sus errores
D.- Lento en efectuar su trabajo
Grupo V
A.- Hace siempre un buen trabajo
B.- Sangre fria en todas las circunstancias
C.- No escucha las sugerencias
D.- Guia en vez de mandar
Grupo VI
A.- No se preocupa de la carrera
B.- Conoce a los hombres, sus capacidades y sus limites
C.- Escasa eficiencia
D.- No sabe hablar
![]() ver artÚculo Agosto-Septiembre 2012
ver artÚculo Agosto-Septiembre 2012
![]() ver articulo diciembre 2011 - febrero 2012
ver articulo diciembre 2011 - febrero 2012
.- Aeropuertos.
.- Servicios (Handling, MayordomÚa, MercancÚas, etc,).
.- MeteorologÚa AeronÃutica.
.- Entrenamiento y licencias de personal.
.- Permisos y certificados operacionales.
.- Control e inspecciµn operacional.
.- Investigaciµn de accidentes.
.- Supervivencia, bºsqueda y salvamento.
.- AnÃlisis de tendencias y excedencias. etc.
b) Consideraciµn de los Factores Humanos en la Selecciµn del
Personal y
c) Aspectos Ergonµmicos y Automatizaciµn.
Ms y Mi, son las masas de los sujetos
DdSi es la distancia entre sujetos elevado a la potencia "d".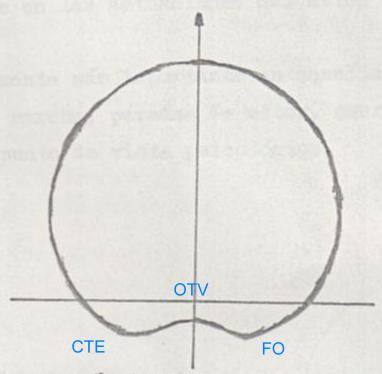
A Manager's Handbook of Organization Development Methods. Fordyce, Weil, 1971, Mass U.S.
lnterpersonal Paesemaking. Walton, 1969. Addison Pub. Mass. U.S.
Organization Development: Strategies and Models. Beckhard, 1969. Addison Pub. Mass. U.S.
Developin Organizations. Diagnosis and Action. Lawrwance, 1969. Addison Pub. Mass. U.S.
The Functions of the Excutive. Barnard, 1950. Cambridge, Mass. Harvard
University Press.
Who Are Your Motivated Workers? Myers, 1964. Harv. Bus. Rev. Enero y febrero.
Management arxl thc Worter. Roethlisbcrger y Dickson, 1939 Cambridge Harverd
University P.
Organizational Psychology. Schein, 1965. Prentice-Hall NJ.
A Systems Approach to Organizational Behaviour. Irwin, 1967.
The vital Balance. Meninger, 1963. NY
Then Motivation to Work. Myers, 1959. NY
Lives in Progress. Rihehart y Winston, 1966. NY
The Achieving Society. McClelland, 1961. NY
Toward a Theory of Motive Acquisition. ¨Amer. Psych£, vol. 20 nºm. 5. Mayo 1965.
Acerca de si podemos cambiar nuestros hÃbitos de dormir, el Dr. Webb de la
Universidad de Florida afirma que intentµ durante cinco aþos cambiar los hÃbitos de sueþo de las ratas para que no durmieran durante el dÚa; las ratas tambiÕn le
demostraron durante esos cinco aþos que era bastante necio. Existe un tema profundo e inherente que no puede ser cambiado. Los sujetos humanos pueden
alterar su sueþo temporalmente, pero luego vuelven al tipo de sueþo que ha sido genÕticamente fijado.
2. Diferencia de comportamientos.
3. Integraciµn
3.2, Cualidades
3.3. Estilos de Mando
3.4.2.- Participaciµn y decisiµn
3.4.3.- Clima de la relaciµn
2,1.2.- Las necesidades
2.1.3.- El Conflicto
2.1.4.- Factores que motivan y eleven la moral. El Castigo.
2.4,5.- La Motivaciµn y los Tripulantes.
2.2.2.- Atracciµn hacia el grupo
2.2.3.- Acuerdo
2,2.4.- Aceptaciµn. Liderazgo
2.2.5.- Los Grupos en la empresa
3.2, Cualidades
3.3. Estilos de Mando
3.4.2.- Participaciµn y decisiµn
3.4.3.- Clima de la relaciµn
Del Comportamiento no Verbal.
Del Componente Afectivo.
* De las Actitudes de los Interlocutores.
* De la propia Situaciµn en que se desarrolla la Comunicaciµn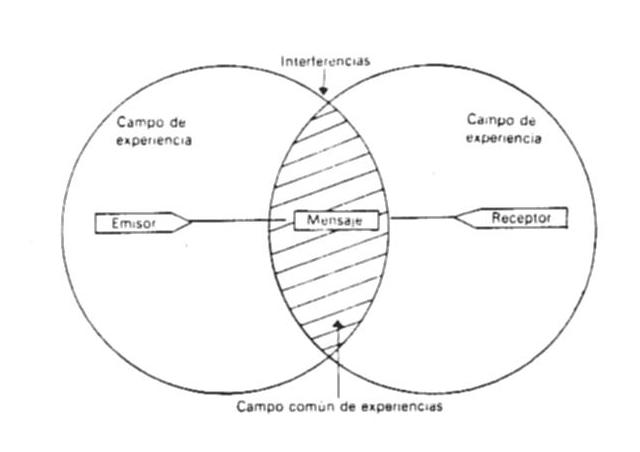
- nos hacen reaccionar de una determinada manera
- Los otros: lo que pienso y siento hacia la persona con la que comunico.
- El mensaje: lo que pienso y siento hacia lo qua dice o voy a decir.
- La comunicaciµn: lo que creo que es la comunicaciµn, como me siento al
comunicarme .