Virgen de Loreto
Este espacio està reservado para los artÚculos ya publicados
LOS VALORES ESCALARES UN CRITERIO OBJETIVO DE INADECUACIÆN
En la medida de lo posible, se han probado de forma objetiva este tipo de procedimientos; y se han retenido de forma intencionada algunas aseveraciones de
opiniµn que eran abiertamente ambiguas o de la misma manera inadecuadas para una escala de actitud. Estas se han probado determinar en quÕ grado podÚan
eliminarse por mÕtodos objetivos. DifÚcilmente se llegarÚa a elaborar una escala de actitud ºtil, aplicando mecÃnicamente reglas de objetividad. Se puede
vaticinar que prevalecerà indefinidamente cierta libertad en lo que concierne a los juicios de los investigadores; pero estos mÕtodos ºnicamente alcanzarÃn
Õxito en la medida en que los juicios individuales del investigador, sobre material de esta clase, puedan comprobarse de modo objetivo.
El criterio de ambig■edad denota la extensiµn de una aseveraciµn sobre la escala subjetiva de
intervalos aparentemente iguales. Si 300 sujetos colocan una aseveraciµn de opiniµn en intervalos muy diferentes de la escala citada, el valor Q de aquÕlla
serà grande y, por consiguiente, segºn este criterio objetivo, se la considerarà ambigua, pues demuestra tener significados en extremo diversos, para los
diferentes sujetos, a lo largo de la escala de actitud. De mÃs està decir que aseveraciones asÚ deben eliminarse. Por simple examen, es posible afirmar en
general si una aseveraciµn tendrà un valor Q grande, Es de observarse que este valor de una opiniµn no refleja las opiniones efectivas que los sujetos
mantengan sobre el asunto en consideraciµn. Estos ºnicamente clasifican las aseveraciones conforme a la actitud que encuentren en aquÕllas, sin expresar de
modo alguno sus propias actitudes. Por otra parte, el criterio de inadecuaciµn atiende a los registros de los votos
efectivos. La lista completa de 130 afirmaciones se imprimiµ y luego se expuso a los 300 sujetos, a quienes se pidiµ marcar las opiniones que aprobaran o con las
cuales estuvieran de acuerdo, y que dejaran en blanco las restantes. Se pasµ despuÕs a estudiar las respuestas en lo referente a su consistencia interna.
Cuando encontramos gran inconsistencia, la atribuimos al descuido de los sujetos que acaso hacÚan sus marcas al azar, o a defectos de las propias aseveraciones.
En los experimentos presentados se encuentran cierta cantidad de inconsistencia a lo largo de toda la lista; podemos atribuirla, indudablemente y por lo menos en
parte, a los sujetos mismos. Pero las inconsistencias varÚan con la aseveraciµn seleccionada como base de comparaciµn de las restantes; y tales diferencias se
deben, principal y evidentemente, a defectos de las aseveraciones mismas. AsÚ se han considerado; y se desarrolla un criterio de inadecuaciµn que puede
usarse ampliamente para eliminar las afirmaciones inadecuadas de la escala. Este criterio se desarrolla como sigue: supongamos que una afirmaciµn de poca
ambig■edad se ubica correctamente en el punto 6 de la escala. Si un sujeto tiene una actitud que tambiÕn se colocµ correctamente en el punto 6 de la escala,
entonces esperamos que marque esa afirmaciµn. Otro sujeto, que se colocµ en el punto 12, con menor probabilidad marcarÚa esa afirmaciµn; de manera similar
habrÚa una probabilidad pequeþa de que un sujeto en el punto 0 marcara la aseveraciµn colocada en el 6 de la escala. Para hacer este tipo de anÃlisis
cuantitativo, se ha desarrollado un Úndice mÃs bien neto de semejanza, que se basa en la votaciµn de un nºmero grande de sujetos. El Úndice de semejanza de un
par de aseveraciones se basa en tres hechos, a saber, na = total de sujetos que
ratifican la aseveraciµn a en la comparaciµn; nb = nºmero total de sujetos que ratifican la afirmaciµn b en la comparaciµn; nab = nºmero total
de sujetos que ratifican tanto a como b. Si las dos aseveraciones a y b son prÃcticamente iguales en cuanto a las actitudes que
reflejan, entonces esperamos encontrar que los sujetos que ratifican la afirmaciµn a tambiÕn ratificarÃn la b. Por consiguiente, este factor
nab serà el numerador del Úndice de semejanza. Por otra parte, las aseveraciones varÚan considerablemente en popularidad intrÚnseca aun cuando sean colocadas en puntos
idÕnticos de la escala. Cuanto mÃs popular es una aseveraciµn, tanto mayor es el nºmero de personas que la ratifica, pero no asÚ cualquier otra. Para reducir el
Úndice de semejanza a la misma base de popularidad en todas las aseveraciones, se divide el nºmero de sujetos que ratifican ambas aseveraciones entre el
producto del nºmero total de ratificaciones con respecto a cada una de las dos aseveraciones, de manera que el Úndice de semejanza es
nab/na nb Si tabulamos los Úndices de la
aseveraciµn a con cada uno de las demÃs en forma sucesiva, tendremos el factor comºn 1/na que puede descartarse, pues es una constante. Entonces tendremos:
Úndice de semejanza de la aseveraciµn: a = Ca = nab/nb
Este Úndice sirve para comparar la aseveraciµn a con cada una de las demÃs. Es evidente que el valor mÃximo posible de este Úndice es la unidad y su valor
mÚnimo, cero. Cuando todas las personas que ratifican la aseveraciµn a tambiÕn ratifican la k, el Úndice de semejanza es la unidad como deberÚa ser porque las
dos aseveraciones son entonces evidentemente muy semejantes en las actitudes que reflejan. Si, por otra parte, ninguno de los que ratifican la aseveraciµn a
ratifica la k, entonces el Úndice es cero; esto se deduce de que las dos aseveraciones son entonces evidentemente muy diferentes en cuanto a las
actitudes que describen. En la figura 1
tenemos una representaciµn grÃfica de los Úndices de semejanza de la aseveraciµn 96 con cada una de las demÃs, y en contraste con el valor escalar de cada una de
ellas. El valor escalar de la aseveraciµn 96 se indica por la pequeþa flecha sobre la lÚnea superior del diagrama. Su Úndice de semejanza consigo misma, en
condiciones ideales, serÚa la unidad. Se observa inmediatamente que los Úndices de la aseveraciµn 96, con cada una de las demÃs aseveraciones, son muy bajos
cuando Õstas estÃn alejadas de ella. Y esto es precisamente lo que se esperaba. Dicho de otra manera, quienes ratificaron la aseveraciµn 96, que se colocµ en
10.5, no ratifican a menudo las aseveraciones que estÃn en los intervalos de clase cuatro o cinco, en el otro extremo de la escala. Los Úndices son mÃs altos
cuando la segunda aseveraciµn se acerca al valor escalar de la aseveraciµn 96. Cada cÚrculo pequeþo en este diagrama representa el Úndice de semejanza entre la
aseveraciµn 96 y otra, y està colocado inmediatamente por encima del valor escalar de esa segunda aseveraciµn. El
criterio de inadecuaciµn se manifiesta en el diagrama entero. Cuando los Úndices de semejanza son relativamente altos, cerca del valor escalar de la aseveraciµn
comºn o primera, y relativamente bajos para las aseveraciones que estÃn lejos de dicha aseveraciµn, la primera aseveraciµn se considera satisfactoria. Esto
significa sencillamente que no es tan probable que las personas que ratifican la aseveraciµn 96 ratifiquen tambiÕn las aseveraciones que estÃn mÃs alejadas del
valor escalar 96. El aspecto de la figura 1 se considera satisfactorio y por consiguiente se conserva la afirmaciµn 96.
Veamos un anÃlisis semejante de una aseveraciµn que fue
descartada por el criterio de inadecuaciµn. En la figura 2 aparecen los Úndices de semejanza de la aseveraciµn 23. El valor escalar de esta aseveraciµn tambiÕn
se indica por una pequeþa flecha sobre la lÚnea superior del diagrama. ConsidÕrese el pequeþo cÚrculo en el extremo izquierdo del diagrama. Es el
Úndice de semejanza entre la aseveraciµn 23 y la 101, que tiene un valor escalar de .02. El Úndice es de .56. Los otros cÚrculos se ubicaron de manera semejante
y representan el grado de semejanza entre la aseveraciµn 23 y cada una de las demÃs. Observese que las personas que ratifican la aseveraciµn 23 ratifiquen tanto las
afirmaciones en cualquier extremo de la escala como las prµximas a la afirmaciµn 23. Los puntos se dispersan mÃs o menos horizontalmente en el diagrama. Esto
indica que hay algo fundamentalmente errµneo en la aseveraciµn 23 como Úndice de una actitud particular en la escala. Dicho de otra manera, si una persona
ratifica esta afirmaciµn no podemos decir nada acerca de su actitud hacia la iglesia, porque es probable que ratifique no solamente las afirmaciones dentro
del intervalo de clase 4-5, sino tambiÕn las que estÃn en los extremos de la escala, hasta donde puede juzgarse por la propia afirmaciµn 23. La aprobaciµn de
esta aseveraciµn no nos ayuda, sin embargo, a ubicar al sujeto en un punto de la escala. En la
aseveraciµn original se afirmaba lo siguiente: "Estoy interesado en una iglesia que es bella y que destaca el lado estÕtico de la vida". Ahora podemos ver por quÕ esta afirmaciµn
es inadecuada para la variable de actitud que intentamos medir. Sin duda, el miembro devoto de la iglesia puede ratificar conscientemente esta afirmaciµn,
pues le interesa que la iglesia sea bella. Pero el ateo tambiÕn puede ratificar la aseveraciµn porque pueden interesarle los edificios bellos,
incluyendo las iglesias, y asimismo interesarle la mºsica religiosa aunque no tome en serio las funciones inherentes a la iglesia. La actitud reflejada por la
afirmaciµn 23 no es vÃlida, por consiguiente, como Úndice de la variable de actitud que està implÚcita en la lista de aseveraciones como un todo. El hecho
de que los Úndices de la figura 2 se dispersen mÃs o menos horizontalmente a travÕs de la escala entera constituye la razµn objetiva para descartar la
aseveraciµn 23.
Veamos otras muestras que revelan el criterio de inadecuaciµn en otras aseveraciones. En la figura 3 se han dibujado los Úndices de semejanza dÕ
la aseveraciµn 7. Esta aseveraciµn se colocµ en el 8.2 de la escala y los Úndices tienen valores muy bajos en el otro
extremo de la misma. Por consiguiente, esta aseveraciµn se retuvo en la escala final.
La figura 4 presenta un dibujo semejante para la aseveraciµn 113 donde los Úndices de semejanza tienen valores bajos para las segundas aseveraciones en la
mitad superior de la escala. Todos los Úndices estÃn por encima de .90 en varios de los primeros intervalos de clase. Por consiguiente, la afirmaciµn se conservµ
para la escala final. La figura 5
muestra un dibujo semejante para la afirmaciµn 49. AquÚ nuevamente los Úndices se dispersan mÃs o menos horizontalmente a travÕs de la escala entera y, por
consiguiente, se descartµ la afirmaciµn 49. Veamos la aseveraciµn original. Dice lo siguiente: "Yo creo que uno no tiene que pertenecer a la iglesia para
ser religioso". Es muy posible que un miembro devoto de la iglesia ratifique esta afirmaciµn. TambiÕn es posible que la persona no religiosa la ratifique
como una aseveraciµn de hecho, aunque no tenga interÕs en la iglesia ni en la religiµn. Es de esperarse que la proporciµn de ratificaciones a esta aseveraciµn
sea mÃs alta en el extremo contrario de la escala y aso es lo que encontramos en la figura 5, pero la discriminaciµn no es de ninguna manera suficiente. Los
Úndices tienen aproximadamente el mismo nivel a lo largo de la escala y, por consiguiente, se descarta la aseveraciµn.
La figura 6 presenta una discriminaciµn satisfactoria para la aseveraciµn 50
porque los Úndices estÃn por encima de .90 prµximos al valor escalar de la aseveraciµn 50, seþalado por la pequeþa flecha, y descienden a valores
inferiores en el otro extremo de la escala. Por tanto la afirmaciµn se conserva.
La figura 7 es la grÃfica de la afirmaciµn 9, la cual se descarta porque los Úndices de semejanza no presentan suficiente variaciµn en las diferentes partes
de la escala. En efecto, la afirmaciµn dice: "No creo que ir a la iglesia perjudique a nadie". AquÚ, podemos suponer otra vez, fÃcilmente, que el miembro
devoto de la iglesia reconocerà la verdad de esta afirmaciµn. El votante contrario a la iglesia tambiÕn estÕ posiblemente dispuesto a reconocer que
asistir a la iglesia no perjudica a nadie. Este ºltimo grupo no ratificarà con tanta facilidad la aseveraciµn como el primero; pero el examen del diagrama
indica claramente que la discriminaciµn es insatisfactoria. Las personas, a travÕs de toda la escala, ratifican esta aseveraciµn aunque tengan sentimientos
o ideas completamente diferentes para hacerlo. La simple ratificaciµn de esta aseveraciµn no nos ayuda a ubicar al votante en la escala; y es por esto que la
aseveraciµn se considera inadecuada para la escala, la cual està representada por la lista entera de aseveraciones.
Indudablemente serÚa posible cuantificar el criterio de inadecuaciµn de manera mejor. Sin embargo, es conveniente esperar a que se tenga una formulaciµn mÃs
general. Se han unificado dos criterios objetivos para la selecciµn y ubicaciµn de las aseveraciones de opiniµn, que
son: el criterio de ambig■edad, µ sea el valor Q, que se basa en el grado de uniformidad en la clasificaciµn de las aseveraciones, y el criterio de
inadecuaciµn, que se basa en la consistencia de la votaciµn o ratificaciµn efectiva. Estas dos partes fueron realizadas en dos
grupos diferentes de sujetos. Una aseveraciµn puede ser clasificada uniformemente por todos los
sujetos y, no obstante, ser declarada inapropiada por el criterio de inadecuaciµn. Esto se explica de la siguiente manera: cuando leemos una
aseveraciµn y despuÕs juzgamos la actitud que representarÚa, podemos concordar completamente y entonces le asignamos un valor Q, bajo, a la aseveraciµn. Cuando
pedimos a los sujetos que ratifiquen Õsta, encontramos que algunos que difieren ampliamente en sus actitudes tienen razones muy diferentes para hacerlo. Esto es
particularmente probable cuando la aseveraciµn puede considerarse ya como una expresiµn de actitud, ya como descripciµn de un hecho. Por ejemplo, el devoto de
la iglesia probablemente no apoye la aseveraciµn "Ir a la iglesia no perjudica a nadie". Una persona que apoye espontÃneamente esa aseveraciµn no es probable que
sea un devoto de la iglesia. La situaciµn es muy diferente cuando la aseveraciµn es elaborada por algºn otro y presentada para ratificaciµn como si fuera
verdadera o falsa. En tal situaciµn, el devoto de la iglesia puede reconocer la aseveraciµn como verdadera, aunque naturalmente no expresa con ello sus propias
actitudes. Esta distinciµn entre lo que decimos espontÃneamente al expresar nuestras actitudes y lo que estamos dispuestos a reconocer o ratificar cuando es
expresado por algºn otro, probablemente explique el hecho de que el criterio de ambig■edad y el criterio de inadecuaciµn no siempre eliminan las mismas
aseveraciones. De manera ideal, la escala deberÚa construirse quizà solamente por medio de votaciµn. Es posible
plantear el problema de modo que los valores escalares de las aseveraciones puedan extraerse de los registros de votaciµn efectiva. Si esto fuera posible,
el procedimiento presente para establecer los valores escalares por clasificaciµn serÚa inºtil.
CRITERIOS INFORMALES PARA LA SELECCIÆN DE OPINIONES En esta escala de actitud, se han
formulado una lista de criterios informales que se usarÃn en la construcciµn de futuras escalas de actitudes. Por medio de estos criterios se encuentra que
muchas de las opiniones de la escala experimental presente son defectuosas, y hay que tenerlas presentes al comenzar la construcciµn de nuestra propia escala,
que no tenga, hasta donde sea posible, los defectos que vamos a describir. La lista siguiente contiene algunos criterios informales para la selecciµn de opiniones
en la elaboraciµn de una escala de actitud; no està completa y posiblemente se opine que no son defectuosas algunas de las caracterÚsticas siguientes.
1. Hasta donde sea posible, las opiniones deben reflejar la actitud presente del sujeto y no sus actitudes pasadas. Expresando las opiniones en tiempo presente
se evita que un sujeto pueda ratificar dos opiniones conflictivas, una referente a su actitud pasada y otra a la actual. El valor escalar del sujeto describirÚa,
naturalmente, su actitud presente. 2. Se ha encontrado que las aseveraciones de significado doble tienden a ser
ambiguas. El material debe redactarse de tal manera que cada opiniµn exprese hasta donde sea posible solamente un pensamiento o idea. El sujeto se confunde al leer una aseveraciµn
de doble significado en la que desea ratificar una idea pero no la otra. Ejemplo: "Yo creo en los ideales de la iglesia, pero estoy fastidiado de
sectas". Tal vez esta afirmaciµn fuera mÃs ºtil si se dividiera en dos opiniones. 3. Uno debe evitar las
afirmaciones que son aplicables evidentemente à un grupo muy restringido de sujetos. Ejemplo: "Yo voy a la iglesia porque me gusta la buena mºsica". "Estoy
en el coro y aprendo mºsica y cantos corales". La primera aseveraciµn puede ser ratificada por un grupo amplio de sujetos, pero la segunda pueden ratificarla
solamente quienes son miembros del coro de una iglesia. Probablemente no vale la pena incluir, en una escala, opiniones que estÕn limitadas de ese modo por
caracterÚsticas relativas a hechos precisos. Lo que deseamos medir es la actitud y para hacerlo debemos evitar una influencia tan marcada en la amplitud
de los posibles ratificadores. La afirmaciµn precedente acaso mejorarÚa mucho para nuestros propµsitos si solamente se mantuviera la primera afirmaciµn, para
incluirla en una escala. 4. Cada opiniµn elegida para la escala de actitud deberÚa ser, preferentemente, de tipo
tal que no pudieran ratificarla los sujetos de ambos extremos de la tabla. Tales opiniones serÚan eliminadas por los criterios objetivos; pero cuando este
defecto es conspicuo la afirmaciµn puede descartarse desde el principio. Probablemente siempre habrÚa, ademÃs, cierto nºmero de opiniones de la lista que
tengan este defecto y que no sean reconocidas cuando las lee el investigador. Posteriormente, cuando son descartadas por los criterios objetivos, resulta
generalmente fÃcil saber por quÕ fueron eliminadas estas aseveraciones. Dicho de otra manera, es mÃs fÃcil tener una base objetiva para descartar una aseveraciµn
y despuÕs, al examinarla, ver por quÕ se descartµ, que descubrir estas aseveraciones defectuosas mediante la lectura de la lista completa de
aseveraciones originales. 5. Hasta donde sea posible, las aseveraciones, no deben contener conceptos relacionados y
confusos. En el material de la escala de actitud presente tenemos varias aseveraciones que mencionan a la "religiµn verdadera" y a "la religiµn de
Jesºs". Probablemente es difÚcil interpretar estas aseveraciones, porque ademÃs de las afirmaciones acerca de la iglesia contienen conceptos relacionados que
deberÚan evitarse siempre que sea posible. Ejemplo: "Yo creo que la iglesia permite las diferentes sectas para aparecer mÃs grande que la religiµn verdadera". Una aseveraciµn de este tipo puede reelaborarse para que solo se
refiera a las diferencias de secta, demasiado recalcadas por las iglesias, segºn se afirma, sin incluir la incertidumbre de interpretaciµn de la frase "religiµn
verdadera". 6. Si las demÃs cosas son iguales, debe evitarse la jerga, respectiva excepto cuando sirva al propµsito de
describir una actitud en forma mas breve de la que podrÚa lograrse de otra manera. Por ejemplo, decir que la mayorÚa de los
sermones son "pura habladurÚa" puede justificarse si se considera una manera natural de expresar la actitud que se va a representar en la escala.
MEDIDA DE LAS ACTITUDES
UNIDAD DE MEDIDA PARA LAS ACTITUDES La ºnica manera como podemos identificar las actitudes diferentes (los puntos en
la lÚnea base) es utilizando un conjunto de opiniones como marcas, en las diferentes partes o pasos de la escala. La escala final consistirà entonces en
una serie de aseveraciones de opiniµn; y cada una de ellas estarà ubicada en un punto particular en la lÚnea base. Si comenzamos con suficientes aseveraciones
quizà podamos seleccionar una lista de 20 0 30 opiniones escogidas, de manera que representen una serie de actitudes graduadas de manera uniforme. La
separaciµn entre las aseveraciones de opiniµn sucesivas serÚa entonces uniforme; pero la escala puede construirse tambiÕn con una serie de opiniones ubicadas en
la lÚnea base aunque sus separaciones sean desiguales. Sin embargo, con el propµsito de dibujar distribuciones de frecuencia, es conveniente que los pasos
entre las aseveraciones escogidas sean uniformes por la amplitud entera de la escala.
ConsidÕrense las tres aseveraciones a, c y d en la figura 1. Las aseveraciones c y a se colocan muy juntas para indicar su extrema semejanza, mientras que las
aseveraciones c y d se colocan con gran separaciµn entre sÚ para apuntar lo diferentes que son. Es de esperarse que dos individuos colocados en los puntos c
y a, respectivamente, concuerden extremadamente al discutir sobre pacifismo y militarismo. Por otra parte, pensamos que es muy fÃcil expresar la diferencia
que hay entre las opiniones de una persona en d y otra en c. Las separaciones escalares de las opiniones deben concordar con nuestras impresiones de ellas.
Para determinar lo separadas que deben estar las aseveraciones en la escala final, las aplicamos a un grupo de varios cientos de personas, a quienes pedimos
que ordenen las aseveraciones desde la mÃs pacifista hasta la mÃs militarista. No les preguntamos sus propias opiniones. Ese es un asunto por entero diferente.
Lo que nos interesa es la elaboraciµn de una escala con una unidad vÃlida de medida. Puede haber cien aseveraciones en la lista original y se pide a varios
cientos de personas que solamente arreglen las aseveraciones en orden jerÃrquico conforme a la variable de actitud seþalada. DespuÕs es posible determinar la
proporciµn de sujetos que consideran la afirmaciµn a mÃs militarista que la c. Si las dos afirmaciones representan actitudes muy similares, no debemos esperar
un acuerdo perfecto en el orden jerÃrquico de las afirmaciones a y c. Si son idÕnticas en actitud, habrà cerca del 50% de sujetos que digan que la
aseveraciµn a es mÃs militarista que la c, mientras que el otro 50% dirà que la aseveraciµn c es mÃs militarista que la a. Es posible usar la proporciµn de
sujetos o jueces que coincidieron con respecto al orden jerÃrquico de dos afirmaciones cualesquiera como base de la mediciµn efectiva.
Si el 90% de los jueces o sujetos dicen que la afirmaciµn a es mÃs militarista que la b (pa>b = .90) y si solamente el 60% de los jueces dicen que la
afirmaciµn a es mÃs militarista que la c(pa>c =.60), entonces la separaciµn escalar (a - c) es mÃs corta que la separaciµn escalar
(a-b).La separaciµn entre dos estÚmulos cualesquiera en la escala psicolµgica puede medirse con base en una ley del juicio comparativo.
Los mÕtodos pormenorizados de manejo de los datos se publicarÃn conjuntamente con la construcciµn de cada escala particular. El resultado prÃctico de este
procedimiento es una serie de aseveraciones de opiniµn colocadas a lo largo de la lÚnea base de la figura 1. La interpretaciµn de las distancias de la lÚnea
citada consiste en que la diferencia aparente entre dos opiniones cualesquiera serà igual a la diferencia aparente entre otras dos opiniones cualesquiera que
estÕn igualmente espaciadas en la escala. Dicho de otra manera, el cambio de opiniµn representado por la distancia de una unidad en la lÚnea base parece ser,
para la mayorÚa de las personas, igual al cambio de opiniµn representado por la distancia de una unidad en cualquiera otra parte de la escala. Los dos
individuos que estÃn separados por determinada distancia en la escala parecen diferir en sus actitudes, tanto como otros dos individuos cualesquiera que
tengan la misma separaciµn escalar. En este sentido, tenemos una lÚnea base verdaderamente racional; y los diagramas de frecuencia erigidos en tal lÚnea
base son susceptibles de interpretaciµn legÚtima como superficies de frecuencia. En contraste con semejante lÚnea base o escala racional està el sencillo
procedimiento de enumerar solamente de diez a veinte opiniones, hacer que unos cuantos jueces las ordenen jerÃrquicamente, para despuÕs contar simplemente el
nºmero de adhesiones a cada aseveraciµn. Esto puede hacerse, desde luego, siempre que no se interprete el diagrama resultante como una distribuciµn de
frecuencia de actitud. Si el diagrama se interpreta de esta manera, puede tomar cualquier forma que queramos con sµlo agregar nuevas aseveraciones o eliminar
algunas, arreglando la lista resultante en orden jerÃrquico aproximado, y uniformemente espaciado en la lÚnea base. Los diagramas de opiniones de Allport
no son en ninguna forma distribuciones de frecuencia. Deben considerarse como diagramas de barras donde se presenta la frecuencia con que fue respaldada cada
una de las aseveraciones. Este mÕtodo ha mejorado el procedimiento de Allport. Este trata virtualmente con µrdenes jerÃrquicos, en este se pretende transformar
en medida, con una unidad racional de medida. Los estudios pioneros de Allport en este campo deben ser leÚdos por todos los investigadores de este problema.
La unidad de medida de la escala de actitudes es la desviaciµn estÃndar de la dispersiµn proyectada
en la escala psicofÚsica de actitudes, por una aseveraciµn de opiniµn, seleccionada como estÃndar. No importa quÕ afirmaciµn se escoja como estÃndar;
las escalas producidas por diferentes aseveraciones estÃndares tienen valores escalares proporcionales. Esta unidad mental de medida es aproximadamente
semejante, pero no idÕntica, a la llamada "diferencia apenas notable" de la mediciµn psicofÚsica.
Puede elaborarse un diagrama semejante al de la figura 1 por lo menos de dos maneras diferentes.
Puede hacerse que el Ãrea de la superficie de frecuencia represente al nºmero total de votos o adhesiones de un grupo de personas, o bien puede representar el
nºmero total de individuos del grupo estudiado. Los diagramas de Allport se harÚan con el ºltimo principio si fueran elaborados sobre una lÚnea base
racional, de modo que pudiera medirse un Ãrea legÚtima. A cada sujeto se le pedirÚa que seleccionara de la lista la aseveraciµn que fuese mÃs representativa
de su propia actitud. En tal caso, por lo menos la suma de las ordenadas serÚa igual al nºmero de personas del grupo. En este procedimiento se pide a cada
sujeto que ratifique todas las afirmaciones con las que estÕ de acuerdo. Como se tiene una lÚnea base racional, podemos inferir legÚtimamente que el Ãrea de la
superficie equivale al nºmero total de ratificaciones hechas por el grupo. Este procedimiento tiene la ventaja de que determina la amplitud de opiniµn que es
aceptable para cada persona, lo cual tiene considerable interÕs, y no puede determinarse pidiendo al sujeto que ratifique solamente una de las aseveraciones
de la lista. Las ordenadas del diagrama de frecuencia pueden dibujarse como proporciones del grupo total. Por consiguiente, se interpretarÃn como la
probabilidad de que la aseveraciµn dada sea ratificada por un miembro del grupo. En otras palabras, el diagrama de frecuencia describe la distribuciµn de actitud
del grupo completo; y la ordenada de cada punto de la lÚnea base representa la popularidad relativa de esa actitud.
CONSTRUCCIÆN DE UNA ESCALA DE ACTITUD Se han construido fundamentalmente tres escalas para
medir la opiniµn por los principios descritos. Estas tres escalas se han diseþado para medir las actitudes en funciµn de tres variables diferentes, a
saber, pacifismo-militarismo, prohibiciµn del alcohol y actitud hacia la iglesia. Dichas escalas se han construido por un procedimiento menos laborioso
que aquel que aplica directamente la ley del juicio comparativo; en caso de obtenerse resultados consistentes, el nuevo mÕtodo se harà extensivo a otras
escalas. El mÕtodo es el siguiente. A varios grupos de personas se les pide que escriban sus
opiniones sobre el asunto en cuestiµn; y se buscan en la bibliografÚa existente aseveraciones adecuadas y breves que puedan servir a los fines de la escala. Al
editar este material se prepara una lista de 100 a 150 aseveraciones expresivas de actitudes que cubran lo mejor posible todas las graduaciones desde un extremo
a otro de la escala. Algunas veces es necesario conceder atenciµn especial a las aseveraciones neutras. Si una colecciµn al azar de aseveraciones de opiniµn
fallara en producir reactivos neutros existirÚa el peligro de que la escala se dividiera en dos partes. La amplitud total de actitudes debe cubrirse en toda su
extensiµn, por lo que toca al estudio preliminar, a fin de asegurar que los µrdenes jerÃrquicos de los diferentes lectores se traslapen a lo largo de la
escala. En la elaboraciµn de la lista inicial de aseveraciones se aplican varios criterios
prÃcticos en el primer trabajo de ediciµn. Algunos de los criterios mÃs importantes son los siguientes:
a) Las afirmaciones deben ser lo mÃs cortas posible de manera que no fatiguen a los sujetos a quienes sÕ pida que lean la lista completa.
b) Las afirmaciones deben ser de tal tipo que puedan ser secundadas o rechazadas conforme a su
concordancia o discrepancia con la actitud del lector. Algunas aseveraciones de una muestra al azar estarÃn redactadas de manera que el lector no pueda expresar
ratificaciµn o rechazo definido de ellas. c) Cada aseveraciµn debe prever que su aceptaciµn o rechazo indique algo con respecto a la actitud
del lector acerca del asunto en cuestiµn. Si, por ejemplo, se hace la afirmaciµn de que la guerra es un aliciente para el genio inventivo, su aceptaciµn o
rechazo no dice nada con respecto a las tendencias pacifistas o militaristas del lector; puede Õste considerar que la afirmaciµn es un hecho indiscutible y
simplemente la ratifica como un hecho, en cuyo caso tal respuesta no revela nada acerca de la propia actitud sobre el asunto. Sin embargo, solamente los ejemplos
conspicuos de este efecto se eliminarÚan por anÃlisis, porque se dispone de un criterio objetivo para descubrir tales afirmaciones, a. modo de eliminarlas
automÃticamente de la escala. El juicio personal debe reducirse al mÚnimo posible en este tipo de trabajo.
d) Las afirmaciones de doble significado deben evitarse excepto, quizÃ, como ejemplos de neutralidad
cuando no parezca fÃcil obtener mejores afirmaciones neutras. Las afirmaciones de doble significado tienden a ser muy ambiguas.
e) Es necesario asegurarse de que por lo menos una rotunda mayorÚa de las afirmaciones pertenece
realmente a la variable de actitud que se va a medir. Si se dejara en la serie un pequeþo nºmero de afirmaciones impropias ya sea en forma intencional o no
intencional, aquÕllas serÚan eliminadas automÃticamente por un criterio objetivo; pero este no tendrÚa Õxito a menos que la mayorÚa de las afirmaciones
formaran parte claramente de la variable estipulada. Cuando la lista original se edita teniendo presentes estos criterios, quedan
quizÃs de 80 a 100 aseveraciones, con las cuales formar una escala eficaz. Las aseveraciones resultantes se imprimen despuÕs en pequeþas tarjetas, a razµn de
una por tarjeta. Se pide a 200 o 300 sujetos que arreglen las aseveraciones en 11 grupos que vayan desde las opiniones completamente afirmativas hasta las
completamente negativas. Las instrucciones detalladas se publicarÃn junto con la descripciµn de las escalas separadas. La tarea consiste esencialmente en
clasificar las pequeþas tarjetas en 11 grupos de manera que parezcan estar igualmente espaciadas o graduadas. Solamente se rotulan los dos grupos extremos
y el de en medio. Este ºltimo se destina a las opiniones neutrales. El lector debe decidir, sobre cada aseveraciµn, cuÃl de los cinco grados subjetivos de
afirmaciµn o de negaciµn es el implicado en ella, o, en su caso, si se trata de una opiniµn neutra.
Concluida la clasificaciµn realizada por los 200 o 300 lectores, se prepara un diagrama similar al de la figura 2. Vamos a estudiarlo en una escala de
pacifismo-militarismo a manera de ejemplo. En la lÚnea base de este diagrama estÃn representados los 11 intervalos aparentemente iguales de la variable de
actitud. El intervalo neutral es el comprendido entre 5 y 6; el intervalo mÃs pacifista va de 0 a 1 y el mÃs militarista de 10 a 11. El diagrama es ficticio y
se ha dibujado ºnicamente para ilustrar el principio que se aplica. La curva A indica la manera como podrÚa ser clasificada una de las aseveraciones por parte
de los 300 lectores. Ninguno la clasificµ debajo del valor 3; la mitad de los lectores lo hizo por debajo del valor 6; y la totalidad, por debajo del valor 9.
El valor escalar de la aseveraciµn es el valor por debajo del cual fue colocada justamente por la mitad de los lectores. En otras palabras, el valor escalar
asignado a la aseveraciµn se selecciona de manera que la mitad de los lectores lo consideran mÃs militarista que el valor asignado y la otra mitad menos
militarista que el mismo valor. El cÃlculo numÕrico del valor escalar es similar al cÃlculo del umbral por medio de la hipµtesis fi-gama en la mediciµn
psicofÚsica.
Habrà de notarse que algunas de las aseveraciones en los extremos de la escala no dan curvas ojivales completas; es por esto que la aseveraciµn C estÃ
incompleta en el diagrama. Se comporta como si, para completarse, necesitara espacio mÃs allà de los lÚmites arbitrarios de la escala. Sin embargo, su valor
escalar puede determinarse por aquÕl donde la curva fi-gama dibujada a travÕs de las proporciones experimentales atraviesa el nivel del 50% que està en c. Pueden
encontrarse otras aseveraciones, tales como D, que tienen valores escalares mÃs allà de la amplitud arbitraria de la escala. TambiÕn se les pueden asignar
valores escalares, aunque menos exactos por el mismo procedimiento. La situaciµn es diferente en el otro extremo de la escala. La aseveraciµn E
tiene su valor escalar en e, pero, teniendo la escala el lÚmite en el punto 11, la proporciµn experimental serà de 1.00 en ese punto. Si la escala continuara
mÃs allà del punto 11, las proporciones continuarÚan elevÃndose gradualmente como lo indica la lÚnea interrumpida. Las proporciones experimentales son todas,
necesariamente, de 1.00 para el valor escalar 11 y, por consiguiente, esas proporciones finales deben ignorarse al ajustar las curvas fi-gama y al
localizar los valores escalares de las aseveraciones. VALIDEZ DE LA ESCALA
a) La escala debe trascender al grupo medido. Antes de aplicarse, este mÕtodo de mediciµn debe someterse a una prueba experimental decisiva, despuÕs de
la cual pueda aceptarse su validez. Un instrumento de medida no debe ser afectado seriamente por el objeto, en su funciµn de medir. En el mismo grado en
que su funciµn de medir resulte afectada o daþada, se limitarà su validez. Si una regla de una medida diferente por el mero hecho de que lo que midiµ fue una
alfombra, un cuadro o un pedazo de papel, entonces, en el grado de tal diferencia, estarÚa daþada la fidelidad de aquÕlla en tanto que instrumento de
medida. La funciµn del instrumento de medida debe ser independiente de cada uno de los miembros de la clase de objetos para la que fue diseþada.
Es preciso tambiÕn que determinemos la amplitud de nuestro mÕtodo para medir actitudes. La construcciµn y la aplicaciµn de una escala de actitudes son dos
tareas muy diferentes, cosa que debe tenerse en cuenta. Si la escala ha de ser vÃlida, los valores escalares de las aseveraciones no deben ser afectados por
las opiniones de quienes hayan colaborado en su construcciµn. Tal condiciµn puede constituir una severa prueba en la prÃctica; pero el mÕtodo de elaboraciµn
de escalas debe cumplir con dicho requisito para que merezca aceptarse como algo mÃs que una simple descripciµn de la propia persona que la haya construido. De
cualquier modo, en la misma proporciµn en que el mÕtodo para elaborar la escala se vea afectado por las opiniones de los lectores que hayan contribuido a
clasificar las aseveraciones originales, asÚ podrà cuestionarse la validez o universalidad de la escala. Hasta no estar en poder de la prueba experimental al
respecto, daremos por sentado que los valores escalares de las aseveraciones son independientes de la distribuciµn de actitud, propia de los lectores que las
clasifican. En otras palabras, nuestra suposiciµn consiste en que dos afirmaciones de una escala de prohibiciµn del alcohol serÃn tan fÃciles o tan
difÚciles de discriminar, tanto para las personas que ingieran esa bebida como para las que no la ingieran. Dadas, pues, dos aseveraciones contiguas de tal
escala, suponernos que la proporciµn de bebedores que manifiestan que la aseveraciµn a expresa mÃs simpatÚa hacia el alcohol que la aseveraciµn b serÃ
esencialmente igual a la proporciµn correspondiente a las mismas aseveraciones, pero desde el punto de vista de un grupo de abstemios. Expresando aºn de otra
manera nuestra suposiciµn, diremos que tan difÚcil es para un militarista convencido como para un pacifista intransigente decidir cuÃl de dos
aseveraciones es la mÃs promilitarista. Si declaramos que el 85% de los militaristas seþala que la afirmaciµn A es mÃs militarista que la B, entonces,
conforme a nuestro postulado fundamental, la misma proporciµn de pacifistas emitirÚa el mismo juicio. Y de ser correcta esta suposiciµn, hallaremos, en
consecuencia, que la escala es un instrumento de mediciµn independiente de la actitud que se pretende evaluar. La
prueba experimental de esta suposiciµn consiste sencillamente en elaborar dos escalas referentes al mismo asunto y con el mismo conjunto de aseveraciones. Una
de dichas escalas se construirÚa con las respuestas de cientos de lectores simpatizantes del militarismo; y la otra escala, con las mismas aseveraciones,
pero partiendo de las respuestas de otros varios cientos de pacifistas. Si los valores escalares de cada aseveraciµn arrojan, prÃcticamente, resultados iguales
en ambas escalas, la validez del mÕtodo quedarà asÚ correctamente establecida. Pero todavÚa serà necesario usar discretamente las escalas de opiniµn, habida
cuenta de que podrÚan obtenerse, por ejemplo, resultados extraþos con la escala de prohibiciµn en un paÚs donde la prohibiciµn del alcohol no sea un problema.
b) Un criterio objetivo de ambig■edad. El anÃlisis de las curvas de la figura 2 revela que algunas de las aseveraciones del diagrama ficticio son mÃs ambiguas
que otras. El grado de ambig■edad de una aseveraciµn se aprecia de inmediato y puede medirse con precisiµn. La ambig■edad de una aseveraciµn es la desviaciµn estÃndard de la curva fi-gama de mejor ajuste, a travÕs de las proporciones
observadas. Cuanto mayor es la pendiente de la curva tanto menor es la amplitud de la escala sobre la cual hicieron su labor de clasificaciµn los lectores y mÃs
clara y mÃs precisa es la aseveraciµn. Cuanto mÃs suave es la pendiente de la curva, tanto mÃs ambigua es la aseveraciµn. De ahÚ que de las dos aseveraciones,
A y B, del diagrama ficticio, la aseveraciµn A sea la mÃs ambigua. En el caso de que se encuentre que la funciµn fi-gama no describe adecuadamente
las curvas de proporciones de la figura 2, el grado de ambig■edad puede medirse sin postular que las proporciones siguen la funciµn fi-gama cuando se dibujan en
la escala de actitud. Un mÕtodo simple para medir la ambig■edad serÚa entonces determinar la distancia escalar entre el valor escalar donde la curva de
proporciones tiene una ordenada de .25 y el valor escalar donde la misma curva tiene una ordenada de .75. TambiÕn puede definirse el valor escalar de la
aseveraciµn misma sin suponer la funciµn fi-gama, tomando el valor escalar donde la curva de proporciones llega a .50. Si no se encuentra proporciµn real en ese
valor, puede interpolarse el valor escalar de la aseveraciµn entre las proporciones experimentales inmediatamente por encima y por debajo del nivel de
.50. Para hacer una escala de las aseveraciones cuyos valores escalares caen fuera de las diez divisiones de aquella, serà necesario hacer algunas
suposiciones con respecto a la naturaleza de la curva y probablemente se encuentre que en la mayorÚa de las situaciones la funciµn fi-gama constituye una
buena aproximaciµn a la verdad. c) Un criterio objetivo de inadecuaciµn. Antes de que pueda hacerse la selecciµn
de los reactivos para la escala final, todavÚa debe aplicarse otro criterio: el criterio objetivo de inadecuaciµn. Volviendo a la figura 1, consideremos dos
afirmaciones que tengan valores escalares idÕnticos en el punto f. Supongamos, ademÃs, que estas dos afirmaciones se sometieron al juicio de grupo de lectores
representados en el diagrama ficticio de la misma figura. Es completamente concebible, y sucede realmente, que una de estas afirmaciones sea secundada muy
frecuentemente mientras que la otra solo lo sea rara vez, a pesar de que se hayan colocado adecuadamente en la escala, e impliquen el mismo grado de
pacifismo o militarismo. La conclusiµn inevitable entonces es que la aprobaciµn que un lector da a estas afirmaciones està determinada sµlo parcialmente por el
grado de pacifismo implicado y parcialmente por otros significados tambiÕn implicados que pueden o no estar relacionados con la variable de actitud
considerada. Es necesario, ahora, desde luego, seleccionar para la escala final de actitud las afirmaciones que son aprobadas o rechazadas fundamentalmente con
base en el grado de pacifismo-militarismo que està implÚcito en ellas y eliminar aquÕllas que son aceptadas o rechazadas frecuentemente segºn otros significados
inadecuados mÃs o menos sutiles. Se dispone de un criterio objetivo para realizar esta eliminaciµn
automÃticamente y sin introducir la ecuaciµn personal del investigador. Fundamentalmente es el siguiente: suponemos que la lista total de alrededor de
100 afirmaciones se ha sometido a varios cientos de lectores para votaciµn efectiva. No necesitan ser los mismos lectores que clasificaron las afirmaciones
con el propµsito de formular la escala. Se pide a estos lectores que marquen con un signo de mÃs cada afirmaciµn que ratifiquen y con un signo de menos cada
afirmaciµn que rechacen. Si deseamos investigar el grado de inadecuaciµn de una afirmaciµn particular
que, por ejemplo, podrÚa tener un valor escalar de 4.0, en la figura 3, debemos primero determinar cuÃntos lectores la aprobaron. Encontramos, por ejemplo, que
fueron 260 lectores. Este total se representa en el diagrama como el 100%, y levantamos tal ordenada en el valor escalar de dicha afirmaciµn. Ahora podemos
determinar la proporciµn de estos 260 lectores que tambiÕn ratificaron cada una de las demÃs afirmaciones. Si los lectores aprobaron y rechazaron las
afirmaciones basÃndose mayormente en el grado de pacifismo militarismo implicado, entonces los lectores que ratificaron afirmaciones prµximas a 4.0, en
la escala, no ratificarÃn a menudo las afirmaciones que estÃn muy lejos de ese punto de la escala. Siguiendo el ejemplo, muy pocos ratificarÚan una afirmaciµn
que està ubicada en el punto 8.0 de la escala. Si una gran proporciµn de los 60 lectores que ratifican la aseveraciµn bÃsica en el 4.0 de la escala, tambiÕn
ratifica una afirmaciµn en el punto 8.0 de la misma, debemos inferir entonces que su votaciµn en estas dos afirmaciones ha sido influida por factores
diferentes al grado de pacifismo implicado por dichas afirmaciones. Es posible representar grÃficamente este tipo de anÃlisis.
En este diagrama, cada una de las demÃs afirmaciones se representarà por un punto. Su valor "x" serà el valor escalar de la afirmaciµn y su valor "y" serÃ
la proporciµn de los 260 lectores que la hayan aprobado. Por tanto, si de los 260 lectores que ratificaron la afirmaciµn bÃsica hubiera 130 que ratificaron la
afirmaciµn nºmero 14, que tiene un valor escalar 5.0, por ejemplo, entonces la afirmaciµn nºmero 14 estarà representada por el punto A de la figura 3.
Si la afirmaciµn bÃsica, cuyo grado de inadecuaciµn està representado en la
figura 3, es de carÃcter ideal, que la gente aceptarà o rechazarà debido principalmente a la actitud sobre el pacifismo que expresa, debemos esperar
entonces que las 100 afirmaciones se representen por puntos mÃs o menos elevados cerca de la lÚnea interrumpida de la figura 3. Es obvio que el diagrama puede
estar mÃs contraÚdo o mÃs extendido, pero su aspecto general serÚa el de la figura 3. Si, por otra parte, la afirmaciµn bÃsica tiene implicaciones que
conducen a su aceptaciµn o rechazo, y son aquÕllas completamente independientes del grado de pacifismo que expresan, hallaremos que la proporciµn de
ratificaciones de las aseveraciones no serÚa una funciµn continua de sus distancias escalares desde la afirmaciµn bÃsica. AsÚ que el centenar de puntos
podrÚa dispersarse ampliamente en el diagrama. Este criterio de inadecuaciµn es objetivo y probablemente pueda expresarse en forma algebraica precisa para
eliminar totalmente la ecuaciµn personal del investigador. Se han desarrollado otros dos criterios objetivos de inadecuaciµn. Se
describirÃn junto con las escalas de actitudes que se estÃn elaborando. RESUMEN DEL MèTODO DE ELABORACIÆN DE ESCALAS
Es posible ahora seleccionar las aseveraciones que habrÃn de incluirse en la escala final. Para una aplicaciµn eficaz, debe seleccionarse una lista corta de
20 0 30 aseveraciones. Hemos descrito ya tres criterios para efectuar la selecciµn mencionada. Estos criterios san:
1. Las aseveraciones de la escala final deben seleccionarse de manera que constituyan al mÃximo posible una serie graduada y uniforme de valores
escalares. 2. Por medio del criterio objetivo de ambig■edad, se eliminan las afirmaciones que
proyecten demasiada dispersiµn en el continuo de actitud. La medida objetiva de ambig■edad es la desviaciµn estÃndar de la curva fi-gama, de mejor ajuste, que
se ilustra en la figura 2. 3. Mediante los criterios objetivos de inadecuaciµn, es posible eliminar, las
afirmaciones cuya aceptaciµn o rechazo provenga principalmente de factores diferentes al grado de la variable de actitud que representan. Uno de estos
criterios se ilustra en la figura 3. Los pasos para elaborar una escala de actitud pueden resumirse de la manera siguiente:
1. La especificaciµn de la variable de actitud que se va a medir. 2. La recolecciµn de una amplia variedad de opiniones acerca de la variable de
actitud especificada. 3 La ediciµn de este material en una lista de alrededor de cien breves aseveraciones de opiniµn.
4. La clasificaciµn de las aseveraciones en una escala imaginaria que represente a la variable de actitud. Esta tarea deben realizarla cerca de 300 lectores.
5. CÃlculo del valor escalar de cada aseveraciµn. 6. Eliminaciµn de algunas aseveraciones con el criterio de ambig■edad.
7.Eliminaciµn de algunas aseveraciones con los criterios de inadecuaciµn.
8. Selecciµn de una lista pequeþa de cerca de 20 aseveraciones graduadas uniformemente en la escala.
MEDICIÆN CON UNA ESCALA DE ACTITUD La aplicaciµn prÃctica de la tÕcnica de medida
presente consiste en mostrar la lista final de alrededor de 25 aseveraciones de opiniµn al grupo de interÕs, pidiÕndoles a los sujetos que marquen con signos de
mÃs todas las aseveraciones con las que estÕn de acuerdo y con signos de menos aquÕllas con las que discrepen. La calificaciµn de cada persona es el valor
escalar promedio de todas las afirmaciones que ha ratificado. Con el fin de que la escala sea efectiva en los extremos, es aconsejable que se extiendan las
aseveraciones de la escala en ambas direcciones, mucho mÃs allà de las actitudes que se encontrarÃn como valores medios de los individuos. Una vez determinada la
calificaciµn de cada persona, por la simple suma indicada, puede dibujarse una distribuciµn de frecuencia con respecto a las actitudes de cualquier grupo
especificado. La confiabilidad de la escala puede determinarse preparando dos formas paralelas
del mismo material y presentÃndolas a los mismos individuos. La correlaciµn entre las dos calificaciones obtenidas por cada persona de un grupo indicarÃ,
entonces, la confiabilidad de la escala. Puesto que la heterogeneidad del grupo afecta al coeficiente de confiabilidad, es necesario especificar la desviaciµn
estÃndar de las puntuaciones del grupo donde se determinµ el coeficiente de confiabilidad. TambiÕn puede calcularse, por un procedimiento anÃlogo, el error
estÃndar de una puntuaciµn individual. La unidad de medida de la escala construida por el procedimiento descrito no es
e{ error estÃndar discriminativo proyectado por una sola aseveraciµn en el continuo psicolµgico. La unidad de medida puede obtenerse por la aplicaciµn
directa de la ley del juicio comparativo, aunque esto es mucho mÃs laborioso que por el mÕtodo descrito aquÚ. La unidad de fa escala presente es mÃs arbitraria,
a saber, un dÕcimo de la amplitud del continuo psicolµgico que cubre la distancia que hay entre lo que los lectores consideran la ratificaciµn y la
negaciµn absolutas de la lista particular de afirmaciones iniciales. Por supuesto, pueden determinarse los valores escalares junto con la confiabilidad
de partes fraccionarias de esta unidad. Esperamos que pueda demostrarse experimentalmente que esta unidad es proporcional a una unidad de medida mÃs
precisa y universal que el error estÃndar universal de una sola aseveraciµn de opiniµn. Es lÚcito
determinar la tendencia central de la distribuciµn de frecuencia de las actitudes en un grupo. DespuÕs pueden compararse varios grupos de individuos con
respecto a las medias de sus distribuciones de frecuencias respectivas de actitudes. Las diferencias entre las medias de las diferentes distribuciones
pueden compararse directamente porque se ha establecido una lÚnea base racional. Estas comparaciones no son posibles cuando se determinan las actitudes contando
simplemente el nºmero de ratificaciones para separarlas de las afirmaciones cuyas diferencias escalares no se han medido.
AdemÃs de especificar la media de actitud de cada uno de los diferentes grupos, tambiÕn es posible medir su relativa heterogeneidad con respecto al asunto
considerado. Es posible asÚ, por medio de nuestros actuales mÕtodos de medida, descubrir, por ejemplo, que un grupo es 1.6 veces mÃs heterogÕneo en sus
actitudes acerca de la prohibiciµn del alcohol que algºn otro grupo. La heterogeneidad de un grupo se indica quizà mejor por la desviaciµn estÃndar de
los valores escalares de todas las opiniones que fueron ratificadas por el grupo como un todo y no por la desviaciµn estÃndar de la distribuciµn de las
puntuaciones individuales medias. QuizÃs tengan que adoptarse nombres diferentes para estos dos tipos de medida.
La tolerancia que una persona revela en cualquier asunto particular tambiÕn se puede sujetar a mediciµn cuantitativa Es la desviaciµn estÃndar de los valores
escalares de las afirmaciones que ratifica. La tolerancia mÃxima posible es, naturalmente, la indiferencia completa, en la que todas las aseveraciones son
ratificadas a lo largo de la amplitud entera de la escala. Si se desea saber cuÃl de dos formas de apelaciµn es la mÃs efectiva en un
asunto particular, puede determinarse usando la escala antes y despuÕs de aquÕllas. La diferencia entre las puntuaciones individuales, antes y despuÕs,
puede tabularse para medir el cambio promedio de actitud despuÕs de cualquier forma concreta de apelaciµn.
La caracterÚstica esencial del presente mÕtodo de medida es la escala de opiniones, graduadas uniformemente, y ordenadas de manera que los pasos o
intervalos iguales de la escala parezcan representar, para la mayorÚa de la gente, cambios igualmente notables de actitud.
LAS ACTITUDES PUEDEN MEDIRSE GENERALIDADES
FundÃndose en su experiencia en la mediciµn de capacidades y rasgos, Thurstone propuso un mÕtodo para medir la actitud. Se dijo que las aseveraciones
de opiniµn simbolizaban las actitudes y estas podÚan medirse desarrollando escalas con tal tipo de aseveraciones. Con tales escalas los individuos podrÚan
diferenciarse con respecto a sus actitudes de la misma manera que se podÚan determinar las diferencias individuales en inteligencia, capacidades o rasgos. Y
asÚ, en el principio de la historia de la mediciµn de actitudes, Thurstone adoptµ una posiciµn que favorecÚa el uso de muestras de informes sobre sÚ mismo.
Debido quizà al gran aprecio que los psicµlogos tenÚan a Thurstone y a la creciente popularidad del operacionalismo entre los psicµlogos, la tÕcnica de
aquel se adoptµ rÃpidamente. TambiÕn es importante hacer ver que su procedimiento de elaboraciµn de escalas incorporµ tÕcnicas establecidas de la
psicofÚsica. El mÕtodo de Thurstone, para elaborar escalas de actitud contenÚa varÚas
suposiciones estadÚsticas no verificadas, por lo que su aplicaciµn resultµ en extremo laboriosa. En 1932, Likert publicµ una
monografÚa que procurµ superar estas dos dificultades. Propuso un mÕtodo mÃs sencillo que no requerÚa el empleo de suposiciones estadÚsticas sin verificar.
Si el mÕtodo de Likert es adecuado, tal vez superior y alterno al mÕtodo de Thurstone, ha sido asunto de discusiµn
desde que apareciµ la citada monografÚa de Likert. Por desgracia, como a menudo ocurre en tales cuestiones, no hay corroboraciµn empÚrica que pueda usarse para
esclarecer el punto. Seiler y Hough han emprendido la bºsqueda de tales pruebas empÚricas. Mientras que persiste
claramente la necesidad de investigaciµn adicional antes de que la cuestiµn pueda resolverse, parecen estar ya esclarecidos dos asuntos:
a) "el mÕtodo de Likert de calificaciµn de una escala de actitud, con determinado numero de reactivos,
produce consistentemente resultados mÃs confiables que el mÕtodo de Thurstone para calificar la escala"
b) el mÕtodo de Likert para elaborar y calificar la escala requiere menos reactivos y produce la misina
confiabilidad que el mÕtodo de Thurstone. Un psicµlogo dijo una vez que, sin las dos guerras mundiales, la psicologÚa
social habrÚa muerto en la infancia. Sea o no cierta esta afirmaciµn, mientras estaba asignado al Departamento del EjÕrcito el sociµlogo Louis Gutman ideµ un
mÕtodo de elaboraciµn de escalas que se basa en suposiciones completamente diferentes a las de Thurstone y de Likert, ademÃs de tener un uso mÃs
diversificado. Su popularidad es mayor entre los investigadores de la actitud, pero es adecuado para medir por escala muchos otros universos de objetos.
Una de las limitaciones de los mÕtodos de Thurstone y de Likert es que pueden obtenerse calificaciones idÕnticas de varias maneras. AsÚ, no puede afirmarse que personas con la misma calificaciµn, ya sea en una escala de Thurstone o de
Likert, tengan la misma actitud. El mÕtodo de elaboraciµn de escalas, de Guttman, supera esta limitaciµn, Conociendo la puntuaciµn de una persona, en una
escala perfecta de Guttman, es posible reproducir la estructura entera de las respuestas de la persona a los reactivos de la escala. Esto se debe a que los
reactivos estÃn ordenados por nivel de dificultad y la puntuaciµn de la escala representa el nivel donde se fallµ. Desafortunadamente, las escalas perfectas de
Guttman nunca se logran en la prÃctica. Por consiguiente, es necesario estimar el error de reproductibilidad. Desde la primera presentaciµn de los
procedimientos de construcciµn de escalas de Guttman, se han hecho muchos esfuerzos para extender, modificar y afinar el mÕtodo, asÚ como desarrollar
tÕcnicas mÃs eficientes y sencillas con el mismo propµsito.
La discriminaciµn escalar, desarrollada por Edwards y Kilpatrick. Es una tÕcnica "nueva" solamente
porque combina los mÕtodos de Thurstone, Likert y Guttman. Sostienen que los mÕtodos de Thurstone y Likert proporcionan la base para seleccionar los
reactivos que se incluyen en una escala, mientras que el mÕtodo de Guttman permite evaluar los reactivos; presentan tambiÕn un procedimiento para
seleccionar reactivos, primero, por el mÕtodo de jueces, de Thurstone, y despuÕs, sometiendo los reactivos conservados a los criterios de selecciµn de
Likert. Los reactivos que satisfacen ambos grupos de criterios se examinan, finalmente, en cuanto a su reproductibilidad.
LA POSIBILIDAD DE MEDIR LAS ACTITUDES
El propµsito de este trabajo es estudiar el problema de la mediciµn de actitudes y opiniones, con miras a ofrecer una soluciµn. El mismo
hecho de ofrecer una soluciµn a un problema tan complejo como el de medir las diferencias de opiniµn o actitud sobre asuntos sociales en disputa, hace
evidente desde el principio que la soluciµn està mÃs o menos limitada y se aplica solamente bajo ciertas suposiciones que, sin embargo, serÃn tambiÕn
descritas. Al proponerme hallar un mÕtodo para medir las actitudes, he procurado echar a andar con las menos restricciones posibles porque, a veces, uno se
siente tentado a menospreciar tantos factores que desaparece el problema original. Yo espero que no se me acusarà de eludir el problema.
Para medir las actitudes algunas suposiciones de sentido
comºn que serÃn expresadas, desde un principio, buscÃndose siempre que la discusiµn subsecuente no se vea ensombrecida a causa de ellas. Si el lector no
està dispuesto a aceptar estas suposiciones, entonces no tendremos nada que ofrecerle. Si las acepta, podemos proceder a describir algunos mÕtodos de
mediciµn que deben dar lugar a resultados interesantes. Es necesario expresar desde ahora lo que queremos significar
por los tÕrminos "actitud" y "opiniµn". Esto es del todo necesario porque la primera impresiµn es que estos dos conceptos no son susceptibles de medida en
ningºn sentido real. Se aceptarà que una actitud es un asunto complejo que no puede describirse totalmente con ningºn Úndice numÕrico aislado. En cuanto al
problema de medir, esta afirmaciµn es anÃloga a la observaciµn de que una mesa ordinaria es una cosa compleja que no puede describirse totalmente con ningºn
Úndice numÕrico aislado. De la misma manera, un hombre es de tal complejidad que no puede representarse completamente con un sµlo Úndice. Sin embargo, no
vacilamos en decir que medimos la mesa. El contexto generalmente seþala lo que nos proponemos medir de la mesa. Decimos sin vacilaciµn que medimos a un
individuo cuando tomamos algunas medidas antropomÕtricas de Õl. El contexto puede implicar correctamente quÕ aspecto del individuo estamos midiendo, sin
declaraciµn explÚcita, por ejemplo, su Úndice cefÃlico, su altura o su peso. Justamente en ese mismo sentido hablamos aquÚ de medir las actitudes.
Expresaremos o implicaremos por el contexto quÕ aspecto de las actitudes, de las personas nos proponemos medir. El interrogante estriba en que tan legÚtimo es
decir que medimos actitudes como afirmar que medimos mesas u hombres.
El concepto de "actitud" se usarà aquÚ para denotar la suma total de inclinaciones y sentimientos, prejuicios o distorsiones, nociones
preconcebidas, ideas, temores, amenazas y convicciones de un individuo acerca de cualquier asunto especÚfico. La actitud de una persona acerca del pacifismo
significa todo lo que piensa y siente acerca de la paz y la guerra. Aceptase asimismo que esto es un asunto subjetivo y personal.
El concepto "opiniµn" significarà aquÚ la expresiµn verbal de
la actitud. Si una persona dice que cometimos un error Ãl entrar en la guerra contra Alemania, Õsa afirmaciµn serà considerada aquÚ como una opiniµn. El
tÕrmino "opiniµn" se restringirà a la expresiµn verbal. Pero ¢de quÕ es una expresiµn? Supuestamente expresa una actitud. No tiene por quÕ haber dificultad
para entender el empleo de los dos tÕrminos. La expresiµn verbal es la opiniµn. Nuestra interpretaciµn de la opiniµn expresada es que la actitud del individuo
es pro-germana. Una opiniµn simboliza una actitud. Nuestro siguiente punto se refiere a quÕ deseamos medir. Cuando una persona dice que cometimos un error al entrar a la guerra contra
Alemania, lo que nos interesa no es realmente la secuencia de palabras como tales y ni siquiera el significado inmediato que la oraciµn implica, sino mÃs
bien la actitud de quien la dijo, sus pensamientos y sentimientos acerca de los Estados Unidos, de la guerra y de Alemania. Es la actitud lo que realmente
interesa. La opiniµn tiene interÕs ºnicamente si la interpretamos como sÚmbolo de la actitud. Por consiguiente, es alguna cosa propia de las actitudes lo que
deseamos medir. Usaremos las opiniones como medios para medir las actitudes.
Pero nos viene a la mente la incertidumbre de usar una opiniµn como Úndice de actitud, pues el individuo puede ser un embustero. Si no
deforma intencionalmente su actitud real sobre un asunto en disputa, puede modificar, sin embargo, su expresiµn, por razones de cortesÚa, especialmente en
situaciones donde la expresiµn franca de la actitud puede no ser bien recibida. Esto ha conducido a la idea de que, por encima de lo que dice, la acciµn de un
individuo es un Úndice mÃs seguro de su actitud. Pero sus acciones tambiÕn pueden ser distorsiones de su actitud. Un polÚtico comunica amistad y
hospitalidad en la acciµn manifiesta, mientras que esconde otra actitud que expresa mÃs fielmente a un amigo Úntimo. Ni sus opiniones ni sus actos
manifiestos constituyen, en ningºn sentido, una guÚa infalible de las inclinaciones subjetivas y preferencias que constituyen su actitud. Por
consiguiente, debemos conformarnos con usar las opiniones, u otras formas de acciµn, como simples Úndices de actitud. Debe reconocerse que existe cierta
discrepancia, algºn error de medida, entre la opiniµn o acciµn manifiesta que usamos como Úndice y la actitud que inferimos de tal Úndice.
Pero esta discrepancia entre el Úndice y la "verdad" es universal. Cuando desea saber la temperatura de su habitaciµn, la persona ve el
termµmetro y usa la lectura como Úndice de la temperatura, como si no hubiera error en el Úndice y como si hubiera una sola lectura que fuera la "correcta" de
la habitaciµn. Cuando se desea determinar el volumen de un vaso de papel, se postula que el volumen es un atributo del vaso, aunque aquÕl sea, en realidad,
una abstracciµn. Se mide indirectamente observando las dimensiones del vaso o sumergiÕndolo en agua para apreciar cuÃnto lÚquido desplaza. Estos dos
procedimientos dan dos Úndices que podrÚan no concordar exactamente. En casi cualquier situaciµn de mediciµn se postula un continuo abstracto como el volumen
o la temperatura; y la ubicaciµn de la cosa medida dentro de ese continuo se realiza generalmente por medios indirectos, a travÕs de uno o mÃs Úndices. La
verdad se infiere solamente por la consistencia relativa de los diferentes Úndices, ya que nunca se conoce de modo directo. Y nos enfrentamos al mismo tipo
de situaciµn cuando intentamos medir la actitud. Necesitamos postular una variable de actitud que es, prÃcticamente, semejante a todos los demÃs atributos
mensurables de la esencia de un continuo abstracto, y debemos encontrar uno o mÃs Úndices, los cuales nos satisfarÃn en el grado en que tengan consistencia
interna. En el presente estudio mediremos la actitud del sujeto segºn
sea expresada por la aceptaciµn o rechazo de opiniones. Pero este enunciado no significa que ese sujeto necesariamente actuarà conforme a las opiniones que
haya apoyado. Aclaremos esta limitaciµn. La mediciµn de actitudes, expresada por las opiniones de un individuo, no constituye a la vez, y forzosamente la
predicciµn de lo que harÃ. Que sus opiniones expresadas y sus acciones sean inconsistentes, es algo que no nos concierne ahora, porque no manifestamos que
nos proponemos predecir la conducta abierta. Supondremos que es de interÕs saber lo que las personas dicen que creen aunque su conducta sea inconsistente con las
opiniones que expresen. Incluso en el caso de que distorsionen intencionalmente sus actitudes, por lo menos mediremos las actitudes que tratan de hacer creer a
los demÃs. Concedemos, por otra parte, que las actitudes de las personas
estÃn sujetas a cambio. Cuando medimos la actitud de un individuo, sobre un asunto como el pacifismo, no afirmamos que tal medida sea en ningºn sentido
una constante permanente o constitucional. Su actitud puede cambiar, por supuesto, de un dÚa para otro; y es nuestra tarea medir tales cambios que acaso
resulten de causas desconocidas o de la presencia de algºn factor persuasivo conocido, como la lectura de una disertaciµn sobre el asunto en cuestiµn. Sin
embargo, tales fluctuaciones pueden tambiÕn atribuirse, en parte, a error en las medidas mismas. Para aislar los errores del instrumento de medida, por la
fluctuaciµn real de la actitud, debemos calcular el error estÃndar de medida de la escala misma, lo cual puede realizarse por mÕtodos bien conocidos en la
mediciµn mental. Supondremos que una escala de actitud se usa solamente en las
situaciones en que se puede esperar razonablemente que las personas digan la verdad sobre sus opiniones o convicciones. Si una escuela religiosa fuera
aplicar a sus estudiantes una escala de actitudes acerca de la iglesia, difÚcilmente se esperarÚa que los estudiantes inteligentes dijeran la verdad
acerca de sus convicciones, si Õstas estuviesen desviadas de las creencias ortodoxas. Lo menos que podrÚa hacerse serÚa analizar los resultados, si la
situaciµn en que se expresasen las actitudes contuviera presiµn o amenaza implÚcita, basadas directamente en la actitud que se va a medir. De manera
similar serÚa difÚcil descubrir las actitudes sobre la libertad sexual por medio de un cuestionario escrito, debido a la presiµn universal a ocultar tales
actitudes cuando se desvÚan de las convenciones supuestas. Se admite que las escalas de actitud se usarÃn solamente en las situaciones que ofrezcan un mÚnimo
de presiµn sobre la actitud que va a medirse. Tales situaciones son bastante comunes.
Todo lo que podemos hacer con una escala de actitud es medir la actitud expresada efectivamente, con la comprensiµn plena de que el sujeto
puede estar escondiendo conscientemente su actitud verdadera o que la presiµn social de la situaciµn le ha hecho creer realmente lo que està expresando. Este
es asunto de interpretaciµn, y probablemente valioso en tanto se mide una actitud expresada en opiniones. Otro problema es el de interpretar en cada caso
el grado en que los sujetos han expresado lo que realmente creen. Todo lo que podemos hacer es reducir cuanto sea posible las condiciones que impiden que los
sujetos digan la verdad, o en vez de eso ajustar nuestras interpretaciones de acuerdo a esas condiciones.
Cuando discutimos opiniones, por ejemplo acerca de la prohibiciµn del alcohol, pronto encontramos que estas opiniones son
multidimensionales, es decir, que no pueden representarse en un continuo lineal. Las diferentes opiniones no pueden describirse, completamente, sµlo con "mÃs" o
"menos". Se dispersan en muchas dimensiones, pero la misma idea de medida implica un continuo lineal de alguna clase como longitud, precio, volumen, peso,
edad. Cuando la idea de medida se aplica al logro acadÕmico, por ejemplo, es necesario forzar las variaciones cualitativas en una escala lineal acadÕmica de
alguna clase. Juzgamos, de manera semejante, cualidades como destreza mecÃnica, calidad de la escritura a mano y la cantidad de educaciµn de un individuo, como
si estos rasgos se extendieran sobre una sola escala, aunque en el terreno de los hechos se dispersen en muchas direcciones. Cierto es que avanzamos
adecuadamente con el concepto de escala, al describir rasgos todavÚa cualitativos, como educaciµn, posiciµn social y econµmica o belleza. Pero se
impone una escala o continuo lineal cuando decimos que un individuo tiene mÃs educaciµn que otro o que una mujer es mÃs bella que otra, aunque, si somos
presionados, admitimos que quizà el par de que constan cada una de las comparaciones tiene poco en comºn. Resulta claro que el continuo lineal
implÚcito en un juicio de "mÃs o menos" puede ser conceptual; y no necesariamente ha de tener la existencia fÚsica de una regla.
Y lo mismo sucede con las actitudes. No hay que dudar en
compararlas por medio del tipo de juicio de "mÃs o menos"; se dice, por ejemplo, que un individuo està mÃs en favor de una prohibiciµn que de otra; y tal juicio
comunica su significado claramente, con la implicaciµn de una escala lineal en la que pueden ubicarse las personas o las opiniones.
LA VARIABLE DE ACTITUD
La primera restricciµn en el problema de la mediciµn de actitudes es especificar una variable de actitud y hasta allÚ limitar la medida.
Vamos a ilustrarlo considerando la cuestiµn de la prohibiciµn del alcohol y tomemos como variable de actitud el grado de restricciµn que debe imponerse a la
libertad individual en el consumo de esa bebida. Este grado de restricciµn puede considerarse un continuo que va desde la libertad completa y grado hasta la
restricciµn igualmente completa y absoluta, e incluirÚa, desde luego, actitudes neutrales e indiferentes.
Al recolectar muestras para elaborar una escala, pedirÚamos a cien personas que escribieran sus opiniones acerca de la prohibiciµn.
Encontraremos entre ellas a quienes expresen la creencia de que la prohibiciµn ha incrementado el uso del tabaco. Indudablemente esta es una opiniµn
concerniente a la prohibiciµn, pero no serÚa ºtil en absoluto para medir la variable de actitud mencionada. Por tanto, serÚa inadecuada. Otra persona podrÚa
expresar la opiniµn de que la prohibiciµn ha eliminado una fuente importante de impuestos gubernamentales. Esta tambiÕn es una opiniµn referente a la
producciµn, pero no pertenecerÚa a la variable de actitud particular que hemos manifestado medir o evaluar por escala. Es preferible usar un criterio objetivo
y experimental para eliminar las opiniones que no pertenezcan al continuo especificado que se va a medir, y creo que tal criterio existe.
Esta restricciµn en el problema de la mediciµn de actitudes
es necesaria por la misma naturaleza de la medida; y se presupone en toda medida ordinaria, por lo que debe quedar claro que se aplica tambiÕn donde las
caracterÚsticas multidimensionales todavÚa no se hayan separado abiertamente. Por ejemplo, serÚa casi ridÚculo decir que no puede medirse una mesa a menos que
uno diga o implique lo que se va a medir de ella, es decir, si es su altura, costo, belleza, grado de adecuaciµn o el tiempo requerido para hacerla. El
contexto implica ordinariamente esta restricciµn en la medida. Cuando la nociµn de medida se aplica a un fenµmeno tan complejo como las opiniones y actitudes,
tambiÕn debemos restringirnos a un continuo especÚfico o implicado dentro del cual se va a medir.
Para especificar la variable de actitud, el primer requisito es expresarla de tal modo que se la pueda aludir en tÕrminos de "mÃs" y "menos",
como es el caso cuando comparamos las actitudes de las personas diciendo que una de ellas es mÃs pacifista, que esta aboga mÃs por la prohibiciµn, que aquÕlla
apoya mÃs fuertemente la pena capital, o que es mÃs religiosa que otra persona.
La figura 1 representa la variable de actitud militarismo pacifismo, con una zona neutral. Una persona que generalmente habla en favor de
prepararse militarmente, por ejemplo, se representarÚa en algºn punto a la derecha de la zona neutral. Una persona que està mÃs interesada en el desarme se
representarÚa a la izquierda de la zona neutral. Es posible concebir una curva de frecuencia que represente la distribuciµn de la actitud en un grupo
especificado sobre el asunto de pacifismo-militarismo.
Consideremos la ordenada de la distribuciµn de frecuencia en un punto de la lÚnea de base. El punto y su vecindad inmediata representa una
actitud, y deseamos saber relativamente quÕ tan comºn es ese grado de sentimiento en favor o en Pacifismo Naturalidad Militarismo
contra del pacifismo dentro del grupo en estudio. Es de interÕs secundario saber que una declaraciµn particular de opiniµn es ratificada por cierta proporciµn de
ese grupo. Y solamente en el grado en que la opiniµn sea representativa de una actitud, serà ºtil para nuestros propµsitos. Posteriormente consideraremos la
posibilidad de que una opiniµn. declarada pueda ubicarse en la escala coma pacifista y, sin embargo, sea ratificada por una persona de simpatÚas
militaristas muy pronunciadas. En el grado en que la aseveraciµn sea apoyada o rechazada por factores distintos a la variable de actitud que representa, tal
aseveraciµn no servirà para nuestros propµsitos. TambiÕn consideraremos un criterio efectivo para descubrir semejantes aseveraciones de manera que puedan
eliminarse de la escala. Entonces, en nuestro estudio, trataremos con opiniones, no principalmente por su contenido cognoscitivo sino porque sirven de portadores
o sÚmbolos de las actitudes de las personas que las expresa o respalda.
Hay alguna ambig■edad al usar el tÕrmino actitud en plural. Una actitud se representa como un punto en el continuo de actitud. Consecuentemente, hay un
nºmero infinito de actitudes que pueden representarse en la escala. Sin embargo, en la prÃctica no diferenciamos tan finamente. En realidad, una actitud,
prÃcticamente hablando, consiste en cierta amplitud o cercanÚa estrecha dentro de la escala. Cuando se obtiene una distribuciµn de frecuencia de una variable
continua, como la estatura, clasificamos dicha variable en pasos o intervalos de clase, con propµsitos descriptivos. La variable de actitud tambiÕn puede
dividirse en intervalos de clase y contarse la frecuencia en cada intervalo. Cuando hablemos de "una" actitud, significaremos un punto o una vecindad en el
continuo de la actitud. Diferentes actitudes se considerarÃn no como un conjunto de entidades distintas sino como una serie de intervalos de clase en la
escala de actitud. UNA DISTRIBUCIÆN DE FRECUENCIA DE ACTITUDES
La principal argumentaciµn ha sido hasta ahora mostrar que ya que en la conversaciµn ordinaria describimos rÃpida y comprensiblemente a los individuos
como mÃs o menos pacifistas o mÃs o menos militaristas en actitud, podemos representar abiertamente esta linealidad en la forma de una escala
monodimensional; y asÚ se ha hecho, en forma de diagrama, en la figura 1. Describiremos primero nuestro objetivo y despuÕs mostraremos cµmo puede
adoptarse una unidad de medida racional para la escala entera.
Sea la lÚnea base de la figura 1 la representaciµn de una amplitud continua de actitudes, desde el pacifismo extremo, a la izquierda, hasta el militarismo
extremo a la derecha. Si se definieran varios pasos en semejante escala, la
actitud de una persona hacia el militarismo-pacifismo podrÚa representarse por un punto de esa escala. La fuerza y direcciµn de las simpatÚas de un individuo
particular podrÚan indicarse por el punto a, que muestra opiniones mÃs bien militaristas. Otro individuo podrÚa quedar en el punto b, indicador de que,
aunque es ligeramente militarista en sus opiniones, no lo es al extremo de la persona que se colocµ en el punto a. Una tercera persona se colocarÚa en el
punto c, indicÃndose asÚ que es completamente militarista y que la diferencia entre a y c es muy pequeþa. Es posible una interpretaciµn similar que se
extendiera a cualquier punto de la escala continua, desde el extremo militarismo hasta el extremo pacifismo, con una regiµn neutral o de indiferencia entre
ellos. Una segunda caracterÚstica podrÚa igualmente indicarse grÃficamente por medio de
la escala, a saber, la amplitud de las opiniones que determinado individuo estÕ dispuesto a respaldar. Por supuesto, no debe esperarse que cada persona encuentre
solamente una sola opiniµn, a la que estÕ dispuesto a dar su apoyo, en la escala completa, ni tampoco que rechace todas las demÃs. En realidad, nosotros mismos
probablemente nos encontrarÚamos dispuestos a ratificar gran nºmero de opiniones que cubren cierta amplitud de la escala. Entonces, es concebible que una persona
pacifista estÕ dispuesta a ratificar todas o la mayorÚa de las opiniones en la amplitud de "d a e" y que rechace como demasiado pacifistas la mayorÚa de las
opiniones a la izquierda de d, y que tambiÕn rechace la amplitud entera de opiniones militaristas. Su actitud se indicarÚa entonces por el promedio o media
de la amplitud que ratifica, a menos que tenga el cuidado de seleccionar una opiniµn particular que represente muy cercanamente su propia actitud. La misma
clase de razonamiento puede extenderse con la misma certidumbre a la amplitud total de la escala, asÚ que tendrÚamos por lo menos dos, o posiblemente tres,
caracterÚsticas distintivas de cada persona con base en la escala. Estas caracterÚsticas serÚan:
a) la posiciµn media que ocupa en la escala;
b) la amplitud de opiniones que està dispuesto a aceptar, y
c) la opiniµn que selecciona porque representa con mayor aproximaciµn su propia actitud sobre el
asunto planteado. Asimismo, serÚa posible describir a un grupo de individuos por medio de la
escala. Este tipo de descripciµn ha sido representado en forma de diagrama por el perfil de frecuencia.
Cualquier ordenada de la curva representarÚa el nºmero de individuos, o el porcentaje del grupo total, que secunda la opiniµn correspondiente. Por ejemplo,
la ordenada, en b, representarÚa el nºmero de personas del grupo que ratifican el grado de militarismo representado por el punto b de la escala. Una mirada a
la curva de frecuencia muestra que en el grupo ficticio de este diagrama, las opiniones militaristas son ratificadas mÃs frecuentemente que las pacifistas.
Claro està que el Ãrea de este diagrama de frecuencia representa el nºmero total de ratificaciones hechas por el grupo. El diagrama puede arreglarse de varias
maneras diferentes que estudiaremos por separado. En este momento, basta con que nos percatemos de que en una escala vÃlida de opiniones es posible comparar
varios grupos diferentes de acuerdo a sus opiniones sobre una cuestiµn en disputa.
Un segundo tipo de comparaciµn de grupo puede hacerse con respecto a la amplitud o extensiµn que presentan las superficies de frecuencia. Si uno de los grupos se
representa por un diagrama de frecuencia de considerable amplitud o dispersiµn, entonces ese grupo serà mÃs heterogÕneo respecto al asunto planteado, que algºn
otro grupo cuyo diagrama de frecuencia de actitudes presente una amplitud o dispersiµn mÃs pequeþa. Lo anterior no significa que la suposiciµn de una
distribuciµn normal, de uso frecuente en la elaboraciµn de escalas educativas, tenga alguna aplicaciµn aquÚ, porque no hay razµn para suponer que un grupo de
personas estÕ distribuido normalmente en sus opiniones acerca de alguna cosa. Por consiguiente, es posible hacer cuatro tipos de descripciones por medio de una escala de actitudes. EstÃs son:
a) la actitud promedio o media de un individuo particular sobre el asunto en cuestiµn;
b) la amplitud de opiniones que està dispuesto a aceptar o a tolerar; c) la popularidad rÕlativa de cada actitud de la escala dentro de un grupo seþalado como lo indica la
distribuciµn de frecuencia de ese grupo, y d) el grado de homogeneidad o heterogeneidad de las actitudes de un grupo seþalado acerca del asunto, como lo indica el grado de dispersiµn
o extensiµn de su distribuciµn de frecuencia. Este es el objetivo. El centro del problema està en la unidad de medida de la lÚnea base, que es lo que veremos en el siguiente articulo
Las estimaciones en el estudio de evaluaciµn de psicµlogos clÚnicos Los ejemplos hasta aquÚ presentados presentan un lamentable cuadro sobre la validez de las medidas de las diferencias individuales
consideradas. El caso tÚpico exhibe una cantidad excesiva de varianza de mÕtodo, que suele exceder la cantidad de varianza de rasgo. Este cuadro no se debe a un
esfuerzo deliberado de seleccionar ejemplos ostensiblemente malos. Los estudios no publicados muestran el mismo cuadro. Si parecen
mÃs desalentadores que la tendencia general de los datos de validez informados en las revistas, puede ser porque la apariencia de validez que proporcionan los
valores aislados que se desprenden de la diagonal de validez es engaþosa e imposible de interpretar al margen de la matriz total. Sin embargo, claro estÃ
que pocos de los ejemplos clÃsicos de buena mediciµn de las diferencias individuales intervienen y que en muchos de los casos la calidad de los datos
pudo haber magnificado los factores de aparato, etcÕtera. Un conjunto de datos de personalidad mÃs ideal para ejemplificar el mÕtodo, por tanto, se encontrµ en
la aplicaciµn mºltiple de un conjunto de escalas de estimaciµn al estudiar la evaluaciµn de los psicµlogos clÚnicos (Kelly y Fiske, 1951).
En este estudio, la "escala de estimaciµn A" contenÚa 22 rasgos referentes a "la conducta que puede observarse directamente en la
superficie". En el uso de la escala se instruyµ a los estimadores para que "descartaran cualesquiera inferencias acerca de dinÃmicas o causas subyacentes". Los sujetos, estudiantes de psicologÚa clÚnica de primer aþo, se
estimaron a sÚ mismos y tambiÕn a sus tres compaþeros de equipo con los que habÚan participado en varios procedimientos de evaluaciµn y habÚan vivido
durante seis dÚas. Se usµ la mediana de las estimaciones de los tres compaþeros de equipo para la puntuaciµn de compaþero de equipo. Los sujetos tambiÕn fueron
estimados con respecto a los 22 rasgos por la direcciµn de evaluaciµn. El anÃlisis usa las estimaciones finales combinadas que fueron convenidas por tres
miembros de la direcciµn despuÕs de la discusiµn y revisiµn de la enorme cantidad de datos y las muchas otras estimaciones de cada sujeto.
Desafortunadamente, los miembros de la direcciµn vieron las estimaciones de sÚ mismo y las de los compaþeros de equipo antes de hacer
las suyas, aunque presumiblemente fueron poco influidos por estos datos, pues tenÚan a su alcance otras seþales de evidencia. (Kelly y Fiske, 1951). Las estimaciones de sÚ mismo y las de los compaþeros
de equipo representan enteramente "mÕtodos" distintos y se les puede dar mayor importancia al evaluar los datos que van a ser presentados.
En un anÃlisis previo de estos datos (Fiske, 1949), cada uno de los tres triÃngulos heterorrasgo-monomÕtodo fue computado y factorizado. Para
proporcionar una matriz multirrasgo-multimÕtodo, las 1 452 correlaciones de heteromÕtodo fueron computadas especialmente para este informe. La matriz
completa de 66 X 66 con sus 2 145 coeficientes es obviamente demasiado grande para presentarla aquÚ, pero serà usada en el anÃlisis que sigue. Para
proporcionar una muestra ilustrativa, la tabla 12 presenta las interrelaciones entre cinco variables, seleccionando la que representa mejor cada uno de los
cinco factores recurrentes descubiertos en el anÃlisis previo de las matrices monomÕtodo de Fiske (1949). (Fueron escogidas independientemente de su validez
indicada en los bloques heteromÕtodos. "Asertivo" -reflejado en el nºm. 3- fue seleccionado para representar el factor recurrente 5, debido a que "locuaz"
tambiÕn obtuvo una alta carga en el primer factor recurrente).
El cuadro presentado en la tabla 12 es
representativo de la mejor validez de las estimaciones de rasgo de personalidad que la psicologÚa puede ofrecer actualmente. Es confortante advertir que el
cuadro es mejor que el de la mayorÚa de los previamente examinados. Nµtese que los valores de validez de "asertivo" exceden los valores de heterorrasgo de los
triÃngulos monomÕtodo y heteromÕtodo. "Alegre", "de intereses amplios" y "serio"
tienen validez que excede los valores de heterorrasgo-heteromÕtodo con dos excepciones. Solamente para "equilibrio inmutable" la evidencia de validez
parece trivial. La elevaciµn de las confiabilidades por encima de los triÃngulos heterorrasgo- mono mÕtodo es la evidencia mÃs amplia de validez discriminante.
Una comparaciµn de la tabla 12 con la matriz completa muestra que el procedimiento de una sola variable que represente cada factor ha
acrecentado la apariencia de validez, aunque no necesariamente de un modo engaþoso. Donde varias variables son influidas altamente por el mismo factor, su
nivel "verdadero" de intercorrelaciµn es alto. En estas condiciones, los errores de muestreo pueden hacer disminuir los valores de la diagonal de validez y
agrandar otros para producir excepciones ocasionales al cuadro de validez, tanto en la matriz heterorrasgo-monomÕtodo como en los triÃngulos heteromÕtodo-heterorrasgo.
En este caso, con una N de 124, el error de muestreo es apreciable, y de esta manera puede esperarse que se exagera el grado de invalidez.
Dentro de las secciones de monomÕtodo, los errores de medida se correlacionan al elevar el nivel general de los valores encontrados, mientras
que dentro de los bloques de heteromÕtodo, los errores de medida son independientes, y a lo largo de la diagonal de validez y los triÃngulos de
heterorrasgo la validez tiende a decrecer. Estos efectos, que tambiÕn pueden ser establecidos en tÕrminos de factores de mÕtodo o insignificancias comunes de
confusiµn operan fuertemente en estos datos, como probablemente en todos los datos que contienen estimaciones. Cuando diversas variables representan a cada
factor, ninguna de las variables satisface consistentemente el criterio de que los valores de validez exceden los valores correspondientes en los triÃngulos de
monomÕtodo, cuando se examina la matriz completa. Como resumen del cuadro de validaciµn con respecto a las
comparaciones de valores de validez con otros valores de heteromÕtodo en cada bloque, se ha preparado la tabla 13. Para cada rasgo y para cada uno de los tres
bloques de heteromÕtodo, el valor de fa diagonal de validez presenta el valor heterorrasgo mÃs alto que lo incluye y el nºmero de los 42 valores heterorrasgo
semejantes que exceden a la diagonal de validez en magnitud. (El nºmero 42 procede de la agrupaciµn de los 21 valores de las otras columnas y de los 21
valores de los otros renglones para la columna y el renglµn que interceptan al valor diagonal dado).
Acerca del requisito de que la diagonal de validez exceda a todas las otras en su bloque de heteromÕtodo, ninguno de los rasgos tiene un registro completamente
perfecto, aunque algunos se acercan bastante. "Asertivo" tiene solamente una excepciµn trivial en el bloque "compaþeros de equipo-sÚ mismo". "Locuaz" tiene
casi un registro tan bueno como "imaginativo". Serio tiene solo dos excepciones inconsecuentes e "interÕs en las mujeres", tres. Estos rasgos se destacan como
sumamente vÃlidos de la descripciµn de sÚ mismo y la reputaciµn. Nµtese que los coeficientes de validez reales de estos cuatro rasgos se extienden desde .22 a
.82, o si nos concentramos en el bloque "compaþero de equipo-sÚ mismo", que seguramente representa mÕtodos mÃs independientes, desde .31 a .46. Aunque estos
son los mejores rasgos, parece que la mayorÚa de ellos tienen una validez mÃs que fortuita. Todos los que tienen 10 o menos excepciones poseen un grado de
validez significativo en el nivel .001, estimado a bulto por la prueba de tos signos de una cola. Si tomamos el valor de la validez como fijo (ignorando
sus fluctuaciones muÕstrales), podemos determinar si el nºmero de valores mÃs grandes que Õl en su renglµn y columna es menor que el esperado sobre la
hipµtesis de nulidad de que la mitad de los valores estarà por encima de Õl. Este procedimiento requiere la suposiciµn de que la posiciµn (por encima o por
debajo del valor de la validez) de cualquiera de estos valores de comparaciµn es independiente de la posiciµn de cada uno de los demÃs, una suposiciµn dudosa
cuando se emplean los mÕtodos comunes y la varianza de rasgo. Con la excepciµn de una variable, todas satisficieron este nivel en el bloque "direcciµn-compaþero de
equipo", todas menos cuatro en el bloque "direcciµn-sÚ mismo", todas menos cinco en el bloque mÃs independiente, "compaþero de equipo-sÚ mismo". Sin embargo, las
excepciones a la validez significativa no son paralelas de columna a columna, y solamente 12 de las 22 variables tienen validez significativa de .001 en los
tres bloques. Estas se indican por un asterisco en la tabla 13. Este nivel general de alta significaciµn de la validez no debe oscurecer el interesante problema creado por las excepciones ocasionales,
aun ante las mejores variables. Los excelentes rasgos de "asertivo" y "locuaz" proporcionan un caso a propµsito. En tÕrmino del anÃlisis original de Fiske,
ambos tienen fuertes cargas en el factor recurrente "seguro de sÚ mismo" (representado por "asertivo" en la tabla 12). "Locuaz" tambiÕn tuvo una fuerte
carga en el factor recurrente de "adaptabilidad social" (representado por "alegre" en la tabla 12). EsperarÚamos, por consiguiente, una correlaciµn alta
entre ellos, asÚ como discriminaciµn significativa. Incluso en el nivel del sentido comºn, la mayorÚa de los psicµlogos esperarÚan que sus colegas
discriminen vÃlidamente entre la asertividad o positividad (no sumisiµn) y la locuacidad. Sin embargo, en el bloque "compaþero-sÚ mismo", "asertivo" estimado
por sÚ mismo correlaciona .48 con "locuaz" por compaþeros de equipo, mÃs altamente que cualquiera de sus valores de validez en este bloque, .43 y .46.
En tÕrminos del promedio de los valores de validez y la frecuencia de las excepciones, hay una clara tendencia del bloque
"direcciµn-compaþero" a mostrar el mÃs alto acuerdo. Esto puede atribuirse a varios factores. Ambos representan estimaciones desde el punto de vista externo.
Ambos son promediados para los tres jueces, y asÚ se reducen al mÚnimo las distorsiones individuales e indudablemente se incrementan las confiabilidades.
AdemÃs, las estimaciones de los compaþeros de equipo fueron asequibles a la direcciµn al hacer sus estimaciones. Otro efecto contribuyente a la convergencia
y discriminaciµn menos adecuadas de las estimaciones de sÚ mismo fue un conjunto de respuestas hacia el polo favorable que redujo grandemente el rango de estas
medidas (Fiske, 1949). El anÃlisis de los detalles de los casos de invalidez que se resumen en la tabla 13 muestra que la mayorÚa de los casos el
efecto es atribuible a la alta especificidad y baja comunalidad para la forma de estimaciµn de sÚ mismo. En estos casos, la columna y el renglµn que intersecan
la diagonal de validez baja son asimÕtricas hasta donde se relaciona el nivel general de correlaciµn, hecho que apoya la condensaciµn que proporciona la tabla
13. El psicµlogo de la personalidad està inicialmente predispuesto a reinterpretar las estimaciones de sÚ mismo, a tratarlas como
sÚntomas en vez de interpretarlas literalmente. Se tuvo cuidado con los casos en que las estimaciones de sÚ mismo no fueron literalmente interpretables,
pero no dejaron de tener un significado de diagnµstico cuando se "tradujeron" apropiadamente. De cualquier modo, los casos de invalidez de las descripciones
de sÚ mismo del estudio de evaluaciµn no son de este tipo, sino mÃs bien se explican en tÕrminos de la ausencia de comunidad para una de las variables
involucradas. En general, donde estas descripciones de sÚ mismo son interpretables de alguna manera, lo son tan literalmente como las descripciones
de los compaþeros de equipo. Tal hallazgo, por supuesto, puede reflejar un grado sustancial de penetraciµn por parte de los sujetos.
El Õxito general con respecto a la validaciµn discriminante junto con los patrones factoriales paralelos del anÃlisis inicial de Fiske de
las tres matrices intramÕtodo pareciµ justificar el anÃlisis de la validez del patrµn factorial en este caso. Un procedimiento posible consiste en hacer un
solo anÃlisis de la matriz total de 66 x 66. Otros enfoques centrados en la factorizaciµn por separado de bloques de heteromÕtodo, matriz por matriz,
tambiÕn es sugerible. Pero tales mÕtodos no solo serÚan extremadamente tediosos, sino, ademÃs, dejarÚan indeterminada la comparaciµn precisa de la similitud del
patrµn factorial. La correlaciµn de las cargas factoriales sobre la poblaciµn de variables fue empleada con este propµsito por Fiske (1949), pero si bien
proporcionµ la identificaciµn de los factores recurrentes, ningºn Úndice ºnico total de la similitud del patrµn factorial fue generado. Puesto que nuestro
interÕs inmediato era confirmar un patrµn de interrelaciones y no describirlo, escogimos el mÕtodo corto y eficiente: probar la similitud de los conjuntos de
valores de heterorrasgo mediante los coeficientes de correlaciµn en los que cada anotaciµn representaba el tamaþo de los valores de los coeficientes de
heterorrasgo dados en dos matrices diferentes. Para la matriz completa, las correlaciones se basarÚan en el valor de N de las 22 x 21/2 µ 231 combinaciones
de heterorrasgo especÚficas. Las correlaciones se computaron entre las matrices monomÕtodo "compaþero de equipo" y "sÚ mismo", seleccionadas como de
independencia mÃxima. (Los valores que siguen fueron computados a partir de la matriz original de correlaciµn y son un poco mÃs altos que los que se habrÚan
obtenido de una matriz reflejada). La similitud entre las dos matrices monomÕtodo fue de .84, lo que corrobora la similitud del patrµn factorial entre
estas matrices que Fiske describe mÃs completamente en el anÃlisis factorial paralelo que hizo de ellas. Al realizar este anÃlisis, el bloque de heteromÕtodo
fue tratado como si estuviera dividido en dos por la diagonal de validez, de modo que los valores por encima y por debajo de la diagonal representaban la
validaciµn mÃs independiente del patrµn de correlaciµn de heterorrasgo. Se correlacionaron a .63, un valor que aunque es bajo, muestra un sensible grado de
confirmaciµn. Examinemos ahora la cuestiµn de que el patrµn con el que concuerdan los dos triÃngulos de heteromÕtodo-heterorrasgo sea el mismo que se
encontrµ comºn a los dos triÃngulos monomÕtodo. La matriz intra-compaþero de equipo se correlacionµ con los dos triÃngulos de heteromÕtodo a .71 y .71. La
matriz intra-sÚ mismo se correlacionµ a .57 y .63. Por tanto, en general, los resultados experimentales apoyan la validez del patrµn de relaciones interrasgo.
Relaciµn con la validez de constructo Aun cuando los criterios de validaciµn presentados se encuentren explÚcita o
implÚcitamente en los estudios de la validez de constructo (Cronbach y Meehl, 1955; APA, 1954), el artÚculo se interesa primordialmente en la adecuaciµn
de los tests como medidas de un constructo y no tanto en la adecuaciµn de un constructo como lo determina la confirmaciµn de asociaciones previstas
teµricamente que se hace por medio de las medidas de otros constructos. Antes de probar la relaciµn entre un rasgo concreto y otros rasgos, se debe
tener confianza en las medidas de ese rasgo. La confianza puede provenir de la validaciµn convergente y discriminante. En otras palabras, cualquier formulaciµn
conceptual de un rasgo suele incluir implÚcitamente la proposiciµn de que el rasgo es una tendencia a responder observable en mÃs de una condiciµn
experimental y el rasgo puede ser diferenciado significativamente de otros rasgos: La prueba de estas proposiciones debe ser anterior a la prueba de otras
proposiciones, de modo que evitemos la aceptaciµn de conclusiones errµneas. Por ejemplo, un marco conceptual puede postular una gran correlaciµn entre los
rasgos A y B y ninguna entre los rasgos A y C. Si el experimentador mide A y B por un mÕtodo (por ejemplo, un cuestionario) y C por otro mÕtodo (como la medida
de conducta abierta en una situaciµn de prueba), sus hallazgos pueden ser consecuentes con su hipµtesis ºnicamente como una funciµn de la varianza comºn
de mÕtodo a sus medidas de A y B, pero no a C. Se entiende que los requisitos de este artÚculo son adecuados
para los esfuerzos relativamente ateorÕticos tÚpicos de los tests y de la mediciµn como para intentos mÃs teµricos. Esta insistencia en los criterios
validacionales de nuestro nivel ateorÕtico de la construcciµn del test, no es en absoluto incompatible con un reconocimiento de las bondades de
incrementar el grado de consideraciones teµricas que determinan todos los aspectos de un test y de la situaciµn de prueba, como afirman Jessor y Hammond (Jessor
y Hammond, 1957). Relaciµn con el operacionalismo. (Underwood 1957), en su efectiva presentaciµn del punto de vista operacionalÀsta, seþala de modo
realista el tipo amorfo de teorÚa con la que trabaja la mayorÚa de los psicµlogos. Compara la concepciµn "literaria" de un psicµlogo con su definiciµn
operacional representada por sus tests u otros instrumentos de medida. Reconoce la importancia de la definiciµn literaria en la comunicaciµn y producciµn de la
ciencia y advierte que la definiciµn operacional "puede no medir en absoluto el proceso que se desea medir; puede medir incluso un objeto por completo
diferente". Sin embargo, no indica cµmo saber que se comete ese error. Los requisitos de nuestro artÚculo pueden verse como
extensivos de la clase de operacionalismo que Underwood ha expresado. Al elaborador de test no se le pide engendrar de su concepciµn literaria o
constructo privado una formulaciµn operacional, sino dos o aºn mÃs, cada una tan diferente en cuanto al vehÚculo de investigaciµn como sea posÚble. AdemÃs, se le
pide hacer explÚcita la distinciµn entre su nueva variable y otras variables, distinciones que intervienen en su definiciµn literaria. Es aconsejable que en
los primeros esfuerzos de validaciµn, antes de imprimirlos, aplique los mÕtodos y los rasgos diferentes. Su definiciµn literaria, su concepciµn, quedarà mejor
representada en la concordancia de sus medidas independientes del rasgo. La matriz multirrasgo-multimÕtodo es un primer paso de importancia
prÃctica para evitar "el peligro... de que el investigador piense que al partir de una concepciµn artÚstica o literaria... para llegar a la construcciµn de los
itemes de una escala que la mida, ha validado su concepciµn artÚstica" (Underwood, 1957). En contraste con el operacionalismo individual que domina
en la psicologÚa, abogan por un operacionalismo mºltiple, un operacionalismo convergente (Garner, 1954; Garner, Hake y Eriksen, 1956), una triangulaciµn
metodolµgica (Campbell, 1953, 1956), una delineaciµn operacional (Campbell, 1954) y una validaciµn convergente. La presentaciµn de Underwood implica
desplazarse del concepto a la operaciµn, cosa frecuente y caracterÚstica de la ciencia. Se puede indicar lo mismo, sin embargo, al analizar una transiciµn de
la operaciµn al constructo. Para cualquier cuerpo de datos tomados de una sola operaciµn hay una subÚnfinidad de interpretaciones posibles, es decir, una
subinfinidad de conceptos o combinaciones de conceptos que la representan. Una sola operaciµn es equÚvoca como representativa de conceptos. De un modo anÃlogo,
cuando examinamos el cuarto distorsionado de Ames desde un punto fijo y a travÕs de un solo ojo, los datos del patrµn retinal son equÚvocos en cuanto a la
subinfinidad de hexaedrones que puede engendrar el mismo patrµn. La adiciµn de un segundo punto de vista, a travÕs del paralaje binocular, reduce mucho su
ambig■edad y limita considerablemente las construcciones de ambos conjuntos de datos. En el estudio de Garner (1954), las medidas de fraccionamiento de un solo
mÕtodo fueron equÚvocas, es decir, tal vez eran funciµn de la distancia fraccionada del estÚmulo de comparaciµn del proceso de juicio. Un
operacionalismo convergente mºltiple redujo la ambig■edad al seþalar que la ºltima conceptualizaciµn era la apropiada, y al revelar la preponderancia de una
varianza de los mÕtodos. Lo mismo sucede en los estudios de aprendizaje: al identificar los constructos con los datos de respuesta de animales en un arreglo
operacional concreto hay ambig■edad, que se reduce operacionalmente al introducir pruebas de transposiciµn, a saber, (as diferentes operaciones
proyectadas para hacer comparaciones entre las conceptualizaciones rivales (Campbell, 1954). El operacionalismo convergente de Garner y nuestra
insistencia en mÃs de un mÕtodo para medir cada concepto se separa de la primera posiciµn de Bridgman: "si tenemos mÃs de un conjunto de operaciones, hay mÃs de
un concepto y estrictamente hay un nombre diferente para cada conjunto de operaciones" (Bridgman, 1927). En la etapa presente de la psicologÚa,
el problema crucial consiste en la demostraciµn de convergencia, aunque no de completa congruencia, entre dos conjuntos distintos de operaciones. Con solo un
mÕtodo, no hay manera de distinguir la varianza de rasgo de la indeseada varianza de mÕtodo. Cuando la mediciµn y la conceptualizaciµn psicolµgicas
lleguen a estar mejor desarrolladas, puede ser muy adecuada la diferencia conceptual entre la unidad A1 de rasgo-mÕtodo y la unidad A2 de rasgo-mÕtodo,
donde el rasgo A se mide por diferentes mÕtodos. MÃs probablemente, la varianza de mÕtodo se concretarà teµricamente en tÕrminos de un conjunto de constructos.
Entonces se sabrà que los procedimientos de mediciµn suelen incluir varios constructos teµricos en
aplicaciµn conjunta. Para que las medidas obtenidas estimen valores para un solo constructo bajo esta condiciµn se requiere tambiÕn la comparaciµn de medidas
complejas que varÚan en su composiciµn de rasgo, de manera algo semejante a una matriz multirrasgo. El mÕtodo de uniµn de Mill de las semejanzas y las
diferencias abrevia demasiado la efectiva clarificaciµn experimental de los conceptos. La evaluaciµn de una motriz multirrasgo-multimÕtodo. La
evaluaciµn de la matriz de correlaciµn que se forma al intercorrelacionar varias unidades de rasgo-mÕtodo, debe tener en consideraciµn los factores que, segºn se
sabe, afectan la magnitud de las correlaciones. Un valor de la diagonal de validez debe ser evaluado a la luz de las confiabilidades de las dos medidas
involucradas; por ejemplo, una baja confiabilidad para el test A2 exagera la varianza de mÕtodo manifiesta en el test A1. AdemÃs, el enfoque global supone
que el muestreo de los individuos es adecuado: la reducciµn de la muestra con respecto a uno o mÃs rasgos harÃn disminuir los coeficientes de confiabilidad y
las intercorrelaciones que contengan estos rasgos. Aunque las restricciones de rango sobre todos los rasgos produce serias dificultades en la interpretaciµn de
la matriz multirrasgo-multimÕtodo y deben evitarse siempre que se pueda, la presencia de diferentes grados de restricciµn en distintos rasgos es el peligro
mÃs serio de la interpretaciµn significativa. Se pueden desarrollar varios tratamientos estadÚsticos para
las matrices multirrasgomultimÕtodo. Se han considerado pruebas elementales de la elevaciµn de un valor en la diagonal de validez por encima de los valores de
comparaciµn en su renglµn y columna. Se ha propuesto el uso de correlaciones entre las columnas de variables que miden el mismo rasgo, el anÃlisis de
varianza y el anÃlisis factorial. El desarrollo de tales mÕtodos estadÚsticos està mÃs allà del propµsito de esta exposiciµn. Los psicµlogos no deben interesarse en evaluar los tests como
si fueran fijos y definitivos, sino mÃs bien en desarrollar mejores tests. Un examen cuidadoso de una matriz multirrasgo-multimÕtodo indicarÃ
al experimentador los pasos que debe dar; le indicarà quÕ mÕtodos debe descartar o reemplazar, los conceptos que necesitan una delineaciµn mÃs definida y los que
son mÃs pobremente medidos a causa de la excesiva o desconcertante varianza de mÕtodo. Los juicios de validez basados en tal matriz deben tener en cuenta la
etapa de desarrollo de los constructos, las relaciones postuladas entre ellos, el nivel de afinamiento tÕcnico de los mÕtodos, la relativa independencia de
estos y cualquier caracterÚstica pertinente de la muestra de sujetos. Estamos proponiendo que el proceso de validaciµn sea considerado un aspecto de un
programa de mejoramiento de los procedimientos de mediciµn, y que los "coeficientes de validez" obtenidos en cualquier etapa del proceso sean
interpretados como ganancia sobre las etapas precedentes y seþales de hacia dµnde dirigir los esfuerzos ulteriores. El diseþo de una matriz multirrasgo-multimÕtodo. Los
diferentes mÕtodos y rasgos incluidos en una matriz de validaciµn deben seleccionarse con cuidado. Los diversos mÕtodos que miden cada rasgo deben ser
adecuados a cµmo se ha conceptualizado el rasgo. Aunque esta perspectiva reducirà el rango de mÕtodos adecuados, rara vez restringirà la mediciµn a un
procedimiento operacional. Siempre que se pueda, los diversos mÕtodos en una matriz
deben ser completamente independientes entre sÚ; no debe haber ninguna razµn previa para creer que comparten varianza de mÕtodo. Este requisito es necesario
para que los valores en los triÃngulos de hsteromÕtodo-heterorrasgo se acerquen a cero. Si la naturaleza de los rasgos excluye la independencia de mÕtodos,
deben hacerse esfuerzos para obtener diversidad en cuanto a las fuentes de datos y a los procesos de clasificaciµn. De este modo, las clases de estÚmulos o las
situaciones de fondo, es decir, los contextos experimentales, deben ser diferentes. AdemÃs, las personas que proporcionen las observaciones deberÃn
tener diferentes papeles o los procedimientos de calificaciµn deberÃn ser variados. Los planes para una matriz de validaciµn deben tener en
cuenta la diferencia entre las interpretaciones con respecto a la convergencia y a la discriminaciµn. Basta con demostrar convergencia entre dos mÕtodos
claramente distintos que muestran poco traslapamiento en los triÃngulos de heterorrasgo-heteromÕtodo. Mientras el acuerdo entre varios mÕtodos sea
deseable, la convergencia de dos es un requisito mÚnimo satisfactorio. La validaciµn discriminativa no se logra con facilidad. AsÚ como es imposible
comprobar la hipµtesis de nulidad, o que un objeto no existe, no se puede establecer que un rasgo, como es medido, se diferencia de todos los demÃs.
Solamente se puede mostrar que la medida del rasgo A tiene poco traslapamiento con las medidas de B y C, y ninguna generalizaciµn segura puede hacerse mÃs allÃ
de B y C. Por ejemplo, el equilibrio social probablemente pudiera discriminarse fÃcilmente de los intereses estÕticos, pero tambiÕn debe ser diferenciado de
liderazgo. En cuanto a los rasgos relacionados y que se espera se correlacionen entre sÚ, las correlaciones de monomÕtodo serÃn sustanciales y las
de heteromÕtodo entre rasgos tambiÕn serÃn positivas. Si se quiere facilidad e interpretaciµn, es mejor incluir en la matriz por lo menos dos rasgos y
preferiblemente dos conjuntos de rasgos que sean postulados independientes entre sÚ. Muchas matrices multirrasgo-multimÕtodo no mostrarÃn validaciµn convergente;
puede no haber ninguna relaciµn entre dos mÕtodos de mediciµn de un rasgo. En esta situaciµn comºn, el experimentador debe examinar las pruebas a favor de
varias alternativas: a) ningºn mÕtodo es adecuado para medir el rasgo; b) uno de
los dos mÕtodos no mide realmente el rasgo. (Cuando las pruebas indican que un mÕtodo no mide el rasgo postulado, puede indicar que mide otro rasgo. Las altas
correlaciones en los triÃngulos de heterorrasgo-heteromÕtodo pueden ofrecer sugerencias a tales posibilidades).
c), el rasgo no es una unidad funcional, es decir, las tendencias de respuesta que intervienen son propias de los
atributos y no del rasgo de cada test. El fracaso al demostrar la convergencia puede llevar a desarrollos conceptuales en lugar de abandonar el test.
RESUMEN
Se propone un proceso de validaciµn que utiliza una matriz de intercorrelaciones entre los tests que representan por lo menos dos rasgos, cada
uno medido por un mÚnimo de dos mÕtodos. Las medidas del mismo rasgo deben correlacionarse mÃs entre sÚ que con medidas de diferentes rasgos que involucren
distintos mÕtodos. Idealmente, estos valores de validez tambiÕn deben ser mÃs altos que las correlaciones entre los diferentes rasgos medidos por el mismo mÕtodo.
Ejemplos hallados en la bibliografÚa muestran que estas condiciones deseables,
como grupo, rara vez son satisfechas. Los factores de mÕtodo o de aparato contribuyen grandemente a las medidas psicolµgicas.
Las nociones de convergencia entre las medidas independientes del mismo rasgo y
la discriminaciµn entre las medidas de diferentes rasgos son comparadas con las formulaciones publicadas anteriormente, como la validez de constructo y el
operacionalismo convergente. Los problemas de la aplicaciµn de este proceso de validaciµn ya se consideraron.
BIBLIOGRAFIA
Las Validaciones Convergente y Discriminante Mediante la Matriz Multirrasgo-MultimÕtodo
La experiencia acumulada en la medida de las diferencias individuales durante
los ºltimos 50 aþos, seþala que los tests han sido aceptados o descartados en cuanto a su validez gracias a muchas clases de experiencias de investigaciµn.
Los criterios que sugiere este trabajo se encuentran en dichas evaluaciones acumulativas, asÚ como tambiÕn en los recientes estudios acerca de la validez.
Estos criterios se aclaran y aumentan su eficacia cuando se consideran conjuntamente en el contexto de una matriz multirrasgo-multimÕtodo. Los aspectos
mÃs estudiados del proceso de validaciµn son los siguientes:
1. La validaciµn es caracterÚsticamente convergente, es decir, una corroboraciµn
por procedimientos de mediciµn independientes. La independencia de los mÕtodos es el denominador comºn de los principales tipos de validez (con la excepciµn de
la validez de contenido) en la medida en que se distinguen de la confiabilidad.
2. Ya sea para justificar las mediciones de nuevos rasgos, para la validaciµn de
la interpretaciµn de tests, o para el establecimiento de la validez de construcciµn, se requiere la validaciµn discriminante, asÚ como tambiÕn la
validaciµn convergente. Los tests pueden ser invalidados por tener correlaciones demasiado altas con otros, cuando la intenciµn ha sido que difieran.
3. Cada test o cada tarea empleados con propµsitos de mediciµn es una unidad rasgo-mÕtodo, una uniµn
del contenido de un rasgo particular con procedimientos de medida que no son propios de ese contenido. La varianza sistemÃtica entre las puntuaciones de un
test puede deberse a la respuesta frente a las cualidades de la mediciµn, asÚ como de la respuesta al contenido del rasgo.
4. Para examinar la validez discriminante y para estimar las contribuciones relativas de la varianza del mÕtodo y del rasgo, debe emplearse mµs de un rasgo
y mÃs de un mÕtodo, en el proceso de validaciµn. En muchos casos serà conveniente realizarlo a travÕs de una matriz multirrasgo-multimÕtodo , que
presenta todas las intercorrelaciones resultantes cuando cada uno de los diferentes rasgos se mide por cada uno de los distintos mÕtodos.
Para ilustrar el proceso de validaciµn sugerido, se presenta un ejemplo sintÕtico en la tabla 1. En este ejemplo intervienen tres rasgos diferentes,
cada uno medido por tres mÕtodos, que generan nueve variables distintas. Es conveniente nombrar las diferentes regiones de la matriz, como se hace en la
tabla 1. Las confiabilidades se mencionan en tÕrminos de tres diagonales de confiabilidad, una para cada mÕtodo. Las confiabilidades tambiÕn podrÃn
designarse como valores de monorrasgo-monomÕtodo. El triÃngulo adyacente a cada diagonal de confiabilidad se llama triÃngulo heterorrasgo-monomÕtodo. La
diagonal de confiabilidad y el triÃngulo adyacente heterorrasgo-mono mÕtodo forman un bloque monomÕtodo. Un bloque heteromÕtodo està formado por una
diagonal de validez (que tambiÕn puede designarse como valores de monorrasgo-heteromÕtodo) y los dos triÃngulos heterorrasgo-heteromÕtodo) que estÃn a cada lado de ella.
Nµtese que los dos triÃngulos heterorrasgo-heteromÕtodo no son idÕnticos.
En tÕrminos de este diagrama, la cuestiµn de la validez radica en cuatro aspectos. En primer lugar, las anotaciones de la, diagonal de validez deben ser
significativamente diferentes de cero y suficientemente grandes para estimular un examen mÃs amplio de la validez este requisito es una seþal de validez
convergente. En segundo lugar, un valor de la diagonal de validez debe ser mayor que los de su columna y renglµn en los triÃngulos heterorrasgo-heteromÕtodo. Es
dÕcir, el valor de la validez de una variable debe ser mayor que las correlaciones obtenidas entre esa variable y cualquier otra que no tenga en
comºn con ella el mismo rasgo ni el mismo mÕtodo. Este requisito puede parecer demasiado insignificante y obvio para establecerlo; sin embargo, un estudio de
las publicaciones acerca del problema muestra que frecuentemente no queda satisfecho, aun cuando los coeficientes de validez son de magnitud considerable.
En la tabla 1 todos los valores de validez satisfacen este requisito. Un tercer desiderÃtum de sentido comºn es que una variable se correlacione en mayor grado
con esfuerzo independiente de medir el mismo rasgo que con mediciones de diferentes rasgos que emplean el mismo mÕtodo. Ante una variable determinada, en
consecuencia, es necesario comparar los valores de sus diagonales de validez con los valores de sus triÃngulos heterorrasgo-monomÕtodo. Ante las variables A1 B1
y C1, este requisito se satisface en cierta medida. En las otras variables, A2, A3, etcÕtera, no sucede de la misma manera y este es, posiblemente, el caso
tÚpico de la investigaciµn de las diferencias individuales, problema que veremos en seguida. Un cuarto desiderÃtum es que se exhiba el mismo patrµn de
interrelaciones de rasgo en todos los triÃngulos heterorrasgo de los bloques mµnomÕtodo y heteromÕtodo. Los datos ficticios de la tabla la satisfacen este
requisito en grado notable, a pesar de los diferentes niveles generales de correlaciµn que intervienen en los varios triÃngulos heterorrasgo. Los tres
ºltimos criterios evidencian la validez discriminante. Antes de examinar las matrices multirrasgo-multimÕtodo existentes en la
bibliografÚa, veamos una explicaciµn y justificaciµn de este complejo de requisitos.
Convergencia de mÕtodos independientes: distinciµn entre confiabilidad y validez Los
conceptos de confiabilidad y validez requieren que la concordancia entre las medidas sea demostrada. Un denominador comºn de la mayorÚa de los conceptos de
validez en contraste con el de confiabilidad es que el de la uniµn representa la convergencia de actitudes independientes: Se seþala el concepto de independencia
con frases como "variable externa", "ejecuciµn de criterio", "criterio conductual" (American Psychological Association, 1954) si se usan en conexiµn
con la validez concurrente y la predictiva. Con respecto a la validez de constructo se ha descrito de esta manera: "Numerosas predicciones acertadas que
tratan de "criterios" fenµtÚpicamente diversos dan mayor peso a la pretensiµn de validez de constructo que las. ... predicciones que incluyen conductas muy
similares" (Cronbach y Meehl, 1955). La significaciµn de la independencia sÕ repite en la mayorÚa de los estudios de la comprobaciµn. Por ejemplo, Ayer, al
analizar la creencia del historiador en un suceso del pasado, dice: "Si estas fuentes son numerosas e independientes y si concuerdan entre sÚ, se tendrÃ
bastante confianza en que su narraciµn es correcta". (Ayer, 1954 ). Al examinar la manera en que los conceptos cientÚficos abstractos se ligan con las
operaciones, Feigl habla de una "fijaciµn" por "triangulaciµn en el espacio lµgico" (Feigl 1958).
La independencia es, por supuesto, cuestiµn de grado, y en este sentido la confiabilidad y la validez pueden verse como las regiones de un continuo (Thurstone,
1937). La confiabilidad es el grado de uniµn entre dos esfuerzos para medir el mismo rasgo a travÕs de la mÃxima similitud de los mÕtodos. La validez estÃ
representada por el grado de uniµn entre dos intentos de medir el mismo rasgo a travÕs de la mÃxima diferencia de los mÕtodos. Una confiabilidad de divisiµn en
mitades se asemeja mÃs a un coeficiente de validez que una confiabilidad inmediata de test-retest, porque los Útemes o reactivos no son completamente
idÕnticos. Una correlaciµn entre subtests no similares es probablemente una medida de confiabilidad, pero se acerca aºn mÃs a la regiµn llamada validez.
Se puede llevar a cabo una evaluaciµn de la validez aunque los dos mÕtodos no sean enteramente independientes. En la tabla 1, por ejemplo, es posible que los
mÕtodos 1 y 2 no sean enteramente independientes. Si los rasgos subyacentes A y B lo son por completo, entonces una correlaciµn mÚnima de .10 en los triÃngulos
heterorrasgo-heteromÕtodo reflejarà la covarianza de mÕtodo. ¢QuÕ pasarà cuando el traslapamiento de varianza de mÕtodo sea mÃs alto? Todas las correlaciones en
el bloque de heteromÕtodo se elevarÃn, incluyendo a la diagonal de validez. El bloque de heteromÕtodos que incluye los mÕtodos 2 y 3 en la tabla 1 es un
ejemplo de este caso. El grado de elevaciµn de la diagonal de validez por encima de los triÃngulos heterorrasgo-heteromÕtodo no deja de ser semejante y la
validez relativa aºn puede evaluarse. AsÚ pues, la interpretaciµn absoluta de la diagonal de validez requiere una afortunada coincidencia de la independencia de
rasgos y la independencia de mÕtodos, que representan los valores de cero en los triÃngulos heterorrasgo-heteromÕtodo. Pero los valores de cero tambiÕn pueden
ocurrir a travÕs de una combinaciµn de correlaciµn negativa entre los rasgos y de correlaciµn positiva entre los mÕtodos, o viceversa. En la prÃctica, tal vez
no se puede esperar sino seþales de validez relativa, es decir, de varianza comºn concreta de un rasgo mÃs allà de la varianza comºn de mÕtodo.
La validaciµn discriminante. Mientras la base general para el juicio de invalidez suele consistir en las bajas correlaciones
de la diagonal de validez (por ejemplo, los tests de disposiciµn-temperamento de Downey, Symonds, 1931), los tests tambiÕn se invalidan debido a correlaciones
muy altas con otros tests destinados a medir objetos diferentes. El problema clÃsico de los tests de inteligencia social viene al caso. Dicha invalidez
ocurre cuando los valores de los triÃngulos heterorrasgo-heteromÕtodo son tan altos como los de la diagonal de validez o tambiÕn cuando dentro de un bloque
monomÕtodo, los valores de heterorrasgo son tan altos como las confiabilidades. Loevinger, Gleser y Du-Bois (1953) han subrayado este requisito para el
desarrollo de subtests de mÃxima discriminaciµn. Cuando se ha supuesto una dimensiµn de la personalidad al proponer una
construcciµn., el que propone invariablemente distingue entre la nueva dimensiµn y otras construcciones que se usan. No se puede definir sin implicar
distinciones, y la verificaciµn de las distinciones es una parte importante del proceso de validaciµn. En las discusiones acerca de la validez de construcciµn,
se han expresado tÕrminos como "desde este punto de vista, una baja correlaciµn con la capacidad atlÕtica puede ser justamente tan importante y alentadora como
una correlaciµn alta con la comprensiµn de lectura" (APA, 1954). El test como unidad rasgo-mÕtodo.
En cualquier instrumento de mediciµn psicolµgica, hay formas o estÚmulos que se introducen
con intenciµn de representar el rasgo que se intenta medir. Hay otras formas caracterÚsticas del mÕtodo que se emplea, formas que tambiÕn podrÚan estar
presentes en los esfuerzos para medir rasgos completamente diferentes. El test, la escala de estimaciµn u otro instrumento, casi inevitablemente producen
varianza sistemÃtica en las respuestas debido a ambos grupos de factores. En el mismo grado en que las pequeþas varianzas del mÕtodo contribuyen a las
puntuaciones obter■das, Õstas tambiÕn son invÃlidas. Esta fuente de invalidez se advirtiµ por primera vez en los "efectos de halo" de
las estimaciones (Thorndike, 1920). Los estudios de las diferencias individuales entre animales de laboratorio revelaron los "factores de aparato", generalmente
mÃs dominantes que los factores de procesos psicolµgicos (Tryon, 1942). En los tests de papel y lÃpiz, la varianza de los mÕtodos se ha seþalado en tÕrminos
como "factores de la forma del test", (Vernon, 1957, 1958) y "disposiciones de respuesta" (Cronbach, 1946, 1950; Lorge, I 1937). Cronbach se ha expresado en
forma muy clara: "La suposiciµn que se suele hacer es... que el test mide un objeto que se determina por el contenido de los Útemes. Sin embargo, la
puntuaciµn final. . , es un compuesto de los efectos resultantes del contenido del Útem y de los efectos resultantes de la forma del Útem usado". (Cronbach,
1946). "Las disposiciones de respuesta siempre disminuyen la validez lµgica de un test... las de respuesta interfieren con las inferencias de los datos del
test". Si bien, E.L. Thorndike (1920) se inclinµ a sostener la presencia de los efectos de halo al
comparar las correlaciones altas obtenidas con nociones de sentido comºn en relaciµn a lo que deberÚan ser (por ejemplo, no era razonable que la
inteligencia y la calidad de la voz de un maestro se correlacionaran en un .63) y aun cuando gran parte de la evidencia de la varianza de la disposiciµn de
respuesta es de la misma clase, la demostraciµn clara de la presencia de la varianza de mÕtodo requiere varios rasgos y varios mÕtodos. TambiÕn altas
correlaciones entre tests pueden explicarse como debidas a la semejanza bÃsica de rasgos o a la varianza compartida del mÕtodo. En la matriz multirrasgo-multimÕtodo,
la presencia de la varianza de mÕtodo està indicada por la diferencia en el nivel de correlaciµn entre los valores paralelos del bloque monomÕtodo y de los
bloques heteromÕtodo, si se supone que hay semejanza de confiabilidades entre todos los tests. AsÚ, la contribuciµn de la varianza de mÕtodo en el test A1 de
la tabla 1 se indica por la elevaciµn de rA1 B1 por encima de rA1 B2, la diferencia entre .51 y .22, etcÕtera. La
distinciµn entre rasgo y mÕtodo interesa, por supuesto, a los propµsitos de quien elabora el test. Lo que puede ser una indeseable respuesta de disposiciµn
para un examinador, puede ser un rasgo para otro que desee medir la aquiescencia, el gusto por adoptar una
posiciµn extrema o la tendencia a adjudicarse atributos socialmente deseables (Cronbach, 1946,1950; Edwards, 1957; Lorge, 1937).
BibliografÚa existente acerca de matrices multirrasgo-multimÕtodo
Las matrices multirrasgo-multimÕtodo son raras en los estudios existentes sobre tests y mediciµn. MÃs frecuentes son dos tipos de fragmentos: dos mÕtodos y un
rasgo (valores individuales aislados en la diagonal de validez quizà acompaþados por una o dos confiabilidades) y triÃngulos heterorrasgo-monomÕtodo. Cualquier
fragmento podrà encubrir la inadecuaciµn de nuestros actuales esfuerzos de mediciµn, particularmente cuando no llaman la atenciµn hacia la fuerza
preponderante de la varianza de mÕtodos. Las pruebas de validez de un test presentadas aquÚ son quizà mÃs pobres de lo que esperarÚan la mayorÚa de los
psicµlogos. Una de las primeras matrices de esta clase la proporcionaron Kelley y Krey en
1934. Las opiniones realizadas por sus compaþeros estudiantes proporcionaron, ademÃs de un mÕtodo, puntuaciones en
un test de asociaciµn de palabras. La tabla 2 presenta los datos de los cuatro rasgos mÃs vÃlidos. El cuadro es uno de los factores mÃs fuertes del mÕtodo,
particularmente entre las estimaciones de los compaþeros, y casi de una invalidez total. Para una de las ocho medidas, el impulso escolar, el valor de
la diagonal de validez (.16) es mÃs alto que todos los valores de heterorrasgo-heteromÕtodo. La ausencia de la validez discriminante se indica mÃs
ampliamente por la tendencia de los valores dentro de los triÃngulos monomÕtodo
a aproximarse a las confiabilidades. Uno de los primeros ejemplos de estudios de animales se encuentra en el examen de las pulsiones de Anderson (1937). La tabla 3 presenta una muestra de sus
datos. Repetidamente, las correlaciones mÃs altas se encuentran entre diferentes construcciones con el mismo mÕtodo, lo que seþala el predominio de los factores
de aparato o de mÕtodo caracterÚsticos del campo de las diferencias individuales. La diagonal de validez del hambre es mÃs alta que los valores
heteroconstructo-heteromÕtodo. El valor de la diagonal del sexo no està en itÃlicas como coeficiente de validez, pues la medida de la caja de obstrucciµn
fue anterior a la oportunidad de sexo y la de la rueda de actualidad fue posterior a la oportunidad. Nµtese que el alto nivel general de los valores
heterorrasgo-heteromÕtodo podrÚa deberse a la correlaciµn de varianza de mÕtodos entre los dos mÕtodos o a la correlaciµn de varianza de rasgo. Sobre una
base apriorÚstica, sin embargo, los mÕtodos parecen tan independientes como se deseen. El predominio de un factor de aparato en la rueda de actividad evidencia
el hecho de que la correlaciµn entre hambre y sed (.87) es de la misma magnitud
que sus confiabilidades test-retest (.83 y .92, respectivamente). El estudio de R.L. Thorndike (1936) acerca de la validez del Test de Inteligencia Social George Washington es el ejemplo clÃsico de invalidaciµn por
alta correlaciµn entre los rasgos. ContenÚa el cµmputo de todas las interrelaciones entre las cinco subescalas del test de inteligencia social y las
cinco subescalas del Test de Agilidad Mental George Washington. El modelo exigirÚa que cada uno de los rasgos, inteligencia social y
agilidad mental, fueran medidos por lo menos con dos mÕtodos. Si bien en el estudio no se intentµ una simetrÚa completa puede interpretarse asÚ sin
demasiada distorsiµn. Para ambos rasgos existÚan subtests que empleaban la adquisiciµn de conocimiento durante el periodo de
prueba (es decir, el aprendizaje o memoria), tests que involucraban comprensiµn
de pasajes en prosa y tests que exigÚan la actividad de dar definiciones. Si los tres subtests del Test de Inteligencia Social se
consideran como tres mÕtodos de mediciµn de la inteligencia social, sus intercorrelaciones (.30, .23 y .31) representan valores de validez que no son
solamente mÃs bajos que sus correspondientes valores de monomÕtodo, sino tambiÕn mÃs bajos que las correlaciones heterorrasgo-heteromÕtodo, con lo que
proporcionan un cuadro que falla totalmente al establecer la inteligencia social como una dimensiµn distinta. Las diagonales de validez de agilidad
mental (.38, .58 y .48) igualan o exceden los valores monomÕtodo en dos de tres casos y exceden todos los valores de control heterorrasgo-heteromÕtodo. Estos
resultados ilustran las conclusiones generales de Thorndike en su anÃlisis
factorial de la matriz total, 10 X 10. Los datos de la tabla 4 pueden usarse para validar formas concretas del funcionamiento cognoscitivo, como las que miden los diferentes "mÕtodos" que
representa el contenido de un test de inteligencia general por una parte y el de contenido social por la otra. La tabla 5 muestra un nuevo arreglo de los 15
valores con este propµsito. Los valores de monomÕtodo y las diagonales de validez intercambian sus lugares mientras los coeficientes de control de
heterorrasgo-heteromÕtodo son los mismos en ambas tablas. Juzgados en contraste con estos ºltimos valores, la comprensiµn (.48) y el vocabulario (.47), pera no
la memoria (.31), exhiben cierta validez especÚfica. Esta trasmutabilidad de la matriz de validaciµn apoya las comparaciones dentro del bloque heteromÕtodo como
las mÃs pertinentes, en general, para los datos de validaciµn e ilustra la intercambiabilidad potencial de los componentes de rasgo y mÕtodo.
Algunas de las correlaciones en el talentoso estudio de Chi (1937) de los efectos de halo de las estimaciones se
adecuan a la matriz multirrasgo-multimÕtodo,
en la que cada evaluador puede considerarse como representante de un mÕtodo diferente. Aun cuando el informe publicado no los hace asequibles en detalle
debido a que emplea valores promediados, de la comparaciµn de sus tablas IV y VIII se infiere que las estimaciones del mismo rasgo hechas por evaluadores
diferentes fracasaron al no correlacionar mÃs que las estimaciones de diferentes rasgos hechas por el mismo evaluador. La validez se exhibe en la medida en que
las correlaciones de la diagonal de validez del bloque heteromÕtodo son mÃs altas que los valores promedio heterorrasgo-heteromÕtodo.
Campbell (1953, 1956) proporciona una matriz multirrasgo-multimÕtodo manifiestamente insatisfactoria con relaciµn a la estimaciµn de la conducta como
lÚderes de oficiales, hecha por sÚ mismos y por sus subordinados. Solamente 1 de las 11 variables (la conducta de reconocimiento) satisfizo el requerimiento de
proporcionar de la diagonal de validez, un valor mÃs alto que cualquiera de los valores heterorrasgo-heteromÕtodo, de .29. Ninguna de las variables tuvo valores
de validez mÃs altos que los de heterorrasgo-heteromÕtodo.
Un estudio de las actitudes ante la
autoridad y la no autoridad realizado por Burwen y Campbell (1957) contiene una compleja matriz multirrasgo-multimÕtodo de la cual se muestra un extracto
simÕtrico en la tabla 6. Hubo una fuerte varianza de mÕtodo para la mayorÚa de los procedimientos del estudio. Se encontrµ validez primordialmente en el nivel
de los valores de la diagonal de validez mayores que los de heterorrasgo -heteromÕtodo. Como se ve en la tabla 6, la actitud hacia el padre mostrµ esta clase de
validez, del mismo modo que la actitud hacia los compaþeros, pero en un grado menor. La actitud hacia el patrµn no mostrµ validez. No hubo evidencia de una
actitud generalizada hacia la autoridad que incluyera padre y patrµn, aunque valores como la correlaciµn de .64 entre padre y patrµn, medidos por entrevista,
parecerÚa confirmar la hipµtesis de que se encuentran aislados. Borgatta (1954) ha proporcionado un estudio complejo de multimÕtodo, del cual la tabla 7 es un extracto que ejemplifica la evaluaciµn de dos rasgos por cuatro
mÕtodos diferentes. Para todas las medidas excepto una, la correlaciµn mÃs alta es la de aparato, es decir, con el otro rasgo medido por el mismo mÕtodo en
lugar del mismo rasgo medido por diferente mÕtodo. Ninguno de los rasgos encuentra validaciµn consistente para el requisito de que las diagonales de
validez excedan los valores control heterorrasgo-heteromÕtodo. Como requisito mÚnimo, podrÚa pedirse que la suma de los dos valores de la diagonal de validez
exceda la suma de los dos valores control, para proporcionar una comparaciµn en la que las diferencias de confiabilidad o comunalidad sean burdamente "parcialÀzadas". Esta condiciµn se logra al nivel puramente fortuito de tres veces en las
seis tÕtradas. Esta matriz proporciona una clase interesante de independencia metodolµgica. Las dos medidas "sociomÕtricas de otros", si bien representan los
juicios del mismo grupo de los compaþeros participantes, proceden de distintas tareas; la popularidad se basa en la expresiµn de cada participante de sus
preferencias de amistad, mientras que la expansividad se basa en lo que cada participante adivinµ con respecto a las elecciones de otros participantes, de
las que se ha calculado la reputaciµn de cada participante por la porciµn de simpatÚa de otras personas, es decir, la cualidad "expansiva". junto a esta
considerable independencia, la certidumbre de un factor de mÕtodo es relativamente baja en comparaciµn con los procedimientos de observaciµn. De igual modo, las dos
medidas "sociomÕtricas por sÚ mismo" representan tareas completamente distintas; la popularidad procede de las elecciones que estima le adjudicarÃn los otros; la
expansividad, del nºmero de expresiones de atracciµn hacia otros que hace en la tarea sociomÕtrica. En contraste, las medidas de popularidad y expansividad
segºn las observaciones de interacciµn de grupo y el juego de papeles no solamente implican los mismos observadores especÚficos, sino tambiÕn que los
observadores estimaron el par de variables como parte de la misma tarea de estimaciµn en cada situaciµn. El grado aparente de varianza de mÕtodo dentro de
cada una de las dos situaciones de observaciµn y la varianza de mÕtodo aparentemente compartida entre ellas es, en consecuencia, alta.
En otro artÚculo de Borgatta (1955), doce variables del proceso de interacciµn se midieron por medio de la observaciµn cuantitativa en dos condiciones y un
test proyectivo. En este test, los estÚmulos fueron cuadros de grupos, para los cuales los sujetos generaron una serie de intercambios verbales que fueron
calificados despuÕs en las categorÚas de anÃlisis del proceso de interacciµn. Como ejemplo, la tabla 8 presenta los cinco rasgos que tuvieron la mÃs alta
media de comunidades en el anÃlisis factorial total. Entre los dos mÕtodos observacionales mÃs semejantes, la validaciµn es excelente; las diagonales de
validez son en general mÃs altas que los valores de heterorrasgo de los bloques heteromÕtodo y monomÕtodo, casi intachablemente asÚ para los incisos "da
opiniµn" y "da orientaciµn". El patrµn de correlaciµn entre los rasgos tambiÕn es generalmente confirmado. De mayor
interÕs, debido a su mayor independencia de mÕtodos, son los bloques que contienen el test proyectivo. AquÚ el cuadro de validez es mucho mÃs pobre. El
inciso "da orientaciµn" sale mejor, pues sus valores de validez de test proyectivo .35 y .33 son superados solamente por tres valores de monomÕtodo y no
lo son por ninguno de los valores de heterorrasgo-heteromÕtodo dentro de los bloques proyectivos.
El especialista en tests proyectivos puede objetar las expectativas implÚcitas de una correspondencia de uno a uno
entre la acciµn proyectada y la acciµn abierta. Las expectativas no deben atribuirse a Borgatta y no son necesarias para el mÕtodo propuesto. Para el
modelo simÕtrico simple se ha supuesto que las medidas son denominadas en correspondencia con las correlaciones esperadas, es decir, en
relaciµn con los rasgos que los tests afirman. Nµtese que en la tabla 8, "da opiniµn" es el mejor pronµstico del test proyectivo de "manifiesta desacuerdo"
en conducta libre y en desempeþo de errores. Si fuera asequible un fundamento teµrico apropiado, los valores podrÚan considerarse de validez.
Mayo (1956) ha hecho un anÃlisis de las puntuaciones de test y las estimaciones de esfuerzo e inteligencia, para juzgar la contribuciµn del halo (una clase de
varianza de mÕtodo) a las estimaciones. Como lo muestra la tabla 9, el cuadro de validez es ambiguo. El factor de mÕtodo o efecto de halo en las estimaciones es
considerable aunque la correlaciµn entre las dos estimaciones (.66) està muy por debajo de sus confiabilidades (.84 y .85). Las medidas objetivas no comparten un
traslapamiento apreciable de aparato porque fueron operaciones independientes. A pesar del argumento de Mayo acerca de que las estimaciones tienen alguna
varianza de rasgo vÃlida, el valor heterorrasgo-heteromÕtodo de .46 desprecia seriamente los notorios valores de validez de .46 y .40.
Cronbach (1949) y Vernon (1957, 1958) han estudiado la matriz multirrasgo-multimÕtodo de la tabla 10, basada en datos originalmente
presentados por H.S. Conrad. Con una tÕcnica semejante, Vernon estima que el 61% de la varianza sistemÃtica se debe a un factor general, a saber, que e1 21,5%
proviene de los factores de forma del test propios de las formas verbales o grÃficas de los Útemes o reactivos y que solamente el 11,5% proviene de los
factores de contenido propios de contenidos elÕctricos o mecÃnicos. Nµtese que para los propµsitos de estimaciµn de la validez, la interpretaciµn del factor
general, que estima a partir de valores de heterorrasgo-heteromÕtodo de .49 y .45, es equÚvoca. Puede representar la varianza deseada de competencia, es
decir, componentes comunes a destrezas elÕctricas y mecÃnicas que tal vez resultan de una experiencia general en almacenes industriales, de componentes
comunes de capacidad, del traslapamiento de situaciones de aprendizaje y de otras semejantes. Por otra parte, este factor general puede representar un
traslapamiento de factores de mÕtodo, y deberse en ambos tests, a la presencia de formato de (temes o reactivns de elecraon mºltiple, hojas de respuesta IBM, o
a la heterogenidad de los sujetos en cuanto a su escrupulosidad, su motivaciµn para hacer tests y su adulteraciµn al realizarlo. Mientras no se
introduzcan en la matriz de validaciµn mÕtodos aun mÃs diferentes y rasgos aun mÃs independientes, este factor continuarà sin interpretaciµn. Desde este punto
de vista, puede notarse que el 21,5% es muy pobre como estimaciµn de la varianza total de la forma del test en los tests, pues representa solamente
componentes de la forma del test propios de los Útemes verbales o grÃficos, es decir, componentes de la forma del test que no comparten las dos formas. De
igual forma, y sobre bases mÃs esperadas que reales, el 11,5% de la varianza de contenido es una estimaciµn muy pobre de la varianza verdadera total de rasgo
de los tests, pues representa solamente la varianza verdadera de rasgo que no comparten el conocimiento elÕctrico y mecÃnico.
Carroll (1952) ha proporcionado datos sobre el inventario de Guilford-Martin de los factores STDCR y las estimaciones relacionadas, que pueden ser dispuestos de
una nueva manera en la matriz de la tabla 11. (La variable R ha sido invertida para reducir el nºmero de correlaciones negativas). Puede pensarse que dos de
los mÕtodos, las estimaciones de sÚ mismo y las puntuaciones de inventario, comparten varianza de mÕtodo y que, por tanto, tienen una diagonal de validez
"inflada". Los bloques heteromÕtodo mÃs independientes que contienen las estimaciones de los compaþeros tienen validez discriminante y convergente, con
diagonales de validez que promedian .33 (el inventario multiplicado por las estimaciones de compaþeros) y .39 (las estimaciones de sÚ mismo multiplicado por
las estimaciones de los compaþeros) en contraste con los valores de control heterorrasgo-heteromÕtodo que promedian .14 y .16. Aunque no es del todo eficaz,
el cuadro es mejor que la mayorÚa de las matrices de validez que hemos visto. Nµtese que las "estimaciones de sÚ mismo" muestran diagonales de validez
ligeramente mÃs altas que las puntuaciones de inventario, a pesar de la mayor longitud e indudablemente mayor confiab■idad del segundo. AdemÃs, parece que un
factor de mÕtodo falta casi totalmente en las estimaciones de sÚ mismo, mientras està fuertemente presente en el inventario, de manera que las estimaciones de sÚ
mismo quedan mejor cuando la verdadera varianza del rasgo se expresa como proporciµn de la varianza total confiable [como sugiere Vernon (1958)]. El
factor de mÕtodo en el inventario de STDCR es indudablemente acrecentado por la calificaciµn del mismo Útem o reactivo en varias escalas, lo que contribuye a la
varianza de error correlacionada, que puede reducirse sin perder confiabilidad mediante el recurso de agregar otros Útemes equivalentes y calificar cada Útem
solamente en una escala. Debe notarse que Carroll hace un uso explÚcito de la comparaciµn de la diagonal de validez con los valores de
heterorrasgo-heteromÕtodo como indicaciµn de validez.
AnÃlisis de reactivos y confiabilidad Las tÕcnicas para determinar cuÃles reactivos se deben conservar en una escala
se llaman tÕcnicas de anÃlisis de reactivos. Dicho en forma mÃs sencilla, se seleccionan los reactivos que se correlacionan mÃs estrechamente con los demÃs
reactivos de la escala. Obviamente, los reactivos que se correlacionan mÃs con cada uno de los otros tambiÕn se correlacionarÃn mÃs estrechamente con la
puntuaciµn total de la escala, que depende de la suma de aquÕllos. El procedimiento mÃs directo de anÃlisis de reactivos tal vez sea la tÕcnica de
correlaciµn de reactivo con el total, en la que basta con seleccionar los reactivos que tengan las correlaciones mÃs altas con la puntuaciµn total.
Gran parte de la teorÚa del anÃlisis de reactivos en la mediciµn educativa se basa en reactivos dicotµmicos y no policotµmicos. Como esta ºltima clase de
reactivos es mÃs importante en la mediciµn de actitudes, se omiten aquÚ las fµrmulas de reactivo can el total respecto de dicotomÚas, que suelen presentarse
en las tÕcnicas de anÃlisis de reactivos. La mayorÚa de las fµrmulas omiten, de la puntuaciµn total, el reactivo en estudio, porque cuando Õste se incluye la
correlaciµn resultante del reactivo con el total es espuriamente alta (Zubin, 1934; Guilford, 1954; Henrysson, 1963). Sin embargo, recientemente Cureton
(1966) seþalµ que la confiabilidad de la escala total con el reactivo omitido varÚa inversamente a la confiabilidad de dicho reactivo. De esta manera, Cureton
sugiere que el reactivo omitido se reemplace con un reactivo razonablemente equivalente (paralelo) en la puntuaciµn total. Hacer esto deja sin modificaciµn
la confiabilidad de la escala total. Cureton demostrµ tambiÕn que, si podemos suponer que la escala es homogÕnea factorialmente (monodimensional), entonces no
necesitamos realmente reemplazar el reactivo estudiado con uno razonablemente equivalente. Si pi,x es la correlaciµn, no corregida de reactivo con el total
para el reactivo iÕsimo, Si = σ־i/σ־x, pxx' es la confiabilidad de la escala
total; entonces, de acuerdo con Cureton, la correlaciµn corregida de reactivo con el total pi,x para el reactivo i-Õsimo es (21)
La fµrmula (21) es cierta para todos los reactivos ya sean o no dicotµmicos. Para usar (21) tambiÕn necesitamos conocer la fµrmula para las correlaciones no
corregidas de reactivo con el total. Dicha fµrmula es (22)
donde j toma todos los valores, incluyendo
i. Usando la informaciµn de arriba,
podemos computar un ejemplo usando (21). Consultando la tabla 1, computaremos la
correlaciµn de reactivo con el total para el reactivo 1. Empezaremos por
computar la correlaciµn no
corregida. El numerador de (22) es sencillamente .534 + .115 +. . .
+ .129 = 1.55 Sustituyendo este valor en (22) obtenemos pi,x = 1.55/√.5341√ 12.508
= .597 que es la correlaciµn no corregida de reactivo con el total. Vimos antes que pxx'=.70.
Calculando Si = √.534 / √12.508 = .206, podemos computar la correlaciµn
corregida. Esta es
Nµtese que la correlaciµn no corregida es aproximadamente .15 mÃs grande que la
corregida, que es una cantidad insignificante.
Cuando no se tiene una gran colecciµn de reactivos, deben seleccionarse aquellos
que tengan las mejores correlaciones de reactivo con el total, en su escala. Sin
embargo, deben recordarse tres puntos importantes: Primero, como lo indica la
figura 1, la confiabilidad se incrementa sµlo ligeramente al agregar reactivos
indefinidamente, asÚ que por lo comºn se usarÚan no mÃs de 15 reactivos en una
sola puntuaciµn. Segundo, la fµrmula (21) admite una sola dimensiµn que
fundamenta los reactivos y, a medida que se incrementa el nºmero de estos, tal
suposiciµn se vuelve cada vez menos sostenible. Tercero, cuanto mayor es el
nºmero de reactivos, tanto mÃs largo es el tiempo requerido para aplicar la
escala. Por tanto, se pueden tener muchos o pocos reactivos. Sin embargo, la
experiencia indica que lo ºltimo representa frecuentemente mayor problema que lo
primero.
Aunque este estudio de la confiabilidad es algo superficial, es suficiente para
proporcionar al investigador que desea elaborar una escala de actitud las
tÕcnicas para estimar la confiabilidad de su instrumento de medida. Finalmente,
es importante percatarse de las limitaciones del mÕtodo particular escogido. No
existe manera de determinar la confiabilidad exacta de un instrumento. Solamente
podemos obtener estimaciones y estas son adecuadas ºnicamente en el grado en que
se usen muestras adecuadas y en el grado en que se satisfagan las suposiciones
bÃsicas de una tÕcnica particular de estimaciµn.
Pasaremos ahora al estudio del segundo aspecto importante para decidir el valor
de una escala de actitud: su validez.
VALIDEZ
La validez tiene varios significados diferentes. Sin embargo, puede darse una
definiciµn muy general: La validez indica el grado en que un instrumento mide
la construcciµn que està en estudio. AsÚ, un test de inteligencia verbal vÃlido
es el que mide la inteligencia verbal y no alguna otra capacidad; una medida
vÃlida de sociabilidad solamente mide Õsta. Esto es, sin embargo, solo una
simplificaciµn, pues la validez puede descomponerse en varios tipos. La
Asociaciµn Norteamericana de PsicologÚa (American Psychological Asociation)
(1966) en su EstÃndares de test y manuales educativos y psicolµgicos enumera
tres tipos:
a) validez de contenido;
b)validez relacionada con un criterio y
c)
validez de
construcciµn.
Validez de contenido
La validez de contenido se refiere al grado en que las puntuaciµn o escala usada
representa el concepto acerca del cual se van a hacer generalizaciones. Aunque la
validez de contenido se considera cuidadosamente en la elaboraciµn de tests de
aprovechamiento y de eficiencia, suele en cambio ignorÃrsela en la elaboraciµn
de escalas de actitudes. Muchos investigadores, dentro de la rama de mediciµn de
actitudes, se han conformado con desarrollar un grupo de reactivos que, sobre
una base ad hoc, creen que miden lo que desean medir.
El investigador necesita examinar cuidadosamente la bibliografÚa respectiva para
determinar cµmo han usado el concepto los diferentes autores. AdemÃs, aquÕl debe
confiar en sus propias observaciones y experiencias y preguntar si ofrecen
nuevas facetas del concepto en estudio. Entonces, puede elaborarse una serie de reactivos que midan
cada uno de los subestratos, del dominio del contenido, procedimiento conocido
como muestreo de un dominio de contenido, Los instrumentos de medida muestran
validez de contenido en el grado en que el muestreo del dominio del contenido
sea representativo de todos los estratos y en el grado en que los reactivos
elaborados exploren las sutilezas de significado dentro de cada uno de estos
estratos.
La alienaciµn es, por ejemplo, un concepto que ha recibido gran atenciµn; y
Seeman (1959) advierte que teµricos e investigadores lo han usado por lo menos
de cinco maneras diferentes: impotencia, carencia de significado, carencia de
normas, aislamiento y autoenajenaciµn. Es fÃcil apreciar que alienaciµn se
superpone al concepto de "anomia" (carencia de normas). Un poco de reflexiµn
produce otros conceptos que deben considerarse para elaborar una medida de la
alienaciµn: apatÚa, disensiµn, extraþeza, privaciµn de derechos, y asÚ
sucesivamente. La cuestiµn aquÚ es que los investigadores usan volublemente la
alienaciµn no obstante que tiene diferentes significados. Conceptualmente, la
alienaciµn no es monodimensional en absoluto. Lo que quizà se necesita son
varias medidas, cada una de las cuales capte uno de los diversos significados
conferidos al concepto. Es probable que la validez de contenido se haya ignorado
por la enorme dificultad que lleva en sÚ la elaboraciµn de una escala o un
conjunto de escalas que muestren un dominio de contenido. Pese a esto debe
aclararse definitivamente que las medidas ad hoc poco es lo que nos dicen acerca
de lo bien que una medida explora los diversos estratos del dominio de
contenido. Los diferentes investigadores que emplean el mismo tÕrmino (por
ejemplo, alienaciµn) pueden obtener resultados diferentes en la predicciµn de
variables dependientes sencillamente porque en realidad estÃn midiendo
diferentes facetas de la construcciµn. Afirmaciones como "La inteligencia es lo
que miden los tests", representan un extremo en el operacionalismo, que, de ser
seguido, impedirÚa el desarrollo de las ciencias sociales como verdaderas
ciencias. Cuando un investigador desarrolla una medida de alienaciµn, le
corresponde tambiÕn describir el fundamento (teorÚa e investigaciµn) que
justifique llamar a una escala, elaborada con un conjunto particular de Útemes,
escala de "alienaciµn".
La validez de contenido no es fÃcil de lograr en la mayorÚa de las puntuaciones
o escalas, ya que comºnmente no podemos enumerar todos los elementos de su
poblaciµn (el dominio) y, por lo mismo, una muestra de ellos. Es imposible, de
ordinario, definir la poblaciµn con rigor µptimo a menos que se elabore algo
semejante a un test de vocabulario, mediante el cual pueda usarse un diccionario
para enumerar la poblaciµn. Por consiguiente, corresponde al investigador
explicar cµmo ha determinado las fronteras del dominio en estudio. Es necesario
indicar cµmo los reactivos utilizados aprehenden los diferentes significados que
los teµricos que lo han investigado le confieren a determinado concepto. Y deben
seþalarse, ademÃs, las lagunas lµgicas que haya en estas dos fuentes.
No hay un criterio estadÚstico aislado que pueda usarse para determinar si se ha
muestreado adecuadamente o no el dominio del concepto. Tampoco puede computarse
un sµlo coeficiente de validez de contenido. Sin embargo, el investigador puede
tomar varias precauciones para estar seguro de la representaciµn de los
diferentes matices de significado que haya dentro del dominio.
Primero, el dominio puede estratificarse en sus principales componentes. Uno
emplea simplemente los significados o facetas mÃs importantes y evidentes del
concepto, procurando estar tan seguro como sea posible de que la estratificaciµn
agota los significados del dominio. Uno puede decidir tomar cierto estrato y
dividirlo en subestratos, si el mencionado estrato no parece representar una
sola dimensiµn. De esta manera, la impotencia puede subdividirse en impotencia
polÚtica, econµmica y familiar, y asÚ sucesivamente. Cuanto mÃs se refinen estas
subÃreas, tanto mÃs fÃcil serà elaborar posteriormente los reactivos.
Segundo, pueden escribirse varios reactivos para captar los
matices de significado asociados a cada estrato y subestrato. "Varios" significa
no menos de siete a diez reactivos. Se puede decidir cada vez no incluir un
reactivo en una escala despuÕs que se han reunido los datos; pero un reactivo
que no se incluyµ se pierde para siempre. Esto es importante porque se encuentra
a menudo que varios reactivos no se comportaron de la manera esperada. Si
solamente se usan cinco reactivos para captar un estrato dado y se omiten dos
reactivos de la escala porque el anÃlisis de reactivos indique que no se
correlacionan bien con los otros, debe construirse una escala de tres reactivos.
Como vimos en la secciµn sobre confiabilidad, el nºmero de reactivos en la
escala de un investigador es importante para determinar la amplitud de su
estimaciµn de la confiabilidad. Rara vez son muy confiables las escalas de tres
reactivos. Puede descubrirse que lo que se creyµ un concepto monodimensional es
realmente bidimensional. Desafortunadamente, se puede terminar con sµlo tres
reactivos para medir una dimensiµn y con dos para la otra. Cuando se tienen diez
reactivos y se encuentra con un grupo de tres reactivos, separado de los otros
siete, el grupo principal contendrà por lo menos siete reactivos.
Tercero se puede analizar los grupos de reactivos despuÕs que se han recogido
los datos para determinar si los reactivos elaborados para medir el significado
de un estrato dado estÃn ya juntos. Determinar si los reactivos de un estrato se
correlacionan mÃs estrechamente entre sÚ que con los reactivos de otros
estratos. La suposiciµn que se hace es la siguiente: si un conjunto de reactivos
mide realmente un rasgo o actitud subyacente, entonces este rasgo o actitud
provoca la covariaciµn entre los reactivos. Cuanto mÃs altas sean las
correlaciones tanto mejores serÃn los reactivos que miden la misma construcciµn
subyacente. Se puede proceder de las maneras siguientes:
1. computar el promedio de las intercorrelaciones dentro de
un estrato y compararlo con la correlaciµn promedio de estos mismos reactivos
con reactivos incluidos en los otros estratos. La correlaciµn promedio dentro
del grupo debe ser mÃs alta que las correlaciones promedio entre los grupos. Si
la correlaciµn promedio entre los grupos es mÃs alta que la correlaciµn promedio
dentro de los grupos, los reactivos de un grupo, en promedio, pueden usarse para
predecir las respuestas a los reactivos de los otros estratos mejor de lo que
podrÚan predecir las respuestas a los reactivos dentro del estrato al que
pertenecen. Esto indicarÚa muy seguramente que uno o mÃs de los reactivos del
grupo no pertenecen al estrato al que fueron asignados originalmente.
2. Verificar las intercorrelaciones de cada reactivo con cada
uno de los demÃs del estrato, y comparar estas correlaciones del reactivo con
las de los reactivos de los otros estratos. Cuando un reactivo se correlaciona
un poco mÃs dentro de su propio estrato que dentro de otros, probablemente
pertenezca al estrato donde estÃ. Cuando este no es el caso, es preciso
localizar el estrato con el que, en promedio, se correlaciona mÃs altamente. Es
decir, averiguar dµnde se ajustan mejor estadÚsticamente los reactivos. Sin
embargo es necesario decidir despuÕs si el contenÚdo del reactivo mal colocado
concuerda con el del estrato al que se ha trasladado, ya que tambiÕn debe
ajustar semÃnticamente en el estrato.
Un reactivo que se correlaciona casi igualmente bien en dos
estratos, por lo general no es un buen reactivo. No es conveniente porque estÃ
en la frontera entre dos estratos. Incluirlo dentro de uno de los grupos
producirà una correlaciµn algo mÃs alta entre las dos puntuaciones, que si fuera
sencilla y enteramente omitido. En resumen, aunque no puede demostrarse la
validez de contenido con un sµlo coeficiente, pueden aplicarse procedimientos
estadÚsticos y lµgicos para asegurar que los reactivos tengan validez de
contenido.
Validez relacionada con un criterio
La validez relacionada con un criterio se determina
correlacionando la medida realizada con una medida directa de la caracterÚstica
en investigaciµn. Los criterios se dividen generalmente en concurrentes y
predictivos. Una escala de actitud diseþada para medir la ortodoxia religiosa
puede evaluarse concurrentemente preguntando sobre la asistencia a la iglesia.
Algunos instrumentos como los tests de actitud y de rendimiento, se diseþan
solamente con propµsitos de predicciµn. Pueden usarse para predecir el Õxito en
el trabajo o para predecir el Õxito o fracaso en la universidad y asÚ
sucesivamente. Determinar quÕ es concurrente y quÕ es predictivo no siempre
resulta fÃcil. Sin embargo, los criterios predictivos se reservan generalmente
para pronµsticos de largo alcance.
Debe quedar claro que una escala que tenga validez
concurrente no necesariamente tendrà validez predictiva. Un conjunto de
reactivos, que mide las creencias polÚticas, puede correlacionarse en alto grado
con el partido por el que una persona cree que votarà en noviembre. Sin embargo,
la escala puede correlacionarse algo menos con la conducta real del mismo
sujeto. Las actitudes cambian con el tiempo y, por tanto, la relaciµn que
mantienen con la conducta es algo menos que de uno a uno.
En tanto que la validez de contenido no es demostrable con un
solo coeficiente, la relacionada con un criterio sÚ. Como se indicµ
anteriormente, todo lo que hace el investigador es correlacionar su escala con
el criterio, y este coeficiente de correlaciµn es el que se toma como
coeficiente de validez. Sin embargo, este coeficiente puede atenuarse por falta
de confiabilidad, ya en la escala o en el criterio mismo. El mÕtodo de
correcciµn de no confiabilidad es la correcciµn por atenuaciµn [fµrmula (14)].
Por tanto, si una medida de ortodoxia religiosa tiene una confiabilidad de .8 y
la confiabilidad de la medida de asistencia a los servicios religiosos es .9, y
las dos medidas tienen entre sÚ una correlaciµn de .6, la correlaciµn verdadera
estimada entre las dos variables es de
.6 / √(.8) (.9) = .71. Es decir, la varianza de la
asistencia a la iglesia, explicada por la ortodoxia, aumenta aproximadamente el
14 % cuando se tiene en cuenta la falta de confiabilidad de las dos variables[
(.71)2 - (.60)2 = .14]. Como se indicµ anteriormente, la correlaciµn corregida
es solamente una estimaciµn de la correlaciµn verdadera entre las variables ya
que todos los componentes tienen distribuciones relativas a las muestras. Sin
embargo, cuando se tienen muestras grandes y buenas estimaciones de
confiabilidad, la correlaciµn corregida entre una escala y un criterio puede
suministrar informaciµn ºtil acerca de la validez de dicha escala.
Muchas de las construcciones de interÕs en la investigaciµn de actitudes no
tienen, ciertamente, un sµlo criterio con el que pueda comprobarse la validez de
la medida que se posee. El "criterio" puede ser muchas veces una medida mÃs
falsa de la construcciµn que la escala elaborada. Por ejemplo, este puede ser el
caso de las estimaciones de las caracterÚsticas de personalidad hechas por
psiquiatras. Esta es una razµn de lo indeseable que serÚa eliminar una escala
como medida invÃlida debido a una correlaciµn cercana a cero, a menos que se
estuviera convencido relativamente de la validez del criterio mismo. En la
secciµn siguiente, consideraremos otros mÕtodos de validaciµn cuando no existe
un sµlo criterio "sµlido".
Validez de construcciµn
La validez de construcciµn se evalºa investigando quÕ
cualidades mide un test, es decir, determinando el grado en que ciertos
conceptos o construcciones explicatorias dan razµn de la ejecuciµn en el test
(Asociaciµn Americana de PsicologÚa, 1966, pÃg. 13). Las Recomendaciones
tÕcnicas de la APA, indican ademÃs que los estudios de validez de construcciµn
se efectºan para validar la teorÚa que fundamenta la escala, puntuaciµn o test
elaborado. El investigador valida sus escalas investigando si confirman o niegan
las hipµtesis procedentes de una teorÚa que se basa en las construcciones. Por
supuesto, una de las limitaciones de este procedimiento es que la incapacidad
para predecir conforme a las hipµtesis puede ser resultado de falta de validez
de construcciµn o de una teorÚa incorrecta. No obstante, aquÚ nos
desentenderemos de este problema.
La validez de construcciµn se desarrollµ para reemplazar la
plÕtora de tÕrminos como "validez de aspecto", "validez lµgica", "validez
intrÚnseca", "validez factorial" y "validez de rasgo", que habÚan ido surgiendo
al paso de los aþos. Estos conceptos tenÚan diferentes matices de significado,
pero todos estaban ligados por la nociµn de que un rasgo o construcciµn
subyacente explicaba la varianza de la medida obtenida. A diferencia de muchas
construcciones de las ciencias fÚsicas, pocas de aquellas en las ciencias
sociales estÃn definidas operacionalmente, es decir, no hay aceptaciµn general
de conjuntos de operaciones como definiciones de construcciones. Cuando no hay
aceptaciµn de definiciones operacionales dentro de una disciplina, los
investigadores se muestran a veces altaneros y exclaman: "anomia" es lo que
miden estos cinco reactivos". Sin embargo, cuando solo unos cuantos
investigadores de determinada ciencia estÃn dispuestos a conformarse con la
definiciµn operacional se sobreviene la confusiµn. Diferentes investigadores
usan el mismo nombre de una construcciµn (por ejemplo, "anomia"), pero cada uno
con significado algo diferente. Cuando esto sucede, las generalizaciones en
torno a la construcciµn son imposibles de hacer ya que realmente no hay una sola
construcciµn en investigaciµn, sino una multitud de construcciones. Dado que no
estÃn especificadas exactamente muchas de las construcciones de las ciencias
sociales, es improbable la aceptaciµn de definiciones operacionales. Por tanto,
es relativamente raro que se pueda correlacionar su medida con alguna variable
de criterio real para evaluar su validez. En su lugar, son necesarios
procedimientos de validaciµn mÃs indirectos y esto seþala la necesidad del
concepto de validez de construcciµn.
Debido a la falibilidad de cualquier criterio aislado,
necesitamos validar nuestra medida de X con varias medidas independientes, las
cuales midan supuestamente a X. FigurÕmonos, por ejemplo, que estamos
interesados en elaborar una escala para medir el grado de la tendencia a ser
conservador en lo econµmico. PodrÚamos elaborar diez reactivos que averig■en las
opiniones acerca del laissez-faire del gobierno, la ayuda gubernamental a la
educaciµn y asÚ sucesivamente, de parte de todos los individuos que contesten
directamente. Sin embargo, para validar la escala elaborada con estos diez
reactivos podrÚamos pedir a los tres mejores amigos de cada sujeto interrogado
que complete los reactivos en la forma que creen los completarÚa el sujeto. Una
tercera medida serÚa incluir una estimaciµn personal, del sujeto acerca de la
semejanza de su propia filosofÚa con la de varios individuos bien conocidos y
podrÚa sugerirse que la varianza en los diez reactivos se deberÚa realmente no
al hecho de ser conservador econµmicamente sino a la clase social o a la
inteligencia. Podemos correlacionar nuestra medida original de conservadurismo
econµmico con las dos medidas independientes del mismo aspecto y con las medidas
de clase social y de inteligencia. Idealmente, las tres medidas independientes
de conservadurismo econµmico se correlacionarÚan estrechamente entre sÚ y,
ademÃs, la medida original no se correlacionarÚa grandemente con las medidas de
clase social y de inteligencia. Si tal sucediera, ello nos alentarÚa al grado de
aceptar la escala como una medida vÃlida de conservadurismo econµmico. Sin
embargo, supongamos que encontramos no solamente altas correlaciones entre
nuestras tres medidas, sino tambiÕn entre nuestra escala de clase social y de
inteligencia. Estas ºltimas correlaciones no invalidarÚan nuestra escala si por
razones teµricas esperÃramos estas correlaciones. Es decir, si la teorÚa
polÚtica predice una alta correlaciµn positiva entre conservadurismo econµmico y
clase social, y esto realmente sucede, se vÃlida igualmente la medida. Sin
embargo, las correlaciones entre las tres medidas de conservadurismo econµmico
deben ser mÃs altas que las correlaciones de la escala con otras variables, ya
que son medidas de la misma construcciµn.
TambiÕn debe quedar claro que una escala no debe
correlacionarse mucho con medidas de contenido diferente. Este es un requisito
especialmente importante cuando se desarrollan varias escalas para medir las
diferentes facetas de un dominio multidimensional. Por ejemplo, si se encuentran
cinco facetas en el dominio de alienaciµn, Õstas no deben correlacionarse mucho
entre sÚ; en caso contrario, habrÚa lugar a sospechar que el concepto no es
multidimensional despuÕs de todo y que los reactivos deben incluirse en una sola
puntuaciµn. ¢CuÃndo determinamos que las escalas se correlacionan demasiado
entre sÚ? Cuando hay varias medidas independientes de cada una de las cinco
dimensiones, las medidas independientes de la misma construcciµn deben
correlacionarse mÃs entre sÚ que con cualquier medida de cualesquiera otras de
las construcciones. Un intento por validar escalas examinando de esta manera una
matriz de correlaciones, ha sido realizado por Campbell y Fiske (1959) y se
llama procedimiento de multirrasgo-multimÕtodo. En el capÚtulo 4 se expone
detalladamente el mÕtodo, por lo que no lo tratamos aquÚ con amplitud.
Brevemente, Campbell y Fiske sugieren dos tipos de validaciµn
no mencionadas explÚcitamente en las Recomendaciones tÕcnicas de la APA, pero
que caen bajo el encabezado de validez de construcciµn. El primer tipo, la
validaciµn convergente, es la confirmaciµn de una relaciµn por procedimientos
independientes de medida. Por ejemplo, si se estuviera interesado en estudiar el
prejuicio (digamos, en una situaciµn de laboratorio), podrÚan obtenerse
estimaciones sobre sÚ mismo de parte de un sujeto mediante una serie de
reactivos que midieran actitudes hacia grupos minoritarios y, al mismo tiempo,
que se obtuvieran estimaciones de prejuicio, atribuibles al sujeto por sus tres
mejores amigos. Una tercera medida de prejuicio podrÚa ser una reacciµn
fisiolµgica (por ejemplo, la presiµn sanguÚnea) al ver una pelÚcula donde
individuos de varios grupos Õtnicos y raciales interaccionaran en una diversidad
de situaciones (por ejemplo, jugar a las cartas, citarse con personas del sexo
opuesto, y asÚ sucesivamente). PodrÚan despuÕs correlacionarse estas tres
medidas separadas de prejuicio. Cuanto mÃs altamente se correlacionaran entre sÚ
las medidas separadas, tanto mayor serÚa la validez convergente.
La segunda clase de procedimiento de validaciµn, mencionada
por Campbell y Fiske, es la validaciµn discriminante. La validaciµn
discriminante no necesita establecerse cuando el dominio no es monodimensional.
Se refiere al hecho de que las escalas que se correlacionan demasiado alto entre
sÚ pueden estar midiendo la misma construcciµn y no diferentes. AsÚ, si uno
elabora una medida y la llama "fatalismo", y despuÕs otra a la que denomina
"anomia", necesita demostrar que son construcciones diferentes correlacionando
entre sÚ las medidas y mostrando que la correlaciµn es mÃs baja que las
correlaciones entre medidas de la misma construcciµn. ¢QuÕ puede hacerse cuando
las medidas de construcciones diferentes se correlacionan demasiado alto? Pues,
sencillamente, deben verificarse las correlaciones de cada reactivo con cada uno
de los demÃs tanto dentro como entre los grupos. Los reactivos que se
correlacionan mÃs alto dentro de otro grupo probablemente pertenezcan a aquÕl y
no al escogido originalmente.
Aunque el asunto parece haberse resuelto, ha habido mucha
controversia acerca de la posiciµn lµgica del concepto de validez de
construcciµn desde su apariciµn en la ediciµn de 1954 de las Recomendaciones
tÕcnicas. En particular, Bechtaldt (1959), que contestµ no solamente a la
declaraciµn de las Recomendaciones tÕcnicas, sino tambiÕn al estudio ampliado
del concepto realizado por Crombach y Meehl (1955), mantuvo que las definiciones
operacionales son necesarias desde el punto de vista filosµfico y que la
introducciµn de un tÕrmino como validez de construcciµn va en contra de la
metodologÚa operacional.
RELACIÆN ENTRE CONFIABILIDAD Y VALIDEZ
Aunque las definiciones verbales de confiabilidad y validez
hacen una distinciµn muy clara de estos dos conceptos, hay casos donde esta
distinciµn està considerablemente oscurecida. Tal confusiµn se da especialmente
cuando se considera la consistencia interna como confiabilidad. Es patente que,
si se tienen n reactivos paralelos aplicados simultÃneamente, estos proporcionan
al instante varios test-retests. No obstante, otro aspecto es que todas las
correlaciones entre estas variables manifiestas se deben a las correlaciones
entre cada una de ellas y alguna construcciµn, rasgo o factor subyacente. Estas
ºltimas correlaciones indicarÚan la validez de cada reactivo, dado que indican
el grado en que cada uno de ellos se correlaciona con lo que se desea medir, es
decir, la construcciµn subyacente. La relaciµn entre estas dos perspectivas
sugiere la existencia de una estrecha relaciµn entre confiabilidad y validez.
Como Lord y Novick lo demuestran, la relaciµn està dada por
(23) P2xt = Pxx'.
El cuadrado del coeficiente de validez (donde la validez se define como la
correlaciµn de una puntuaciµn observada y su puntuaciµn verdadera) es igual a la
confiabilidad de la escala. Sin embargo, Lord y Novick seþalan ademÃs
que la validez determinada por la correlaciµn de la puntuaciµn con algºn
criterio "externo" nunca puede exceder a la correlaciµn de una puntuaciµn
observada con su puntuaciµn verdadera, es decir,
(24) Pxz
≤ PXT
√Pxx'
donde Z es el criterio. La implicaciµn de (24) es clara: la correlaciµn de una
escala con un criterio nunca puede exceder a la raÚz cuadrada de la
confiabilidad de la escala. AsÚ, si se tiene una medida con una confiabilidad
baja, digamos de .64, esa medida nunca se correlacionarà a mÃs de .8 con otra
medida. Esto demuestra que la confiabilidad y la validez van juntas. Si no se
puede medir confiablemente una actitud, nunca podrà predecir, con ella, ninguna
conducta real.
Sin embargo, es preciso cuidarse de no
interpretar errµneamente la fµrmula (23). No es cierto que la validez de una
escala pueda determinarse simplemente obteniendo la raÚz cuadrada de su
coeficiente de confiabilidad. Existen varias razones para tal negativa. Primero,
la raÚz cuadrada del primer miembro de (23) es la correlaciµn de la escala con
cualquier cosa que la escala mida. Y lo que realmente mida puede o no ser lo que
se desea que mida. Dicho de otra manera, (23) no nos dice nada acerca de la
validez de contenido o de construcciµn de la escala. Segundo, podemos obtener
solamente una estimaciµn de la confiabilidad y, si usamos (23) para estimar la
validez, las dos estimaciones serÃn totalmente dependientes. Le corresponde al
investigador presentar fa validaciµn independiente, conforme a Campbell y Fiske.
En realidad, ellos indican que el concepto de independencia es una manera de
distinguir la confiabilidad y la validez. La validez es la correlaciµn entre
medidas de la misma construcciµn cuando dichas medidas son independientes al
mÃximo. La confiabilidad refleja el grado, de acuerdo entre mÕtodos que guarden
entre sÚ la mÃyor semejanza posible.
Para resumir, existe sin
duda una relaciµn Úntima entre confiabilidad y validez, pero los procedimientos
de validaciµn deben ser independientes de los que establecen la confiabilidad de
la escala.
RESUMEN
El objetivo de la ciencia es explicar
relaciones entre variables. El logro de este objetivo depende en gran parte de
la capacidad del investigador para medir sus variables con el menor error
posible. Como se indicµ, los errores de medida tienden a distorsionar las
relaciones entre las variables. AdemÃs, necesita interesarse en que sus medidas
sean vÃlidas, esto es, que midan lo que se proponen medir. Si van a medirse
relaciones hipotÕticas entre las variables, el investigador necesita estar
seguro de que sus medidas de las variables sean confiables y vÃlidas.
En este capÚtulo hemos procurado exponer
varias de las maneras diferentes cµmo los investigadores comprenden los
conceptos de confiabilidad y validez, y de presentar las formas de estimar la
confiabilidad y la validez dados estos diferentes significados. No todos los
cientÚficos concuerdan con las interpretaciones aquÚ ofrecidas y el lector debe
reconocer que aºn se debaten estas cuestiones, aunque las Recomendaciones
tÕcnicas (1954) de la Asociaciµn Norteamericana de PsicologÚa hayan contribuido
bastante a resolver esta controversia. Por ejemplo, una comparaciµn interesante
entre el uso del tÕrmino "validez" en 1951 y su uso actual puede hacerse leyendo
a Cureton (1951). Sin duda, la polÕmica en torno a los significados de
confiabilidad y validez continuarà durante algºn tiempo.
Finalmente, debe reconocerse nuevamente que
la discusiµn se ha restringido mÃs que nada para facilitar la comprensiµn, de
una revisiµn algo superficial de los procedimientos de elaboraciµn de tests.
Solamente el investigador agudo puede elaborar reactivos que sean a la vez
confiables y vÃlidos y, por lo comºn, nadie se conforma con sus primeros
intentos de elaboraciµn de una escala. Sin embargo, al parecer muchos
investigadores se conforman con sus instrumentos de "primera preparaciµn" porque
muchas escalas de actitud se desarrollan y usan en una sola muestra. Pero, el
investigador escrupuloso determina la viabilidad del reactivo por medio del
muestreo y remuestreo de su poblaciµn de sujetos, reemplazando reactivos en
algunos casos y revisÃndolos en otros, hasta que està razonablemente satisfecho
de que tiene una escala eficaz. Estos procedimientos de validaciµn transversal
pueden significar que se empleen aþos para desarrollar medidas adecuadas. Pero
las medidas adecuadas son un prerrequisito para demostrar la utilidad de la
mediciµn de actitudes.
BIBLIOGRAFIA Evaluaciµn de la Confiabilidad y Validez en la Mediciµn de Actitudes La mediciµn es la condiciµn necesaria de cualquier ciencia. Es preciso obtener
medidas de todas las variables contenidas en determinada aseveraciµn teµrica para que pueda evaluarse la validez de Õsta. En las ciencias sociales, la
carencia de instrumentos de mediciµn ha sido el obstÃculo mÃs serio para el desenvolvimiento de una ciencia explicativa y predictiva. A diferencia del
fÚsico, que puede medir en gramos, centÚmetros y libras de presiµn por pulgada cuadrada, los cientÚficos sociales se han tenido que conformar una y otra vez
con instrumentos que, a lo sumo, ordenan a los individuos en relaciµn con una variable. En muchos casos, ni siquiera se ha dispuesto de los mÃs elementales
aparatos de medida.
La mediciµn no ha progresado rÃpidamente en las ciencias sociales por diversas razones. Quizà la mÃs importante sea que los conceptos
sustentadores de la ciencia a menudo no estÃn bien definidos. Con frecuencia los investigadores no concuerdan en cuanto al significado de conceptos confusos como
"alienaciµn", "eficacia polÚtica" y "prejuicio". Para cubrir cada uno de estos contenidos se han elaborado varias medidas diferentes; pero hay escasas pruebas
de que las medidas que supuestamente cubren la misma construcciµn se correlacionen altamente con otra. Es decir, podrÚa cuestionarse la validez de
las diferentes medidas. ¢Miden estos instrumentos lo que se proponen medir?
Es asimismo interesante preguntarse quÕ tan confiablemente son ordenados los individuos por, determinado instrumento de medida. Suponiendo
que aquÕllos no cambien, ¢son ordenados de la misma manera al volverse a medir? Si no es asÚ, el investigador nunca podrà estar seguro de conocer la verdadera
ordenaciµn de los individuos en la variable.
La necesidad de evaluar la confiabilidad y la validez de las medidas resulta evidente. En la mediciµn de actitudes existen varias tÕcnicas
con respecto a tal evaluaciµn. Constituyen estas tÕcnicas la esencia del presente capÚtulo. No todos los mÕtodos importantes pueden analizarse con el
detalle necesario para quien desea algo mÃs que una introducciµn a estas Ãreas. Quienes deseen mÃs amplia informaciµn pueden consultar a Lord y Novick (1968),
Horst (1966) y Gulliksen (1950).
Aunque no todos los experimentos de mediciµn de actitudes son escalas o puntuaciones basadas en varios reactivos, muchos de aquÕllos sÚ lo
son. Es decir, se supone que la escala usada es la suma de varios reactivos y no que es uno solo. Al hacer tal suposiciµn, bastante de lo dicho sobre
confiabilidad y validez se convierte en anÃlisis de reactivos. El anÃlisis de reactivos es la selecciµn de uno de estos para incluirlo en una escala de
puntuaciµn fundada en la confiabilidad y la validez del mismo. Los detalles del anÃlisis de reactivos constituyen una parte de lo que trataremos en esta
secciµn.
Comenzaremos por un anÃlisis elemental de la teorÚa de la mediciµn y continuaremos estudiando la confiabilidad y la validez para concluir
con una parte que relaciona entre sÚ confiabilidad y validez.
Errores de Medicion
La mediciµn es la asignaciµn de nºmeros a resultados conforme ciertas reglas. Puede asignarse arbitrariamente el nºmero 0 a todos los hombres
y el nºmero 1 a todas las mujeres; o asignarse el 0 a todas las personas de 1.20 m o menos de estatura; el 1, a los que estÕn entre 1.20 m y 1.30 m; el 2, a los
que miden entre 1.30 y 1.50 m y asÚ sucesivamente. Estas reglas de correspondencia se llaman funciones. ObsÕrvese que en el ºltimo ejemplo la
medida es relativamente tosca En efecto, la medida original, la estatura en centÚmetros, es varias veces mÃs afinada que la regla de correspondencia
empleada. En la investigaciµn deben usarse las medidas mÃs afinadas de que se disponga, toda vez que cuanto mejor sean aquÕllas, con tanta mayor exactitud
podrÃn evaluarse las verdaderas relaciones subyacentes entre las dos variables. AdviÕrtase que cuando se usan centÚmetros o la regla de correspondencia es mÃs
elemental, puede afirmarse que cuanto mayor sea al nºmero mÃs alta serà la persona; pero esto no es cierto en todos los niveles de medida. En el primer
ejemplo, el hecho de que los hombres sean 0 no nos dice nada acerca de sus posiciones relativas con respecto a las mujeres (aunque algunos hombres casados
pudieran molestarse por esta afirmaciµn). Esto no significa otra cosa sino que en lo referente a algunas reglas de correspondencia uno no puede decir sino que
los resultados estÃn o no en la misma clase nominal (mediciµn de escala nominal). En otras, solamente puede decirse si un resultado es o no mÃs grande
que, menor que, o igual a, otro resultado (mediciµn de escala ordinal). En otras mÃs, puede decirse exactamente cuÃntas unidades es mayor o menor un
resultado que otro (mediciµn de escala intervolar). Finalmente, en pocos casos puede uno decir, ademÃs, que un resultado es n veces mÃs grande o mÃs pequeþo
que otro (mediciµn de escala de razµn) . Algunos ejemplos pueden ayudar a entender la distinciµn entre estos cuatro niveles de medida. La asignaciµn de
diferentes nºmeros para representar los 50 estados de la Uniµn Americana es una clasificaciµn sin ordenaciµn y es, por consiguiente, solo mediciµn nominal.
Pedir a personas que escojan a tres conocidos y los ordenen por nivel de amistad, serÚa mediciµn ordinal. En la mediciµn de escala intervalar y de razµn,
se supone que los intervalos entre los nºmeros estÃn igualmente espaciados. AsÚ, en una escala de temperatura Fahrenheit, la diferencia entre 25 y 26 grados es
igual a la diferencia entre 30 y 31 grados, es decir, un grado. AdviÕrtase que en la ordenaciµn de los amigos la diferencia de afecto entre los amigos 1 y 2
puede ser completamente diferente de la que hay entre los amigos 2 y 3. Es decir, en la mediciµn ordinal los intervalos no tienen por quÕ ser iguales. La
mediciµn de razµn difiere de la mediciµn intervalar en que las escalas de razµn tienen puntos cero verdaderos y no arbitrarios. Las escalas Fahrenheit y
centÚgradas son medidas de intervalo, ya que ambas tienen puntos cero arbitrarios; no representan la carencia absoluta de temperatura. Sin embargo, la
escala Kelvin de temperatura tiene un punto cero absoluto, y es, por tanto, una escala de razµn. Cuando es posible la mediciµn de razµn puede decirse que un
resultado es n veces mayor o menor que otro. Un muchacho de 1.60 m de estatura es el doble de alto que otro de 80 cm. Sin embargo, cuando hablamos de
temperaturas Fahrenheit no podemos decir que 60 grados sea el doble de calor que 30 grados. Los lectores interesados en estudiar mÃs ampliamente las diferencias
entre estos niveles de mediciµn pueden consultara Stevens (1951).
El estudio siguiente supone por lo menos la mediciµn intervalar. Es evidente que pocas variables en las ciencias sociales pueden
medirse con una escala intervalar; y el lector puede preguntarse por quÕ entonces se presenta dicho material. La razµn es sencilla: en la ciencia, rara
vez pueden satisfacerse exactamente las suposiciones implÚcitas en los instrumentos que se usan. Y, desafortunadamente, por lo comºn, cuanto mÃs
poderoso es el instrumento para hacer inferencias cientÚficas, tanto mÃs difÚcil es satisfacer dichas suposiciones. Cuando determinado campo està en progreso
constante, los investigadores deben procurar elaborar instrumentos de medida que tengan caracterÚsticas que se aproximen a los postulados que fundamentan su uso,
para no convertirse en puristas matemÃticos que desechen tales instrumentos. Esta ºltima posiciµn es semejante al rigor mortis cientÚfico. Los cientÚficos
sociales que han adoptado la primera posiciµn han demostrado que los resultados obtenidos con la suposiciµn de datos intervalares han sido fructÚferos. Esa
suposiciµn permite estimar el grado de asociaciµn entre variables, y previene contra la simple estimaciµn de si existe o no asociaciµn.
Suponer medida intervalar donde solamente hay medida ordinal ocasionarà algunos errores de medida. El resultado de los errores es
generalmente la atenuaciµn de las relaciones entre las variables. Es decir, resultados comprobados perderÃn algo de su evidencia real. Es improbable, por
tanto, que la decisiµn de suponer mediciµn intervalar cuando Õsta no està presente conduzca a la sobreestimaciµn espuria de resultados' . Nuestro estudio
darà ahora un tratamiento algo matemÃtico de la mediciµn y de los errores de medida.
La puntuaciµn Xi observada, de una persona en un reactivo
individual puede considerarse una funciµn de su puntuaciµn verdadera Ti mÃs el error de medida ei. La relaciµn que une la puntuaciµn observada con la
puntuaciµn verdadera y el error se define entonces asÚ:
Xi=Ti+ei
Es verdad que los errores de medida atenºan la asociaciµn entre dos variables. Sin embargo, es posible obtener, en
el caso de k variables, correlaciones parciales y coeficientes de regresiµn inflados por errores de medida.
DespuÕs, se hacen las siguientes suposiciones:
(2a) E(ei) = 0 E representa el valor esperado o media "a la larga" de la variable y
ρ es la correlaciµn entre dos variables en una poblaciµn dada. La suposiciµn 2a indica que la expectativa de los errores es 0. Se presentan errores positivos y
negativos, pero se espera que se supriman entre sÚ, a la larga, y que su media sea 0. Esto coincide con nuestra intuiciµn de lo que significa error aleatorio.
La suposiciµn 2b indica que la puntuaciµn verdadera en determinada variable no se correlaciona con su error de medida; y la 2c indica que las puntuaciones
verdaderas de una variable no se correlacionan con los errores de una segunda variable. Finalmente, 2d afirma que los errores de las variables no estÃn
correlacionados entre sÚ. De estas suposiciones se derivan varios resultados importantes. Primero, E(Xi) = E(Ti).
Es decir, el valor esperado de las puntuaciones observadas es igual al valor
esperado de las puntuaciones verdaderas. La importancia de esta relaciµn es que la media de las puntuaciones observadas (un observable) es una estimaciµn
imparcial de la media de las puntuaciones verdaderas (un no observable). Otro resultado importante es que
σ2Xi= σ2Ti + σ2ci
La varianza de las puntuaciones observadas es sencillamente la suma de la varianza de las puntuaciones verdaderas y de los errores. Claro està que
generalmente la varianza de sumas no es la simple suma de las varianzas individuales; sin embargo, en este caso es cierto, ya que,
segºn 2b, se supone que las puntuaciones verdaderas y los errores no estÃn correlacionados. Usando estas definiciones, suposiciones y teoremas resultantes,
podemos pasar a discutir la teorÚa de la confiabilidad.
CONFIABILIDAD Cuando se ha construido un instrumento de medida se necesita saber quÕ tan
confiablemente ordena a los individuos. Si estos no pueden ser colocados confiablemente en la escala, Õsta no poseerà ninguna utilidad cientÚfica, pues
los resultados que se basen en ella probablemente contengan grandes errores. ¢QuÕ significa confiabilidad? Su mejor sinµnimo vez sea consistencia. Si no
suceden cambios verdaderos en la actitud que mantiene un individuo, ¢la escala de actitud lo coloca consistentemente en el mismo lugar en relaciµn con otros?
Si la respuesta es no, la escala no es confiable. La confiabilidad no es, indudablemente, asunto de todo o nada; existen grados de confiabilidad.
La confiabilidad se define por un coeficiente de correlaciµn. MÃs precisamente, la confiabilidad (σxx) se define como la correlaciµn entre dos medidas
paralelas. Antes de analizar el fundamento de esta definiciµn, consideremos lo siguiente. Supongamos que se
tiene dos medidas X y X' tales que X =T + e, X'= T + e' yσ2e=
σ2eÇ. Nµtese que tanto X como X' son funciones de la misma puntuaciµn verdadera y difieren
solamente por los diferentes errores de medida. Por esto se afirma que las medidas X y X' son paralelas. La correlaciµn entre esas dos medidas paralelas
indica la confiabilidad de la medida de la variable en estudio. De la definiciµn
de medidas paralelas, se obtienen dos resultados inmediatos que son: E(X) = E(X') Y
σ2X= σ2X'
Ahora bien, la confiabilidad de la medida està dada por
ρxx'=σxx'/σxσx'
= σ2T/σ2X'
donde σxx' es la covarianza
entre X y X'. VÕase aquÚ que la confiabilidad de una medida es la razµn de la varianza de la puntuaciµn verdadera a la varianza total. Se advierte ademÃs que
0 ≤ σxσx'≤1.0. La confiabilidad serà 0 cuando toda la varianza de la
puntuaciµn verdadera està compuesta de error. RepÃrase en esto al observar que σ2Xi= σ2Ti + σ2ci
; por tanto, cuando toda la varianza de la puntuaciµn verdadera es de error, es decir, σ2X= σ2e, se infiere que σ2T = 0, y
ρxx'= 0. Esto aclara tambiÕn por quÕ la confiabilidad
serà la unidad cuando no hay error. Aunque no damos aquÚ la prueba, puede demostrarse que si Y1, Y2, Y3 . . . son
medidas paralelas y Z es otra variable aleatoria diferente, entonces (8)
ρY1,Y2 =ρY1,Y3 =
ρY2,Y3 =... Y (9)
ρY1,Z =ρY2,Z =
ρY3,z =... Las igualdades de (8) indican que las intercorrelaciones entre todos los
reactivos paralelos son iguales. Esto indica que las confiabilidades de medida son independientes de las formas paralelas que se usan cuando Õstas son
realmente paralelas. Y (9) indica ademÃs que las intercorrelaciones de todos los
tests paralelos a otra variable son iguales.
La regresiµn de puntuaciones verdaderas en puntuaciones observadas
SerÚa interesante saber lo bien que pueden predecirse las puntuaciones verdaderas a partir de las variables observadas. Fue demostrado por Lord y Novick
(1968) que βTX= ρXX' y
(11)Ť =
ρXX'X + (1- ρXX')μx'
donde βTXes un coeficiente de regresiµn Ť es la puntuaciµn verdadera
pronosticada y X es la puntuaciµn observada. Es decir, el coeficiente de regresiµn para predecir las puntuaciones verdaderas a partir de las puntuaciones
observadas es justamente el coeficiente de confiabilidad, y la intersecciµn es 1 menos tantas veces el coeficiente de confiabilidad como la media de las
puntuaciones observadas. Se infiere de (11) que cuando la confiabilidad de una medida es alta, se da mucha importancia a las puntuaciones observadas y poca a
la media de grupo en la predicciµn de las puntuaciones verdaderas. Sin embargo, cuando una medida no es confiable, se pone poco Õnfasis en las puntuaciones
observadas y mucho en la media de grupo. La dispersiµn de los errores, llamada error estÃndar de medida, es (12) σe
=σx√1 - ρXX' Con Õl se pueden formar intervalos de confianza alrededor de la puntuaciµn
verdadera de una persona. VÕase que en (12) el error estÃndar de medida se acerca a 0 cuando la confiabilidad de la medida realizada se aproxima a la
unidad, como era de esperarse. Si se supone que los errores estÃn distribuidos normalmente, puede decirse que para todas las personas con cierta puntuaciµn
verdadera, la probabilidad de que la puntuaciµn observada se encontrarà dentro de mÃs o menos k veces el error estÃndar de medida de la puntuaciµn verdadera es
de por lo menos 1 - a, donde a es la probabilidad de un error de tipo 1 y k es una funciµn de a . No obstante, es imposible construir semejante intervalo
alrededor de las puntuaciones observadas usando el error estÃndar de medida. TambiÕn es posible computar la desviaciµn estÃndar alrededor de la lÚnea de regresiµn que se ajusta
a la predicciµn de las puntuaciones verdaderas a partir de las observadas. Este es el error estÃndar de estimaciµn y se expresa por
(13) σe =σx√ρXX'
√1 - ρXX'
Puede demostrarse que, en general, el error estÃndar de estimaciµn es menor que
el error estÃndar de medida. Esto sucede porque la ºltima medida emplea en su derivaciµn tanto la media de grupo como la confiabilidad, mientras que la
primera solamente usa la confiabilidad. La comparaciµn de (12) y (13) muestra que difieren por el factor √ρXX' que debe
ser igual o menor que la unidad. Por tanto, (13) debe ser igualmente pequeþa o menor que (12). Hemos visto cµmo se define la confiabilidad y la forma en que
Õsta influye en la predicciµn de la puntuaciµn verdadera de un individuo. Ahora estudiaremos cµmo la no confiabilidad afecta la correlaciµn entre dos variables.
Atenuaciµn debida a la no confiabilidad Como se indicµ anteriormente, el error aleatorio posee el efecto de reducir la
relaciµn entre dos variables. Puede probarse fÃcilmente que (14)
ρT1T2 = ρX1X2 √ρx1x1'ρx2x2' Es decir, la correlaciµn verdadera entre las variables,
ρT1T2 disminuye debido a la no confiabilidad de ambas variables. Puesto que las confiabilidades de X1 y
X2 en (14) son necesariamente menores o iguales que la unidad, ρT1T2 debe ser mayor o igual que ρx1x2. Las dos serÃn iguales solamente cuando
ρx1x1' = ρx2x2' = 1.00. Por ejemplo, supongamos que
ρx1x2 = .5, y ρx1x1'= .8 y
ρx2x2'= .8. Sustituyendo estos valores en (14) obtenemos
ρT1T2 = .5√.64 = .625. De esta manera apreciamos cµmo afecta la falta de confiabilidad la explicaciµn de
la varianza de una variable por otra observando los coeficientes de determinaciµn, es decir, comparando
ρ2T1T2 y ρ2x1x2 . Puesto que
ρ2T1T2 = .39 y ρ2x1x2 = .25, la no confiabilidad explica una disminuciµn aproximada
del 14% de la varianza explicada. Desafortunadamente, muchas de nuestras escalas de actitudes tienen confiabilidades aºn menores que .8, lo cual explica
por quÕ las correlaciones entre estas escalas y otras variables a menudo son muy bajas. Si los investigadores deben o no corregir las correlaciones observadas, por
atenuaciµn debida a la falta de confiabilidad de las variables, ha sido objeto de innumerables debates. Haremos varias evaluaciones. Primero
ρT1T2 es un parÃmetro dÕ la poblaciµn pero en realidad se opera con muestras y Õstas solamente dan estimaciones de los parÃmetros. La estimaciµn de
ρT1T2 puede ser particularmente errµnea ya que no solamente son estimaciones las confiabilidades
en el denominador del segundo miembro de (14), sino que la correlaciµn observada en el numerador es tambiÕn una estimaciµn. AsÚ, dependiendo de quÕ tan estables
sean las estimaciones de cada uno de los tres parÃmetros, el valor de
ρT1T2 puede fluctuar ampliamente. Hacer la correcciµn por atenuaciµn depende parcialmente de la confianza que se tenga en estas estimaciones.
AdemÃs, cuando se informan los resultados de un estudio de predicciµn,
generalmente no se corrige por atenuaciµn. Los investigadores, por lo comºn, no estÃn interesados en quÕ tan bien podrÚa predecirse una medida si Õsta fuera
confiable, sino quÕ tan bien se predice en realidad. No obstante, en el examen de la relaciµn causal y en la estimaciµn de la relaciµn causal verdadera entre
dos variables, estarÚa a la orden la correcciµn de la atenuaciµn, suponiÕndose que existen buenas estimaciones de los parÃmetros. Por ejemplo, si se estuviera
interesado en predecir el activismo polÚtico de estudiantes universitarios a partir de una escala para medir la actitud hacia la autoridad, probablemente no
vendrÚa a la imaginaciµn la correcciµn de la atenuaciµn. En este caso se desearÚa saber si puede determinarse quiÕnes serÃn los activistas y
evidentemente los errores de mediciµn afectarÚan esta determinaciµn. En contraste, si un investigador estuviera interesado en hacer una estimaciµn de
cµmo estÃn relacionadas teµricamente estas dos variables es decir en ausencia de error, entonces, de confiar en sus estimaciones de confiabilidad;
podrÚa corregir la atenuaciµn.
Tipos de confiabilidad y su mediciµn Hasta ahora solo hemos hecho una exposiciµn teµrica general de la confiabilidad.
Ahora se estudiarÃn formas concretas de medir la confiabilidad. Generalmente, las medidas de confiabilidad se dividen en dos grandes clases: medidas de
estabilidad y medidas de equivalencia. Medidas de estabilidad, La puntuaciµn de una persona en una escala de actitud
puede variar de una mediciµn a otra. El sujeto puede distraerse momentÃneamente, entender equivocadamente el significado de un
reactivo, responder de maneras diversas en ocasiones distintas porque alguien mÃs estÕ presente, y por otras mºltiples causas. Todas estas fuentes de error
contribuirÃn a la falta de confiabilidad de una escala de actitud. AquÚ, el problema consiste en como evaluar la cantidad de no confiabilidad de las medidas
tomadas. Una manera muy popular de evaluarla consiste en correlacionar las respuestas de las personas, en una ocasiµn, con sus respuestas dadas en otra
ocasiµn posterior. La confiabilidad evaluada correlacionando una medida a travÕs del tiempo se llama medida de estabilidad o confiabilidad de test-retest.
Existen algunos problemas obvios en la estimaciµn de la confiabilidad por test-retest: Pueden darse diferentes resultados segºn sea el lapso entre la mediciµn y la
remediciµn. Mientras mÃs largo sea el lapso, tanto menor serà la estimaciµn de la confiabilidad. Por esta razµn, cuando el lapso es corto, las personas pueden
recordar cµmo contestaron en la primera aplicaciµn de los reactivos, para aparecer asÚ como mÃs consistentes de lo que son realmente. Para solucionar este
problema, algunos investigadores modifican el procedimiento de test-retest usando una segunda forma, paralela en cuanto a contenido a la usada en la
primera aplicaciµn, si bien se usan reactivos diferentes. Cuando desarrolla un instrumento de medida, el investigador escribe doble nºmero de reactivos para
medir determinado dominio de contenido. La mitad de los reactivos se usa en la primera forma y la otra mitad en la segunda. Si las formas son verdaderamente
paralelas, se correlacionarÃn exactamente, igual con otras variables cualesquiera. AdemÃs, las medias y las desviaciones estÃndar de las dos formas
serÚan idÕnticas y las intercorrelaciones entre los reactivos serÚan iguales en ambas versiones. Obviamente, es muy difÚcil, si no imposible, satisfacer estos
criterios, de lo que se infiere que pocas "formas paralelas" de tests son realmente paralelas. Sin embargo, es posible, por medio de una selecciµn
cuidadosa de reactivos, elaborar dos formas que sean aproximadamente paralelas. Si no es posible hacerlo, entonces pueden correlacionarse las formas paralelas a
travÕs del tiempo como medida de confiabilidad. El uso de formas paralelas reduce el grado en que por el recuerdo de sus respuestas anteriores los sujetos
provoquen estimaciones espuriamente altas de confiabilidad. Un segundo problema con las estimaciones de confiabilidad de test-retest es que
las puntuaciones verdaderas de los individuos tienen una probabilidad mas grade de cambiar realmente, cuanto mÃs largo sea el intervalo de tiempo entre el test
y el retest. Claro està que si los individuos han cambiado verdaderamente una correlaciµn baja de test-retest, ello no significa por fuerza que la
confiabilidad de la escala de actitud sea baja. En un trabajo reciente, Heise (1969) ha demostrado que con tres observaciones a travÕs del tiempo es posible
distinguir entre cambio y falta de confiabilidad, si los intervalos entre las aplicaciones son iguales y si puede suponerse que los errores de mediciµn no
estÃn correlacionados a travÕs del tiempo. Sin el uso de formas paralelas, esta ºltima suposiciµn serÚa muy difÚcil de satisfacer.
El coeficiente de confiabilidad se definiµ como (15)ρxx' =
ρ12ρ23 /
ρ13 donde los subÚndices se refieren al periodo de medida. Heise ofrece un ejemplo
de Crowther (1965), en el que se usaron correlaciones entre puntuaciones en el test de inteligencia California Test of Mental Maturity en los grados tercero,
sexto y noveno para estimar la confiabilidad del CTMM. Las correlaciones fueron de r12 =.56, r23 =.65 y r13 = .52. Segºn la fµrmula (15)
rxx'=.70. AdviÕrtase que rxx' es algo mayor que todas las correlaciones individuales de test-retest, lo que demuestra que han ocurrido algunos cambios en la
inteligencia segºn la mide el CTMM. AdemÃs de dar una estimaciµn de confiabilidad, el mÕtodo ofrece coeficientes que
indican la cantidad de cambio del momento 1 al momento 2, del 2 al 3 y del 1 al 3. Heise designa sij a estos coeficientes y demuestra que s12 = ρ13 /
ρ23, s23 = ρ13 /
ρ12 y s13 = ρ12 /
ρ23. Para los datos de arriba, s12 = .80, s23 = .93, y s13 = .74, lo que indica que el CI medido cambia mÃs entre los grados tercero y
sexto que entre los grados sexto y noveno, lo cual se ajusta a muestras expectativas. Heise ha proporcionado asÚ una manera ºtil de separar la no
confiabilidad y el cambio cuando se tienen tres medidas de momentos diferentes. Otro problema que el investigador debe enfrentar cuando usa cualquier
procedimiento de test-retest es el llamado problema de reactividad (Campbell y Stanley, 1963; Webb, Campbell, Schwartz y Sechrest, 1966); Õsta se refiere a que
la sensibilidad o inclinaciµn del sujeto a responder a la variable en estudio puede hacerse mÃs grande por el hecho de medirla. Preguntarle a un sujeto
sus opiniones-polÚticas en una ocasiµn puede aumentar su interÕs en los asuntos polÚticos e inducirlo a que discuta y lea acerca del tema y, por tanto,
que cambie con el paso del tiempo, cambio que no habrÚa ocurrido en otra persona semejante en todos los demÃs aspectos pero que no hubiera sido entrevistada. En
esta situaciµn, la correlaciµn de test-retest es mÃs baja porque ha ocurrido un cambio, no debido a una variable experimental, sino a la reactividad. Al
parecer, no hay soluciµn sencilla a este problema. Debido a los problemas inherentes al procedimiento de test-retest para evaluar
la confiabilidad, muchos investigadores han abandonado las medidas de estabilidad por las llamadas medidas de equivalencia; estudiaremos ahora algunos
de estos mÕtodos. Medidas de equivalencia. Se supone que cuando se juntan varios reactivos en
una misma escala de actitud, los reactivos miden la misma actitud bÃsica. En este sentido, cada reactivo puede considerarse como una medida de la actitud.
Las estimaciones de confiabilidad que miden la equivalencia de cada reactivo en tanto indicador de una actitud fundamental se llaman, con razµn, medidas de
equivalencia. El primer tipo de medidas de equivalencia que aparecieron fueron los mÕtodos de divisiµn en mitades. En el mÕtodo de divisiµn en mitades, se
divide Õl nºmero total de reactivos por la mitad y las mitades se correlacionan para obtener una estimaciµn de la confiabilidad. Por sµlidas razones ha caÚdo en
desuso este procedimiento. Algunos investigadores usaron los reactivos pares oponiÕndolos a los impares; otros correlacionaron la primera mitad de la escala
con la segunda; y asÚ sucesivamente. Cada una de estas divisiones podÚa dar, naturalmente, estimaciones diferentes de confiabilidad. En efecto, en una escala
de 2n reactivos de longitud, el nºmero total de divisiones posibles es 2(n!) / 2(n!)(n!). En una escala de 10 reactivos, hay 126 divisiones posibles, y todas diferentes. Algunas darÃn
estimaciones de confiabilidad por encima de la confiabilidad verdadera y otras por debajo. Por tanto, las mitades de la divisiµn pueden estar lejos de ser
equivalentes. La mayorÚa de los investigadores que han usado la tÕcnica de divisiµn en mitades
han aplicado generalmente la fµrmula de predicciµn de Spearman-Brown a la correlaciµn obtenida entre las dos partes. Esta fµrmula fue descubierta
simultÃnea pero independientemente por Spearman (1910) y Brown (1910); y fue desarrollada para discernir el efecto del incremento de la longitud de una
medida. Como podÚa suponerse, cuanto mayor es el nºmero de medidas independientes que se tienen de un fenµmeno, tanto mayor es la confiabilidad de
una medida compuesta basada en estas medidas. Spearman y Brown mostraron que la confiabilidad de una escala que es n veces mÃs larga que la escala original es
(16)ρxnxn' = nρxx' / 1+(n-1)ρxx'
donde ρxnxn' es la confiabilidad de la escala mÃs larga. Sin embargo, aun cuando la fµrmula de
predicciµn de Spearman-Brown indica que el incremento de longitud de la escala aumenta la confiabilidad, en Õsta existe un punto en que comienza a disminuir.
Es obvio que cuanto mÃs alta sea la confiabilidad inicial, tanto menor serà el incremento de la confiabilidad como una funciµn de los reactivos agregados.
La fµrmula de Spearman-Brown se usa algunas veces con correlaciones de divisiµn en mitades
para obtener una estimaciµn de la confiabilidad de la puntuaciµn de 2 n reactivos. Esto requiere cierta explicaciµn. En el cµmputo de confiabilidad por
el mÕtodo de divisiµn en mitades, el test completo (ambas mitades) debe aplicarse a todos los sujetos. De este modo, la correlaciµn entre las mitades es
la estimaciµn de la confiabilidad de una escala de solo la mitad de la escala realmente usada. La fµrmula de predicciµn de Spearman-Brown se usa entonces para
estimar la confiabilidad de la escala completa, que tiene 2 n reactivos. Por ejemplo, supongamos que un investigador tiene 16 reactivos que se diseþaron para
explorar los sentimientos de eficacia polÚtica. Selecciona arbitrariamente 8 de los reactivos, los aþade en una sola puntuaciµn, los 8 restantes en una segunda
y los correlaciona. Una correlaciµn razonable de las dos mitades serÚa .65. Sin embargo, el investigador desea emplear la escala completa de 16 reactivos como
un instrumento de medida y, por consiguiente, usa la fµrmula de predicciµn de Spearman-Brown con n = 2. Sustituyendo ρxx'
=.65 y n = 2 en (15), se obtiene ρx2x2' = 2(.65)/(1 + .65) = .788, que es la estimaciµn de confiabilidad de la escala de
actitud de 16 reactivos. Por la forma arbitraria en que se escogen las mitades, este procedimiento no se recomienda generalmente para determinar la
confiabilidad. Un segundo mÕtodo de equivalencia se basa en la correlaciµn de formas paralelas
basadas cada una en datos recogidos en un momento dado. Como se indicµ cuando estudiamos los mÕtodos de test-retest, las formas paralelas no son divisiones
arbitrarias de reactivos. Se supone que para cada reactivo de una forma hay otro exactamente paralelo en la segunda versiµn. El uso de formas paralelas estÃ
limitado solamente por la dificultad de construirlas. Por esta razon, el mÕtodo desarrollado por Kuder y Richardson (1937) es el mÕtodo recomendado para
computar un coeficiente de equivalencia. Este mÕtodo llamado de consistencia interna, examina la covarianza entre todos
los reactivos simultÃneamente y no en una divisiµn particular y arbitraria. Las fµrmulas de Kuder - Richardson y las generalizaciones quÕ provienen de ellas
siguen siendo el enfoque mÃs popular de la confiabilidad. Las fµrmulas originales fueron desarrolladas para reactivos dicotµmicos solamente y se
denominaron KR20 y KR21, respectivamente. En ambas fµrmulas, Kuder y Richardson supusieron que todos los reactivos eran paralelos, y en KR21, que la proporciµn
que contestµ positivamente todos los reactivos era igual (algunas veces llamada "la dificultad" del reactivo). Sea n igual al nºmero de reactivos dicotµmicos en
una medida, pi la proporciµn que contestµ positivamente el reactivo i y
ρ2x la varianza de la escala total, entonces
donde
μxes la media, piqÀ es la varianza del reactivo
i-Õsimo (qÀ = 1 - pi) y ρx la varianza de la puntuaciµn total. La fµrmula (17) es la mÃs general y, por
consiguiente, la mÃs ºtil de las dos; es la que debe usarse para computaciones efectivas. Como ejemplo del uso de KR20, supongamos que se ha elaborado una
escala de cinco reactivos para medir la religiosidad, donde se pidiµ a los sujetos que expresaran ya acuerdo (respuesta "positiva") ya desacuerdo
(respuesta "negativa"), y donde el acuerdo con un reactivo se codificµ como 1 y el desacuerdo como 0. Ahora bien, para computar ρxx necesitamos conocer tambiÕn la varianza de la
puntuaciµn total, ρ2x, que podrÚa computarse de dos maneras. Primero, sumando
sencillamente las respuestas a los cinco reactivos de cada individuo en una sola puntuaciµn y calculando despuÕs la varianza de esta nueva variable. La segunda
manera serÚa computar la varianza de la puntuaciµn total a partir de las varianzas de reactivo de las covarianzas. RecuÕrdese que en reactivos
calificados con 0 o 1 la varianza del reactivo À es dada por σi = piqÀ, donde qÀ es 1 - pi. AdemÃs, la covarianza entre dos reactivos
i y j cualesquiera es σi = pij
- pipj ; donde pij es la proporciµn que contestµ positivamente a los dos
reactivos i y j. Conociendo las varianzas y las covarianzas de los reactivos puede computarse la varianza de la puntuaciµn total con el siguiente teorema
sobre la varianza de la suma de variables: (19)
Supongamos que computamos las proporciones, varianzas y covarianzas de los cinco reactivos y encontramos lo siguiente: Los valores de la diagonal principal son las varianzas de los reactivos y fuera
de dicha n n diagonal estÃn sus covarianzas. Para computar ∑ni=1
ρ2x, que en este caso tambiÕn es
∑ni=1pi
qi, sumamos la diagonal principal, es decir, .09 + .21 + .21 + .24 + .16 = .91. De manera
anÃloga,
2∑ni=1
∑nj=1 σij ,es simplemente dos veces la suma de los elementos que estÃn
fuera de la diagonal, es decir, 2(.07 + .O5 + .04 + .08 + .11 + .08 + .04 + .07 + .13 + .11) = 2(.88) = 1.76. Por tanto,
ρ2x = .91 + 1.76 = 2.67. Vimos arriba que
∑ni=1pi
qi, =.91, que es simplemente otra expresiµn de la suma de la varianza de los reactivos.
Sustituyendo esta informaciµn en (17) tenemos:
ρxx' = 5/4 1 - .91 /2.67= .82 Es
decir, la confiabilidad de esta escala de cinco reactivos es .82.
Con el paso de los aþos se han sucedido varias fµrmulas que son generalizaciones de la fµrmula 20 de Kuder-Richardson (Jackson y Ferguson, 1941; Hoyt, 1941; y
Gulliksen, 1950); pero todas se han expuesto con diferentes suposiciones. La caracterÚstica comºn a todas estas fµrmulas es que permiten computar una
estimaciµn de confiabilidad cuando los reactivos tienen k categorÚas de respuesta en lugar de solamente dos. Sin embargo, Novick y Lewis (1967)
demostraron que todas estas fµrmulas hacÚan la suposiciµn de que la puntuaciµn verdadera de un individuo era exactamente igual en todos los reactivos o, por lo
menos, que sus puntuaciones verdaderas en los reactivos diferÚan entre sÚ solo por una constante, condiciµn que llaman: tau-equÚvalencia esencial. AsÚ, si se
tienen dos reactivos a y b, son esencialmente tau-equivalentes si Ta = Tb + c, donde c es una constante. Evidentemente si c = 0, por las primeras definiciones,
los reactivos son paralelos. Por tanto, la tau-equivalencia es una suposiciµn menos restrictiva que la suposiciµn de reactivos paralelos, ya que las
puntuaciones verdaderas pueden diferir, de un reactivo a otro, por una constante. Esto significa que cuando los reactivos son tau-equivalentes, KR20 y
las generalizaciones derivadas de ella son todas iguales a la confiabilidad de la puntuaciµn total. En el grado en que estos reactivos no son tau-equivalentes,
estas fµrmulas tienden a subestimar el coeficiente de confiabilidad, aunque no gravemente, a menos que los reactivos se aparten radicalmente de la
tau-equivalencia. La generalizaciµn de KR20 que ha obtenido la mayor popularidad es a la que Cronbach llamµ cx (1951),
y es (20) Usando los datos
de un estudio de Ford, Borgatta y Bohrnstedt (1969), mostraremos aquÚ el uso de a. Para medir la cantidad de competitividad deseada para el personal nuevo, de
nivel universitario, contratado por una gran compaþÚa, se diseþaron ciertos reactivos. Los siguientes son nueve de esos reactivos que se incorporaron en una
sola medida llamado afÃn competitivo: 1. Los incrementos de salario estarÃn estrictamente en relaciµn con lo que usted
ha hecho por la empresa. 2. Se sabe que la empresa està comprometida en una fuerte competencia.
3. Se supone que las personas son despedidas tanto si no hacen algo bien como si no lo siguen haciendo bien. 4. Hay
oportunidades de ganar bonificaciones. 5. Se entablarà y alentarà la competencia.
6. El supervisor debe ser un severo crÚtico. 7. Se hace hincapiÕ en el registro efectivo de la producciµn.
8. Los aumentos de sueldo tendrÃn que ver con el esfuerzo que ha realizado usted. 9. Las recompensas pueden ser
grandes, pero se sabe que muchas personas fallan o desertan.
Se obtuvo la matriz de covarianza que aparece en la tabla, que se basa en una muestra k de 869 hombres empleados. Para computar a, necesitamos
∑ki=1ρ2i,, que es
simplemente la suma de los elementos de la diagonal, es decir, (.534+ .411+ . . . + .679) = 4.68 . AdemÃs necesitamos computar σ2x, o sea, la varianza de la escala total.
El lector puede verificar en (19) que esta varianza es igual a la suma de los elementos de la diagonal principal mÃs dos veces la suma de los elementos que no
estÃn en la diagonal. Ya hemos determinado la suma de la diagonal. Ahora la suma de los elementos fuera de la diagonal (.115 + .168 + . . . +
.093) = 3.919 y el doble de esta suma es 7.828. AþÃdase esto a la suma de la diagonal y se obtiene σ2x= 12.508. Por
consiguiente, a = 9/8(1 - 4.68/12.508) = .70. Es decir, la estimaciµn de la
confiabilidad de la consistencia interna en relaciµn con la puntuaciµn de afÃn competitivo es de .70. Dada esta estimaciµn de confiabilidad, podemos usar (12)
para computar el error estÃndar de medida. En este ejemplo es σe = √12.508
√1 - .70 = 1.94. Ahora bien, si suponemos que los errores estÃn distribuidos normalmente y deseamos estar seguros en un 99 % de que todas las personas con
puntuaciones verdaderas de Tx se encuentran dentro de k errores estÃndares de medida desde Tx, sabemos por la teorÚa de las distribuciones normales que k =
2.58 (Hays, 1963). Por tanto, si tomamos Tx = 15, los lÚmites inferior y superior del intervalo de confianza son 15 - (2.58) (1.94) y 15 + (2.58)
(1.94) = 5.01 µ 9.99 y 20.01 respectivamente. Es decir, la probabilidad de que las personas con una puntuaciµn verdadera de 15 tendrÃn una puntuaciµn observada
que se encuentre entre 9.99 y 20.01, es de .99. Matriz de covarianza de
reactivos en la puntuaciµn de "AfÃn de competencia" ( N = 869 Varones),
los valores subrayados en la diagonal son las varianzas de los reactivos TambiÕn podemos sustituir en (11) para obtener la ecuaciµn de regresiµn y
predecir asÚ la puntuaciµn verdadera de un individuo a partir de su puntuaciµn observada. En este ejemplo, suponemos que Mx = 18 donde Mx es la media de la
escala, luego, la ecuaciµn de regresiµn es
T =.70 + (.3) (18) = .70X + 5.4.
Un sujeto con una puntuaciµn observada de 15 tendrÚa una puntuaciµn verdadera pronosticada de (.70) (15) + 5.4 = 15.9. El error estÃndar de estimaciµn para
esta ecuaciµn de predicciµn nos lo da (13), y en este ejemplo es de
√ 12.508 √.70 √1 - .70 = 1.62, que es la desviaciµn estÃndar de los errores
alrededor de la lÚnea de regresiµn.
En la mayorÚa de las investigaciones de actitudes no estamos interesados en la
predicciµn de la puntuaciµn verdadera de un individuo porque generalmente solo se presenta la estimaciµn de la confiabilidad. Sin embargo, el investigador debe saber que es posible la predicciµn individual y por esto se computµ en el ejemplo anterior.
RELACIÆN DE LA RESPUESTA CON EL ATRIBUTO
Hemos visto varias tÕcnicas de elaboraciµn de escalas psicolµgicas, tÕcnicas que son completamente distintas en procedimiento, pero
que difieren aºn mÃs en su fundamento filosµfico. La tÕcnica que usemos para evaluar por escala determinado atributo, ¢no es importante? Algunos psicµlogos
sostienen que cualquier tÕcnica puede conducir a una escala vÃlida, siempre que describamos las operaciones particulares que nos condujeron a ella. Pero tal
posiciµn es esencialmente conformista, ya que rehºsa enfrentar el problema de la naturaleza del atributo mismo y la relaciµn de la escala obtenida con aquÕl.
En particular, es fundamental la diferencia de posiciµn filosµfica entre las tÕcnicas manifiestas y las latentes. Las primeras confÚan
en la capacidad del sujeto para describir su experiencia de un atributo, por medio de nºmeros con las propiedades adecuadas de mediciµn. Las tÕcnicas
latentes no hacen tal suposiciµn pero aceptan que sµlo hay un atributo que afecta las respuestas, aunque no del modo simple de uno a uno.
Realmente hay muchas posiciones teµricas que se han tomado sobre la relaciµn de la respuesta manifiesta y el atributo. Mientras que una discusiµn
tal no es necesariamente parte de un capÚtulo sobre elaboraciµn de escalas psicolµgicas, la selecciµn de la tÕcnica no puede sino depender de las
suposiciones que el experimentador haga en torno a la relaciµn de la respuesta y el atributo. En este sentido, las citadas suposiciones sÚ son parte del problema
de construcciµn de escalas.
Al clasificar las diferentes posiciones teµricas, podemos considerar que hay cuatro procesos crÚticos cuando se trata de medir por escala un atributo.
- Existen, en primer tÕrmino, los objetos con los que supuestamente se corresponde el atributo; pero este no es idÕntico al objeto. El objeto tendrÃ
muchas propiedades y aunque alguna de sus dimensiones fÚsicas estÕ estrechamente relacionada con una de aquÕllas, no hay ninguna razµn para que los valores escalares del atributo deban corresponder a los de la dimensiµn fÚsica.
- Segundo, tenemos el atributo mismo. Existe como una abstracciµn del objeto, pero una abstracciµn que es experimentada, directamente y en la mayorÚa de los
casos, por un sujeto humano u observador. Son los valores escalares de este atributo lo que buscamos al elaborar escalas psicolµgicas y, como mencionamos
anteriormente, uno de los problemas principales es determinar quÕ propiedades de mediciµn existen en ese atributo. Hacer esta pregunta es completamente diferente
a inquirir cµmo està relacionado el atributo con una dimensiµn fÚsica o con las respuestas, porque deseamos conocer el atributo mismo y no podemos determinar
si, por ejemplo, el atributo tiene un cero verdadero o absoluto que muestre su vÚnculo con una dimensiµn fÚsica que tiene un cero absoluto.
- En un proceso mediatorio, es decir, un proceso que media entre el atributo y la respuesta que lo refleja. Hemos usado el tÕrmino "proceso
mediatorio" como tÕrmino general, si bien en casos especÚficos podrÚamos llamarlo variable interventora o construcciµn hipotÕtica. Pero, como quiera que
se le llame, debemos considerar la posibilidad de su operaciµn. Y, mÃs importante aºn, es que debemos considerar la posibilidad de que contribuya con
sus propias caracterÚsticas para relacionar la respuesta y el atributo. En otras palabras, si existe un proceso mediatorio y deseamos conocer la naturaleza del
atributo, tendremos entonces que conocer algo de la naturaleza del proceso mediatorio tambiÕn.
- Finalmente, tenemos el proceso mismo de respuesta, pero si,no lo hemos tratado hasta este momento no significa, de ninguna manera, que sea el menor de
nuestros problemas. Si debe usarse una respuesta para indicar las propiedades del atributo, es natural que nos interesemos por las propiedades del proceso
mismo de aquÕlla. Por ejemplo, si el atributo tiene propiedades intervalares, claro està que la respuesta tambiÕn deba tener, por lo menos estas propiedades
para que indique correctamente las que pertenezcan al atributo. Y no es una conclusiµn decidida de antemano que las propiedades de los nºmeros, como las usa
el sujeto humano, tienen necesariamente las propiedades de razµn de la escala de los nºmeros.
Como dijimos antes, casi todos los psicµlogos concuerdan en que las respuestas pueden indicar por lo menos las propiedades ordinales de un
atributo. Cualesquiera que sean las distorsiones introducidas por un proceso mediatorio o por las peculiaridades del proceso mismo de respuesta serÃn
distorsiones de propiedades intervalares y de razµn y no de propiedades ordinales. Por tal razµn, la mayorÚa de las posiciones teµricas se han ocupado
principalmente de las propiedades intervalares y de razµn del atributo o demostradas por las respuestas.
La respuesta como indicador directo del atributo
La suposiciµn mÃs sencilla que puede hacerse acerca de la relaciµn entre respuesta y atributo es que aquÕlla indica directa y
correctamente las propiedades de Õste. Si se supone que existe un proceso mediatorio, se presume tambiÕn que Õste es desviado por el proceso de respuesta.
Decir que esta suposiciµn es la mÃs sencilla no significa que sea la menos compleja, porque es muy difÚcil de probar. Consecuentemente, su validez es por
lo comºn de variedad aparente, es decir, vale por mandato del experimentador.
En aþos recientes, Stevens (1957) y algunos de sus colaboradores, han sido los principales expositores de esta posiciµn, aunque el
primero se ha interesado casi exclusivamente por atributos psicofÚsicos, es decir, atributos sensoriales que tienen un continuo fÚsico equivalente como la
brillantez, la sonoridad, etc. Ha apoyado, en lo que se refiere a elaboraciµn de escalas, el uso de las tÕcnicas manifiestas de razµn, y aunque en principio
acepta la validez de cualquiera de estos mÕtodos, sus ºltimos trabajos (Stevens, 1959) indican una fuerte preferencia por el mÕtodo de estimaciµn de magnitud.
Este fuerte hincapiÕ en una tÕcnica especÚfica plantea algunas cuestiones, ya que esperarÚamos que todas las tÕcnicas de la misma clase
lµgica fueran igualmente capaces de conducir a la misma escala psicolµgica. Dicho de otra manera, debe haber generalidad con respecto a la tÕcnica.
Aºn mÃs, como seþalamos anteriormente, una escala de razµn debe predecir correctamente las propiedades de intervalo; y si aceptamos la
validez de las tÕcnicas manifiestas de razµn, tambiÕn debemos esperar que las tÕcnicas equivalentes manifiestas de intervalo, proporcionen la misma escala
psicolµgica dentro de los lÚmites de la tÕcnica. Pero las tÕcnicas manifiestas de intervalo no proporcionan la comprobaciµn cruzada que se requiere.
La razµn de esta dificultad puede encontrarse en el problema de la naturaleza y propiedades del proceso mismo de la respuesta, ya que Õste no
puede indicar exactamente las propiedades de un atributo, a menos que se use con precisiµn, con propiedades por lo menos tan potentes como las del mismo
atributo. Vimos en la figura 3 que los datos de Torgerson describÚan una relaciµn inversa entre escalas de oscuridad y brillantez cuando se usaban
escalas de categorÚas numÕricas. Torgerson obtuvo, asimismo, juicios con el mÕtodo de estimaciµn de magnitud. Tanto para la oscuridad como para la
brillantez, obtuvo escalas muy diferentes a las obtenidas con escalas de categorÚas numÕricas, pero el logaritmo de la escala de estimaciµn de magnitud
estuvo relacionado linealmente con la escala mencionada. Por otra parte, las escalas de claridad y de oscuridad obtenidas por medio de estimaciones de
magnitud estaban relacionadas de modo recÚproco, y no inverso. Estos resultados de Torgerson aclaran que los sujetos humanos no usan escalas numÕricas de la
misma manera cuando asignan categorÚas numÕricas que cuando hacen estimaciones de magnitud. AdemÃs, si aceptÃramos por sus propios mÕritos los resultados de
cada mÕtodo, tendrÚamos que concluir que el atributo de oscuridad es el inverso del atributo de claridad, en un caso; pero que es el recÚproco en el otro caso.
Estos mismos resultados esclarecen que la validez de las suposiciones requeridas en las tÕcnicas manifiestas de razµn o manifiestas de
intervalo es bastante dudosa. La comprobaciµn mÚnima de la validez de las suposiciones no arroja resultados favorables y solamente podemos llegar a la
consecuencia de que no es evidente que las tÕcnicas manifiestas sean vÃlidas.
La respuesta como indicador del proceso mediatorio
La mayorÚa de los psicµlogos modernos suponen que la respuesta es indicador de una variable interventora o proceso mediatorio.
Algunos suponen, sin embargo, que la respuesta es un indicador relativamente directo del proceso intermedio, y otros que puede estar relacionada pero muy
indirectamente. Estudiaremos primeramente esta primera clase de teorÚas y despuÕs las otras.
.- Proceso correlacionado. Una de las teorÚas mÃs directas de que la respuesta està relacionada con un proceso mediatorio afirma
que aquÕlla se conecta directamente con un proceso que està correlacionado con el atributo. Existen muchos ejemplos de este punto de vista en la bibliografÚa
sobre escalas de destrezas, actitudes, etc. Por ejemplo, el efecto de halo es una descripciµn de la tendencia a evaluar personas en base a un atributo de
acuerdo con sus estimaciones previas en otro. De Soto (1961) ha seþalado la tendencia de las personas a evaluar a los demÃs o a los objetos en un orden
consistentemente sencillo.
MÃs especÚficamente, en el dominio de los continuos psicofÚsicos, Warren (1958) desarrollµ la teorÚa del juicio de correlato fÚsico.
Sostiene bÃsicamente que las respuestas que dan los sujetos no indican las propiedades del atributo mismo, sino que reflejan las propiedades de una
dimensiµn fÚsica correlacionada que el sujeto ha experimentado al usar los nºmeros.
Afirma, por ejemplo, que cuando los sujetos habÚan tenido experiencia directa en el uso de una escala numÕrica, sus respuestas de razµn
manifiesta estarÚan relacionadas linealmente con el continuo fÚsico subyacente. De esta manera, los juicios de peso estarÃn relacionados directamente con la
escala fÚsica de peso, porque todos tenemos experiencia de kilos y gramos. Warren aporta pruebas de que esto es asÚ cuando se desecha el factor
contaminante de tamaþo. De manera similar, los juicios de dulzura estarÃn relacionados directamente con la concentraciµn fÚsica del edulcorante, porque
las personas han tenido experiencia con cantidades de azºcar. Y, por la misma razµn, los juicios de distancia o longitud estarÃn relacionados directamente con
la dimensiµn fÚsica.
La mayorÚa de las personas no ha tenido experiencia directa con la dimensiµn fÚsica de intensidad, por ello no puede juzgar directamente
atributos como la brillantez o sonoridad. Pero hay una dimensiµn fÚsica relacionada estrechamente con la sonoridad y la brillantez y con la cual las
personas han tenido considerable experiencia: la distancia. Warren sostiene que los juicios de un medio de sonoridad o de brillantez son realmente juicios del
doble de la distancia equivalente; y presenta datos que muestran que los juicios de brillantez o sonoridad y distancia estÃn relacionados. En otras palabras, un
sujeto afirma que determinado sonido es la mitad de sonoro que otro cuando su fuente parece estar dos veces mÃs distante.
Las pruebas de Warren al respecto (vÕase Warren, Sersen y Pores, 1958, y Warren y Poulton, 1960) son convincentes y sugieren ciertamente
que los sujetos pueden aprender a usar numerales con propiedades de razµn si lo hacen en base a una dimensiµn fÚsica que efectivamente posea esas propiedades.
Si pueden o no transferir esta destreza a descripciones de un atributo con el que no han tenido experiencia numÕricà directa es un problema que està pendiente
de soluciµn.
.- Proceso de interacciµn. Otro punto de vista acerca de la relaciµn de la respuesta y el atributo es que hay un proceso mediatorio
que interacciona constantemente con el atributo, de manera que la respuesta a cualquier objeto de estÚmulo es una funciµn conjunta del atributo y del proceso
mediatorio. Pese a que Helson y Michels no describieron sus funciones teµricas exactamente de esta manera es Õsta una forma compatible de considerarlas.
Helson (1948, vÕase tambiÕn 1959) formulµ originalmente su teorÚa del nivel de adaptaciµn, interesado mÃs que nada en la determinaciµn de
las condiciones de estÚmulo que conducen a un juicio "neutro" en una tÕcnica de escala verbal de estimaciµn. Sostuvo que el nivel de adaptaciµn en determinado
instante es la media geomÕtrica probada de todos los estÚmulos, pasados y presentes, y de sus efectos sobre el atributo que se juzga. El nivel de
adaptaciµn cambia constantemente a medida que se experimentan nuevos objetos de estÚmulo. El juicio neutro, ya sea un rµtulo verbal en una escala de estimaciµn
o el valor medio en una escala numÕrica, siempre corresponderà a este nivel de adaptaciµn.
Pero Helson sostuvo que todos los demÃs juicios se hacen en relaciµn con tal nivel. Se interesµ no sµlo en el juicio neutro sino por todos
los juicios verbales o numÕricos sobre la longitud entera de la escala. Expuso, en otras palabras, una teorÚa acerca de la relaciµn entre las respuestas y el
atributo. Esta relaciµn fue expresada matemÃticamente en forma mucho mÃs explÚcita por Michels y Helson (1949), quienes derivaron una relaciµn entre las
respuestas y la intensidad del estÚmulo, que se corresponde formalmente con la ley de Fechner pero con esta diferencia importante: Fechner supuso que el origen
(en el sentido matemÃtico) del atributo sensorial era el umbral absoluto, mientras que Michels y Helson sostienen que el origen es el nivel de adaptaciµn.
MÃs especÚficamente, aseguraron que la primera categorÚa de respuesta (en una escala de categorÚas) correspondÚa a una magnitud de estÚmulo de 1 kÕsimo por
debajo del nivel de adaptaciµn (donde k es el nºmero de categorÚas de juicio por debajo del neutro) y que todas las demÃs respuestas se ajustaban para satisfacer
este requisito.
Michels (1954) llegµ a esta deducciµn al interpretar los juicios de fraccionamiento de brillantez sobre las mismas bases y,
posteriormente (Michels y Doser, 1955) hizo lo mismo con respecto a los juicios de sonoridad. Este no es el lugar para exponer la formulaciµn matemÃtica exacta
que usµ Michels, lo que no resta importancia al punto de vista expresado por Helson y Michels acerca de la relaciµn entre la respuesta y el atributo.
Debe recordarse que el nivel de adaptaciµn està cambiando constantemente y que serà diferente para cada conjunto de condiciones
experimentales. Por tanto, sostener que la respuesta es siempre relativa al nivel de adaptaciµn significa que no hay relaciµn invariable entre la respuesta
y el objeto de estÚmulo o el continuo fÚsico subyacente. Podemos expresar esta posiciµn ya sosteniendo que la escala del atributo no es estable, ya afirmando
que el nivel de adaptaciµn es un proceso mediatorio que interacciona constantemente con el atributo (o posiblemente con el continuo de respuesta), de
manera que nunca podemos obtener experimentalmente una relaciµn invariable entre estÚmulo y respuesta.
Indudablemente esta posiciµn relativista con respecto a la elaboraciµn de escalas psicolµgicas tiene considerable respaldo experimental,
porque la mayorÚa de los experimentos sobre mediciµn por escalas no dan muestras de una relaciµn invariable entre respuesta y dimensiµn fÚsica subyacente. Garner
(19546) ha mostrado, por ejemplo, que los juicios de fraccionamiento obtenidos con el mÕtodo de estÚmulos constantes dependen casi completamente de la amplitud
de los estÚmulos de comparaciµn presentados, es decir, del contexto de los estÚmulos que se presentan para ser juzgados. Sin embargo, aºn serÚa posible que
hubiera un atributo estable significativo y que nuestro problema fuera determinar sus propiedades, procurando realizar operaciones experimentales que
tuvieran en cuenta estas caracterÚsticas de respuesta y de juicio.
La respuesta como indicador indirecto del atributo.- La tercera posiciµn importante acerca de la relaciµn de respuesta y atributo
està en que la respuesta no refleja directamente las propiedades del atributo, ni siquiera a travÕs de un proceso mediatorio, sino que està relacionada solo
directamente con el atributo. No se supone, en este caso, que las propiedades numÕricas de la respuesta indiquen las propiedades numÕricas del atributo.
Fundamentalmente todas las tÕcnicas latentes se basan en tal suposiciµn. Por ejemplo, en las comparaciones por pares normalizados ni siquiera
se pide a los sujetos que hagan algo mÃs que un juicio ordinario. Y en los rangos normalizados de categorÚas, aunque los sujetos emplearan efectivamente
una respuesta intervalar, no se supone que esta propiedad se mantenga cuando se determinen los valores escalares. O sea que los sujetos pueden usar el mÕtodo de
escalas de categorÚas numÕricas, pero el experimentador supone despuÕs solamente la propiedad ordinal al elaborar su escala.
Aun en la tÕcnica que usµ Garner para elaborar una escala de sonoridad a partir de juicios de equisecciµn y fraccionamiento se desistiµ del
supuesto de que la razµn numÕrica indicada en las situaciones de fraccionamiento era la razµn verdadera.
Claro està que si las propiedades numÕricas de las respuestas no se consideran adecuadas para reflejar exactamente las propiedades del
atributo, deben hacerse algunas suposiciones para recobrar las propiedades numÕricas de la escala; aquÚ se encuentra el aspecto fundamental del problema de
estas tÕcnicas indirectas y latentes. Cuando se establecen tales suposiciones, Õstas deben validarse antes de que podamos aceptar razonablemente que la escala
psicolµgica es significativa. En una tÕcnica como la de rangos normalizados no se proporcionan medios para comprobar la validez de la suposiciµn de normalidad;
pero en la mayorÚa de las tÕcnicas, tales procedimientos sÚ son posibles. Por ejemplo, en las comparaciones por pares normalizados la capacidad de usar la
escala promedio para comprobar cada escala individual permite determinar cuÃndo no se aplica la suposiciµn de normalidad.
En cierto sentido, estas tÕcnicas suministran valores escalares de un atributo que es realmente una construcciµn hipotÕtica. Puede o
no "existir"; pero su existencia supuesta y las propiedades expresadas permiten, a menudo, integrar una gran cantidad de datos.
RESUMEN No hemos podido evitar comentarios evaluativos tanto acerca
de las tÕcnicas que hemos analizado como acerca de las diferentes posiciones teµricas concernientes a la relaciµn entre respuesta y atributo. SerÚa
conveniente, sin embargo, establecer, a modo de resumen, lo que consideramos explÚcitamente que son los criterios por medio de los cuales deben evaluarse las
tÕcnicas y algunas de las opiniones acerca de ellas.
Una escala psicolµgica e incluso el atributo mismo son conceptos que usa el experimentador porque le proporcionan el significado y la
generalidad que a su vez le permiten integrar un cuerpo mÃs grande de datos o hechos en pocos principios de trabajo. La funciµn total de tales conceptos en
una ciencia gira alrededor de la idea de generalidad. La ciencia no busca sencillamente datos, ni siquiera simples hechos. En su lugar busca hechos que
tengan algºn grado de generalidad, de manera que no tengamos tantos hechos como acontecimientos posibles haya en el mundo. La generalidad puede existir en
muchas clases diferentes de cosas, y aquÚ es donde debemos considerar la evaluaciµn de las tÕcnicas: ¢de cuÃntas maneras diferentes suministran
generalidad las escalas? En tanto que existen muchas cosas diferentes de las que podrÚamos esperar finalidad, hay algunas que son de importancia capital en la
evaluaciµn de las tÕcnicas de elaboraciµn de escalas.
.- Tiempo. Una escala psicolµgica debe ser invariable por lo menos a travÕs del tiempo; pero no hemos hallado muchas dificultades en este
respecto, porque fa mayorÚa de las tÕcnicas que han permanecido han demostrado poca varianza cuando se repite el experimento en diferente ocasiµn.
.- Sujetos. Como en el anterior, en este punto no existe mucha diferencia entre las tÕcnicas. La mayorÚa de ellas prevÕn obtener datos de
varios sujetos diferentes, asÚ que podemos estar bastante seguros de la invariabilidad a travÕs de una poblaciµn especÚfica.
.- Objetos. Nos gustarÚa encontrar escalas psicolµgicas que; fuesen vÃlidas para todos los estÚmulos u objetos que se presumen contienen el
atributo. Esto equivale a decir que la escala debe ser invariable en sus propiedades, independientemente de los objetos de estÚmulos particulares usados
para determinarla.
En este respecto, las tÕcnicas manifiestas presentan una debilidad tangible. Efectivamente, esta es la esencia real de la posiciµn de
Helson y Michels, de que en condiciones de estÚmulo diferentes la misma respuesta manifiesta cambiarà aºn para los mismos estÚmulos. Por lo mismo, la
escala de sonoridad que obtenemos con la tÕcnica de fraccionamiento depende de los estÚmulos particulares que encuentra el sujeto (Michels y Doser, 1955, y
Garner, 1954b).
Por otra parte, Jones (1960) ha mostrado que el mÕtodo de
intervalos sucesivos (rangos normalizados de categorÚas) es invariable aun
cuando se usen estÚmulos concretos diferentes para establecer la escala. Comparµ
este mÕtodo con las tÕcnicas manifiestas de intervalo, pero su conclusiµn podrÚa
extenderse a otras del mismo tipo. Jones mostrµ ademÃs la invariabilidad de la
tÕcnica latente al hacer cambios en el continuo de respuesta empleado.
.- MÕtodo. En una secciµn anterior hicimos notar que debe
establecerse la generalidad con respecto a las respuestas, pero en forma mÃs
amplia requerimos generalidad con respecto al mÕtodo. Un mÕtodo particular
especifica por lo comºn una clase de respuestas,' y mientras podamos cambiar los
valores numÕricos efectivos dentro del mismo mÕtodo bÃsico, estaremos mÃs
interesados en la generalidad a travÕs de las clases de respuestas que solo a
travÕs de los diferentes valores numÕricos posibles.
Pero es mÃs importante que una escala psicolµgica sea
invariable con respecto a mÕtodos equivalentes lµgicamente, o que un mÕtodo
implique la posibilidad de otro. Cuando los sujetos pueden emitir juicios de
razµn, pueden entonces tambiÕn dar juicios de intervalo con respecto al mismo
atributo. Pero, como hemos visto, no obtenemos la misma escala psicolµgica
cuando se usan Õstas tÕcnicas diferentes. De hecho, esta dificultad ha conducido
a muchos investigadores a buscar la tÕcnica "correcta". Pero una escala que es
exclusiva de un mÕtodo particular se convierte en un concepto definido tan
estrecho que tiene poca utilidad general.
Garner (1958) ha sostenido, especÚficamente y por estas
razones, el uso de una escala latente de sonoridad basada en el criterio de
discriminabilidad, ya que el criterio implÚcito en la mayorÚa de las tÕcnicas
latentes conserva su generalidad de un mÕtodo a otro. Jones (1960) ha apoyado
este argumento en materiales de estÚmulo que no son de tipo psicofÚsico. En
efecto, las escalas psicolµgicas basadas en propiedades latentes de los datos se
corresponden mayormente con las escalas basadas en tÕcnicas manifiestas de
intervalo, y no asÚ con las basadas en tÕcnicas manifiestas de razµn.
Es por esto que la evidencia disponible indica que las
escalas latentes tienen mayor generalidad que las manifiestas, particularmente
las de esta clase que asumen la capacidad de los sujetos para usar propiedades
de razµn. La razµn de esto quizà sea en parte la observaciµn que hicimos
anteriormente de que las tÕcnicas latentes requieren suposiciones especiales;
pero el requerimiento de estas es bastante evidente para que la mayorÚa de los
investigadores se empeþen en establecer su validez.
Entonces, en el caso ideal, una escala debe poseer
generalidad en cuanto a tiempo, sujetos, objetos que reflejen el atributo, y
mÕtodo. Como indicamos al final, el problema de generalidad a travÕs de mÕtodos
diferentes es en la actualidad el obstÃculo mÃs grande para el desenvolvimiento
de la mediciµn por escalas psicolµgicas. Cuando seþalamos que los procedimientos
latentes parecen proporcionar mayor generalidad que las tÕcnicas manifiestas,
evadimos un problema muy real. No quisimos significar que las tÕcnicas tenÚan
mayor Õxito porque reflejaban procesos reales de las personas, que reflejaban
realmente las propiedades mÕtricas de los atributos. No querÚamos declararlo
porque no sabemos si la afirmaciµn es verdadera o no.
Desde un punto de vista ideal, la escala de mayor generalidad
es la que a la vez posee la mayor correspondencia con los atributos internos y
con los proceso mediatorios. Tal escala surgirÚa solamente de una teorÚa de la
forma en que las personas hacen juicios acerca de su experiencia, cuando se
aplica la teorÚa al procedimiento empleado para elaborar la escala. SerÚa
injusto decir que no existe semejante teorÚa; la suposiciµn de normalidad usada
en la mayorÚa de los procedimientos de elaboraciµn de escalas latentes es
realmente el primer paso hacia tal teorÚa. Öltimamente se han desarrollado
muchas teorÚas acerca del proceso de juicio; pero hasta la fecha poco es lo que
se ha hecho para aplicarlas a los problemas de construcciµn de escalas. Mientras
tanto, como hemos visto, se han desarrollado muchos procedimientos valiosos que
el psicµlogo puede emplear en la mediciµn de procesos psicolµgicos. BIBLIOGRAFIA LA SEGURIDAD EN AVIACIÆN: IMPORTANCIA DEL FACTOR HUMANO. XX
TÕcnicas de intervalo latente Existen muchas maneras lµgicas de construir escalas psicolµgicas con propiedades
intervalares, las cuales se basan en propiedades latentes de los datos; como
ejemplo tenemos la tÕcnica de despliegue de Coombs. Pero en el establecimiento
de escalas psicolµgicas todas las tÕcnicas se basan primordialmente en la
aceptaciµn de propiedades manifiestas ordinales, ademÃs de poseer propiedades
ordinales que se agregan despuÕs de una suposiciµn secundaria acerca de la
distribuciµn estadÚstica de los valores escalares. Y la suposiciµn comºn es que
los procesos psicolµgicos se distribuyen de acuerdo con la distribuciµn normal.
Hace mÃs de cien aþos, Fechner fue el primero en construir una escala
psicolµgica de intervalo basada en propiedades de intervalo latente de
intervalo. Integrµ las dan (jnd's) para obtener una escala de magnitudes
sensoriales, aplicando la suposiciµn de que todas las dan son iguales en cuanto
a sensaciµn. Este supuesto permitiµ construir una escala con propiedades de
intervalo. Thurstone (1927) extendiµ el
principio usado por Fechner para obtener una ley mucho mÃs general. En realidad
Fechner habÚa supuesto que las diferencias que se advierten con la misma
frecuencia constituyen diferencias psicolµgicas iguales, ya que una dan se
define como una proporciµn constante de juicios referentes a que un estÚmulo es
mÃs grande que otro. Pero Fechner no hizo ninguna suposiciµn acerca de la
distribuciµn de los juicios. La generalizaciµn de Thurstone consistiµ en suponer
que el proceso psicolµgico que conduce a juicios de diferencia està distribuido
normalmente. De esta suposiciµn puede deducirse la distancia psicolµgica si
conocemos la proporciµn de veces que un estÚmulo es seleccionado con respecto a
otro, pues hay una relaciµn invariable entre las probabilidades y las
desviaciones normales o puntuaciones estÃndar. AsÚ, si conocemos la proporciµn
de veces que A es preferido a B, podemos determinar la distancia entre A y B,
convirtiendo la proporciµn en la puntuaciµn estÃndar equivalente en las tablas
de la curva normal. Thurstone desarrollµ un modelo matemÃtico completo basado en
esta Ley del juicio comparativo (nombre que se dio a los supuestos de
normalidad intervalar), pero para nuestros propµsitos, el principio importante
es que pueden deducirse distancias psicolµgicas con propiedades de intervalo de
las proporciones de juicios ordinales.
AsÚ, en todas las tÕcnicas de intervalo latente, los datos manifiestos tienen
propiedades ordinales cuya validez se acepta. Aplicando el supuesto de la
distribuciµn normal de los juicios o procesos psicolµgicos se obtienen
propiedades intervalares en la escala psicolµgica. Las diferencias entre las
diversas tÕcnicas dependen de la naturaleza de los datos manifiestos.
Rangos normalizados. El procedimiento mÃs simple para obtener una escala
manifiesta ordinal Õs pedir a vÃrios sujetos que ordenen un conjunto de
estÚmulos. En los datos ilustrativos de la tabla 1 (v. marzo 07) pudimos sumar los rangos para
obtener el rango generalizado o promedio, pero seþalamos que los estÚmulos
debÚan volverse a ordenar para evitar la implicaciµn de que las diferencias
numÕricas desiguales entre sumas sucesivas tienen algºn significado intervalar.
El tamaþo de estas diferencias puede carecer de significado, porque solo se
hicieron juicios ordinales y no conocemos la distancia intervalar entre los
rangos sucesivos.
No obstante, si suponemos que los estÚmulos estÃn
distribuidos normalmente por valores escalares, entonces podemos construir una
escala de intervalo. El procedimiento que usamos es el siguiente: en nuestro
ejemplo tenÚamos cinco estÚmulos diferentes que habÚa que ordenar. Si estos
estÚmulos estÃn distribuidos normalmente, entonces nuestra mejor suposiciµn de
trabajo consiste en que cada estÚmulo ocupa 1/5 del continuo total de valores
posibles. En otras palabras, el estÚmulo con el rango mÃs bajo se encuentra
entre el 0 y el 20 % de la amplitud total de valores; el segundo estÚmulo estÃ
entre el 20 y el 40 %; el tercero entre el 40 y el 60 %; el cuarto entre el 60 y
el 80 %; y el quinto entre el 80 y el 100 %. No sabemos exactamente en dµnde se
encuentra cada estÚmulo, pero nuestra mejor estimaciµn es que està en medio de
su amplitud de valores posibles. Supongamos que el primer estÚmulo està en el
percentil 10, el segundo en el percentil 30 y asÚ sucesivamente hasta el ºltimo,
que està en el percentil 90. La puntuaciµn estÃndar equivalente de cada
percentil se determina despuÕs a partir de tablas normales y estos valores se
aceptan como nuestra mejor estimaciµn de los valores escalares de intervalo. Por
ejemplo, el rango normalizado de un rango de 1 es de + 1.28, que es la
desviaciµn normal equivalente de 0.90.
Los rangos de cada uno de los cuatro estimadores se dan como
rangos normalizados, y ahora podemos tomar justamente la media de estos rangos
normalizados, ya que son valores promedio con propiedades intervalares. Estos
rangos normalizados medios se dan en la parte inferior de la tabla.
Como la escala està formada tanto por nºmeros positivos como negativos, es
difÚcil interpretarla. A menudo los nºmeros son transformados como si todos
fueran positivos. En el ºltimo renglµn de la tabla se hizo esto y, ademÃs, se
multiplicaron por 10 para dispersarlos mÃs. En una escala de intervalo todo lo
que debemos conservar es el tamaþo relativo de las distancias entrÕ los valores
escalares; y esto es lo que se ha logrado con dicha transformaciµn. La escala
final se relaciona con la original por la fµrmula
Y= 1OX+ 11.925.
En nuestro ejemplo, pedimos a los sujetos que evaluaran ºnicamente cinco
objetos. Cuando se evalºan mÃs objetos, se sigue el mismo procedimiento, pero el
continuo total se divide en mayor nºmero de pasos. Esto significa que, por
ejemplo, si tuviÕramos 10 rangos, dividirÚamos la amplitud total en 10 partes
iguales, de 0 a 10, de 10 a 20, etc. Y los puntos medios de estas amplitudes, 5,
15, 25, etc., se usarÚan para determinar el valor equivalente de desviaciµn
normal. Por otra parte, la tÕcnica se usarÚa justamente como ya se ilustrµ.
Comparaciones normalizadas por pares. La segunda tÕcnica que estudiamos para
obtener escalas manifiestas ordinales fue la de comparaciones por pares, en la
que cada objeto es aparejado a todos los demÃs del conjunto. A un grupo de
sujetos se les pide que indiquen su preferencia por uno de los objetos de cada
par. Los datos obtenidos con esta tÕcnica se presentan en la tabla 2, (v. Marzo
2007) donde cada
celdilla indica la proporciµn de veces que cada pintura se prefiriµ a las demÃs.
Estos datos pueden usarse para construir una escala de intervalo con la
suposiciµn de normalizaciµn, si convertimos cada una de las proporciones en su
puntuaciµn estÃndar equivalente, y a partir de estas puntuaciones computamos las
distancias medias, en unidades de puntuaciones estÃndar, entre estÚmulos sucesivos.
Y aquÚ, como en el caso de los rangos normalizados, se aceptaron las propiedades
manifiestas ordinales de los datos.
TABLA 5
Estimadores Joe Bill Andy Jack Sam
Jefe .53 1.28 0 -.53 -1.28
* Cada anotaciµn es la puntuaciµn estÃndar equivalente del rango dado en la
Tabla 1. La escala transformada (Y) se relaciona con la escala original (X) por
la fµrmula Y = 10 X + 11.925. El fundamento de la
construcciµn de la escala es el siguiente: primero, consideremos cada columna de
la tabla 6. Los valores de la primera columna representan las puntuaciones de
desviaciµn normal cuando cada pintura se compara con la primera. Ya que la
pintura con la cual se compararon cada una de las siete pinturas de esa columna
es constante, entonces, con la suposiciµn normal-intervalar, los valores de esa
columna pueden usarse directamente como valores escalares de intervalo para
todas las pinturas. De manera totalmente arbitraria, se le asignµ a la primera
pintura -el estÃndar- un valor escalar de 0; y este procedimiento es por entero
correcto, ya que solamente construimos una escala con propiedades de intervalo,
y tal tipo de escala no tiene cero absoluto o verdadero.
Desde el punto de vista estrictamente lµgico, todo cuanto se necesita para
construir una escala latente de intervalo es una columna de datos de
comparaciµn. Sin embargo, podrÚamos usar tambiÕn cualquier columna en lugar de
la primera, porque en cada una de ellas se han comparado siete pinturas con una
sola estÃndar. En cada columna la escala que construyamos se asignarÚa, empero,
el valor de 0 a la pintura que se hubiera usado como estÃndar de comparaciµn.
Ahora bien, si los datos fueran perfectamente confiables y vÃlidas las
suposiciones que intervienen en una escala de intervalo, estas ocho escalas
serÚan exactamente iguales excepto por la posiciµn arbitraria del punto cero.
Desde que la posiciµn del valor cero es completamente arbitraria, podrÚamos
cambiar simplemente cada conjunto de valores escalares de manera que al mismo
estÚmulo se le diera el valor 0. Luego podrÚamos promediar los valores escalares
correspondientes a cada estÚmulo con el fin de obtener una escala mÃs general.
Hay, sin embargo, una dificultad importante en este sencillo procedimiento, que
se ilustra en la tabla 6, y es que cada columna -con las ocho pinturas
diferentes empleadas como estÃndares- no proporciona un valor escalar efectivo
para cada una de las ocho pinturas, puesto que en casos extremos una pintura se
escoge o se prefiere en funciµn de una o dos de las demÃs, todas o casi todas
las veces. En estos casos estÃn indeterminadas las puntuaciones estÃndar.
Tenemos asÚ ocho escalas diferentes en las ocho columnas; pero no a todos los
estÚmulos, dentro de cada columna, se les dan valores escalares.
TABLA 6
Comparaciones por pares normalizadas, usando los datos de la Tabla 2.
A B
C D
E F G
H
A
0 -.52 -1.08 -1.55
-1.55 - -
-
2.786 Las proporciones se tomaron como
estimaciones de la probabilidad de que cada pintura fuera preferida a cada una
de las demÃs, y los nºmeros que aquÚ se muestran son los equivalentes de
puntuaciµn estÃndar de estas probabilidades. A la derecha, se ve la distancia
media en unidades de puntuaciµn estÃndar entre las pinturas y la escala final,
donde se asignµ un valor de 0 a la pintura menos preferida. Lo que debemos
hacer es determinar la diferencia entre cada par de estÚmulos adyacentes
calculando la diferencia promedio de valor escalar en todas las escalas donde
las dos pinturas de un par tuvieron valores escalares. Por ejemplo, las dos
pinturas A y B tienen valores escalares en las cinco primeras columnas, de modo
que podemos obtener cinco estimaciones de la diferencia entre A y B usando los
valores escalares de estas cinco columnas. La diferencia promedio entre los
valores escalares es, en estas cinco columnas, 592 unidades de puntuaciµn
estÃndar. De manera
anÃloga, determinamos la diferencia promedio de valor escalar entre B y C,
usando las siete columnas donde hay valores escalares para estos estÚmulos, y
asÚ sucesivamente, hasta obtener las diferencias de valores escalares entre
todos los estÚmulos contiguos; y en cada caso la diferencia es la media de todas
las diferencias que se obtuvieron para ese par de estÚmulos. Estas diferencias
medias se presentan en el lado derecho de la tabla 6.
Los valores escalares finales se obtuvieron despuÕs suponiendo las diferencias
de valores escalares sucesivos presentadas en la ºltima columna de la tabla 6;
como en casos anteriores, podemos trasladar estos valores escalares para obtener
el punto 0 deseado. Podemos igualmente multiplicar los valores escalares; y
existen razones teµricas para multiplicarlos por, la raÚz cuadrada de 2. Sin
embargo, es tambiÕn correcto dejar los nºmeros en esta forma, ya que son
interpretables fÃcil y directamente en relaciµn con las proporciones originales
de las que se obtuvieron.
El mÕtodo de comparaciones por pares normalizadas, proporciona una prueba de
consistencia interna que no es factible con rangos normalizados. Se recordarÃ
que podÚamos considerar que cada columna de la tabla 6 proporcionaba una
estimaciµn de los valores escalares de todos los estÚmulos; pero despuÕs usamos
las diferencias escalares medias para obtener nuestro conjunto final de valores
escalares. Cada escala separada debe corresponder, sin embargo, a esta escala
promedio dentro del error de medida esperado, cuando se ajusta el punto 0 de la
escala. Si usamos la escala promedio para predecir cada escala separada, podemos
convertir los valores escalares en proporciones esperadas; y si estas
predicciones no corresponden, otra vez dentro del error de medida, debemos
rechazar la suposiciµn de que todos los valores escalares sean realmente
iguales. En tal caso existen muchos modelos alternos que podrÚan tambiÕn usarse.
El mÃs comºn es suponer que no son iguales las desviaciones estÃndar. En otras
palabras, mantenemos la suposiciµn de normalidad, pero no la de que la
distribuciµn normal de cada estÚmulo tiene la misma desviaciµn estÃndar; pero no
es nuestro propµsito entrar en detalle.
Rangos de categorÚa normalizados La tercera tÕcnica para obtener escalas
manifiestas -ordinales es la de rangos de categorÚa. Pueden aquÚ usarse los
datos para elaborar una escala latente- intervalar si le asignamos el supuesto
de normalidad. Los datos que usaremos son los de la tabla 3, que corresponden al
mÕtodo de rangos de categorÚa. Pueden, no obstante, usarse igualmente los datos
de los mÕtodos de intervalos aparentemente iguales, de categorÚas numÕricas o de
escalas de evaluaciµn, si suponemos que la ºnica propiedad manifiesta vÃlida de
los datos obtenidos es la propiedad ordinal.
Se han sugerido muchas tÕcnicas con diferentes nombres para elaborar escalas
intervalares latentes basadas en datos de categorÚas. Sin embargo, como seþala
Guilford (1954), todas son bÃsicamente iguales. Saffir (1937) fue el primero en
usar este mÕtodo, basÃndose en una tÕcnica desarrollada por Thurstone y lo
denominµ mÕtodo de categorÚas sucesivas. Guilford (1938) propuso otro mÕtodo al
que llamµ de elaboraciµn absoluta de escala. Attneave (1949) propuso lo que Õl
llamµ mÕtodo de dicotomÚas clasificadas por grados; y Garner y Hake (1951)
describieron un mÕtodo para construir una escala de discriminabilidad
equivalente. Pese a todo, estos mÕtodos aplican los mismos principios
esenciales, que dependen principalmente de la suposiciµn de normalidad para
crear una escala intervalar latente a partir de datos con propiedades
manifiestas-ordinales.
El primer paso para construir una escala intervalar latente se ilustra en la
misma tabla 3, donde el nºmero debajo de cada par en cada celdilla es la
proporciµn acumulativa de veces que cada estÚmulo fue clasificado en la
categorÚa dada o en una inferior. Estas proporciones acumulativas deben
considerarse, por consiguiente, como la proporciµn de juicios que caen por
debajo del lÚmite superior de cada rango de categorÚas. Naturalmente, todas las
proporciones acumulativas son iguales a 1.00 en los rangos categoriales mÃs
altos, ya que cada patrµn de estÚmulo recibiµ un rango de categorÚa de parte de
cada uno de los 20 jueces, y las proporciones deben sumar la unidad.
Podemos ahora suponer que estas proporciones estÃn distribuidas normalmente;
convirtamos, pues, las proporciones acumulativas en proporciones estÃndar con
las tablas de la curva normal. Estos valores, presentados en la tabla 7, son los
valores escalares psicolµgicos supuestos de los lÚmites superiores de las
categorÚas de respuesta, y el ºltimo rango de categorÚa (quinto) no tiene valor
porque la puntuaciµn de desviaciµn de la curva normal para una proporciµn de
1.00 està en mÃs infinito.
Tenemos, mientras tanto, un valor escalar para el lÚmite superior del intervalo
de cada rango de categorÚa excepto en los casos en que la proporciµn acumulativa
es 1.00 o un valor cercano. (Como es habitual no hemos usado valores
acumulativos mayores que .95 o menores que .05, debido a que el error
estadÚstico es muy grande en tales proporciones). Esto no obsta para considerar
que en cada lÚmite superior intervalar tambiÕn tenemos un valor escalar para
cada estÚmulo sucesivo. AsÚ cada renglµn nos proporciona un conjunto de valores
escalares de estÚmulo. Podemos obtener estimaciones de la diferencia escalar
promedio entre estÚmulos sucesivos en las columnas donde los estÚmulos de
cada par tienen valores efectivos, y podemos acumular estas diferencias promedio
para obtener una escala final dÕ los estÚmulos. Puede asignarse un valor de cero
a cualquier estÚmulo que escojamos. Este cÃlculo se ilustra en la tabla 7.
Patrones de estÚmulo CategorÚa
1 2 3 4 19 20 Se obtiene una prueba de la consistencia interna fundamentalmente de la misma
manera que en las comparaciones por pares normalizados. Podemos usar la escala
promedio para computar las diferencias entre los estÚmulos en los lÚmites
superiores intervalares y convertirlas despuÕs en proporciones acumulativas.
Luego podemos compararlas con las proporciones originales y decidir si estuvo
operando la misma escala psicolµgica para todos los estÚmulos. Si no es asÚ,
pueden usarse otros mÕtodos, especialmente los que suponen desviaciones estÃndar
desiguales.
TÕcnicas de proporciµn manifiesta
Cualquier tÕcnica basada en propiedades de razµn manifiesta de las respuestas de
un sujeto o de un evaluador, debe hacer las suposiciones paralelas de que el
atributo en cuestiµn tiene efectivamente propiedades de razµn y que los sujetos
pueden percibir y describir directamente estas propiedades. La propiedad de
razµn, requiere, especÚficamente, que el atributo tenga un cero absoluto, ya que
sin Õste una expresiµn de proporciµn carece totalmente de significado.
De ahÚ que las tÕcnicas manifiestas de razµn requieran en alguna forma que el
sujeto exprese una relaciµn entre dos o mÃs objetos estÚmulo en forma de
proporciµn. No es, de suyo, necesario que tales objetos sean lo que
ordinariamente llamamos estÚmulos, sino que pueden ser personas, si bien no deja
de ser cierto que las tÕcnicas de proporciµn se han usado rara vez con estas
ºltimas.
Elaboraciµn de razones. Probablemente la tÕcnica mÃs antigua de este tipo sea la
elaboraciµn de razones. El mÕtodo se ha llamado a menudo "fraccionamiento",
porque se le pide a un sujeto que elabore una magnitud de estÚmulo que sea una
fracciµn especificada de otro, pero como tambiÕn se le puede pedir que elabore
un estÚmulo que sea mºltiplo constante del otro, es preferible el tÕrmino mÃs
amplia de elaboraciµn de razones.
Como acabamos de seþalar, el procedimiento bÃsico consiste en darle al sujeto un
estÚmulo estÃndar que se presume tiene el atributo considerado y en pedirle
despuÕs que elabore otro estÚmulo que mantenga una razµn constante indicada con
el estÃndar. Este mÕtodo es, desde luego, semejante al de equisecciµn porque el
sujeto elabora un estÚmulo (podrÚa elaborar una serie de estÚmulos) que guarda
una relaciµn numÕrica indicada con un estÃndar. Como la equisecciµn, el mÕtodo
se adapta solamente a los atributos psicolµgicos que tienen una dimensiµn fÚsica
fÃcilmente manipulable que es la contraparte del atributo psicolµgico. La
sonoridad ha sido el atributo mÃs usado, y nosotros tambiÕn nos valdremos de
ella para ilustrar el mÕtodo.
En su forma mÃs simple, empezarÚamos con un estÚmulo sonoro como estÃndar y
pedirÚamos a un sujeto que produjera un estÚmulo con la mitad de sonoridad. Si
asignamos arbitrariamente un numeral, por ejemplo 100, al estÃndar, entonces se
asignarÚa el numeral 50 al estÚmulo que segºn el sujeto fuese la mitad de
sonoro. DespuÕs usarÚamos ese estÚmulo como estÃndar y pedirÚamos al sujeto que
produjera otro que fuera la mitad de sonoro de ese, y le asignarÚamos el numeral
25. Continuando este fraccionamiento, obtendrÚamos sucesivamente una sonoridad
de 12.5, 6.25, etc.
En realidad, este sencillo procedimiento se usa rara vez debido a las posibles
desviaciones experimentales que pueden ocurrir con la disminuciµn sucesiva de
sonoridad. El procedimiento usual, consiste en usar
una serie de estÃndares fijos, por ejemplo, cada uno de 10 db. DespuÕs cada
sujeto ajusta otro estÚmulo de la mitad de sonoridad de cada estÃndar. Los
estÚmulos estÃndar se usan al azar o contrabalanceadamente, y los diferentes
sujetos pueden producir varias veces cada estÃndar. Estos valores diversos se
promedian despuÕs para obtener una curva promedio que exprese 12 relaciµn entre
la intensidad del estÃndar y la intensidad considerada como la mitad de sonora.
Luego se construyµ la escala psicolµgica de sonoridad, por medio de
interpolaciones, para obtener las intensidades sucesivas de la mitad de
sonoridad. Podemos asignar arbitrariamente, por ejemplo, un valor de 100 a una
intensidad de 110 db y luego leer en la funciµn la intensidad que se juzga, en
promedio, como la mitad de su sonoridad. A esta intensidad se le asigna un valor
escalar de 50 y despuÕs se determina, por interpolaciµn, la intensidad que se
considerµ como la mitad de la sonoridad de Õsta. A esa intensidad se le da un
valor de 25 y despuÕs se usa para determinar la intensidad que se juzgµ como la
mitad de sonora, etc., hasta llegar a intensidades tan bajas como las usadas
experimentalmente.
Los tipos de prueba de consistencia que permite este procedimiento se refieren
bÃsicamente a la capacidad de los sujetos para usar correctamente las razones de
nºmeros. Por ejemplo, podÚamos realizar exactamente este experimento excepto al
pedÚrsele al sujeto quÕ produjera un estÚmulo el doble de sonoro; o que
produjera estÚmulos de un tercio de sonoridad o aun del triple de sonoridad.
Cada uno de estos procedimientos debe conducir ciertamente a la misma escala de
sonoridad si se usan los nºmeros correctamente.
Estimaciµn de magnitud. En la tÕcnica de producciµn de razones, se le da
al sujeto un valor numÕrico y se le pide que ajuste los estÚmulos hasta
satisfacer el criterio. En la estimaciµn de magnitud, como en las tÕcnicas de
propiedades manifiestas intervalares de intervalos aparentemente iguales, de
escalas de categorÚas numÕricas y de escalas de estimaciµn, se proporcionan los
estÚmulos y se pide al sujeto que indique, en este caso siempre numÕricamente,
las relaciones entre esos estÚmulos.
De entre los procedimientos de estimaciµn de magnitud hay dos que pueden usarse.
- El primero consiste sencillamente en presentar un estÚmulo por vez y pedirle al
sujeto que indique su valor numÕrico usando cualquier mµdulo o unidad de medida.
Este es un procedimiento de estimaciµn numÕrica directa y los valores escalares
son simplemente los valores numÕricos medios obtenidos. Las propiedades de razµn
de la escala dependen completamente de la suposiciµn de que las propiedades de
razµn fueron efectivamente usadas por los sujetos.
- El segundo procedimiento consiste en presentar un estÚmulo estÃndar
asignÃndole de antemano un valor numÕrico, que se convierte en el mµdulo o
unidad de medida. Se presentan despuÕs otros estÚmulos y se pide al sujeto que
indique el valor numÕrico que debe asignarle a cada uno de acuerdo con el mµdulo
estÃndar. Este puede presentarse cada vez que se proponga otro estÚmulo de
comparaciµn, o bien puede presentarse sµlo ocasionalmente.
Para una prueba de consistencia interna, es preferible usar por lo menos dos
estÚmulos estÃndar diferentes, ya sea de igual o diferente mµdulo numÕrico. En
la tabla 8 aparecen algunos datos ilustrativos de un experimento en que se
usaron dos estÚmulos estÃndar diferentes, cada uno con el mismo mµdulo numÕrico.
Los estÚmulos consistieron en pesos que el sujeto levantaba. Los valores que se
incluyen son los valores numÕricos medios dados por los sujetos a cada uno de
los pesos. Cada uno
de estos dos conjuntos de datos puede usarse para construir una escala
psicolµgica de peso; tambiÕn podemos convertirlos al mismo mµdulo numÕrico para
construir una sola escala compuesta. Multiplicamos (o dividimos) sencillamente
todos los nºmeros obtenidos con el segundo estÃndar de manera que el valor
numÕrico de este corresponda a su valor cuando es juzgado en relaciµn con el
primer estÃndar. Una escala de razµn permite cualquier transformaciµn
multiplicativa, asÚ que este cambio es completamente vÃlido. AdviÕrtase, sin
embargo, que no debemos agregar o sumar una constante a ninguna de las escalas,
porque en las escalas de razµn no està permitida tal transformaciµn. Si
tuviÕramos que hacerlo para que concordaran las dos escalas comprobarÚamos que
no se usaron los nºmeros como razones.
Estas dos escalas, transformadas al mismo mµdulo numÕrico, son las que aparecen
en la figura 6, y en nuestro ejemplo particular concuerdan perfectamente.
- El mÕtodo de suma constante. Metfessel (1947) sugiriµ una tercera
tÕcnica para obtener escalas de razµn, la cual ha venido a llamarse mÕtodo de
suma constante. Es anÃloga al mÕtodo de comparaciµn por pares excepto en que los
sujetos formulan juicios de razµn, y no ordinales.
En la situaciµn experimental tenemos un nºmero fijo de estÚmulos para los que
deseamos hacer una escala relacionada con cierto atributo, y puesto que los
estÚmulos permanecen constantes, no es necesario que haya una dimensiµn fÚsica
correspondiente a dicho atributo. Cada estÚmulo es apareado con cada uno de los
demÃs para formar todos los pares posibles. DespuÕs se presentan los pares en
forma sucesiva al sujeto y se le pide a Õste que asigne valores numÕricos a los
dos objetos de estÚmulo del par. Hay en esta asignaciµn numÕrica la restricciµn
de que la suma de los dos nºmeros usados debe ser igual a una constante,
generalmente de 100, fijada por el experimentador. AsÚ, por ejemplo, un sujeto
puede decir que el estÚmulo A recibe un valor de 60 y el B un valor de 40. Ahora
bien, si un sujeto puede dividir una suma fija de esta manera, ello implica que
puede formar razones y podemos deducir que la razµn numÕrica entre los valores escalares de los estÚmulos A y B es de 1.5 a 1. El sujeto puede hacer uno y
hasta varios juicios para cada par. Se usan, ademÃs, varios sujetos para dar generalidad a la escala.
Existen formas alternas de tratar los datos y es posible usarlos en su forma numÕrica directa. Sin embargo, Torgerson (1958), ha indicado un procedimiento de
gran sencillez aritmÕtica y que conserva el fundamento del procedimiento, muy semejante al tratamiento de datos de comparaciones por pares normalizados.
La esencia del procedimiento consiste en la relaciµn entre logaritmos v razones. Si tomamos logaritmos de los valores numÕricos de una escala de razµn, entonces
las diferencias logarÚtmicas iguales son equivalentes a las que fueron originalmente razones iguales, AsÚ, una serie de valores numÕricos sobre una
escala de razµn de 1, 2, 4, 8 y 16 se convierte en los logaritmos 0, .3, .6, .9 y 1.2. Por tanto, si convertimos en logaritmos nuestros numerales de razµn
obtenidos de los datos, podemos tratar con nºmeros donde una diferencia constante siempre significa una razµn constante, independientemente de los
valores reales de los nºmeros originales. Nuestro procedimiento consiste, entonces, en tomar un par de nºmeros que da un
sujeto, expresarlos como una sola razµn y luego convertir esta razµn en su logaritmo equivalente. Los valores de 60 y 40 asignados a A y B se expresarÃn,
consecuentemente, como una razµn de 1.5 a 1, con su logaritmo equivalente de 0.176. Y tendremos asÚ que este valor representa la diferencia logarÚtmica entre
A y B, que es equivalente a la razµn. En cada pareja de estÚmulos obtenemos la media de todas las diferencias logarÚtmicas, que se colocan en una tabla semejante a la tabla 9. En la diagonal
principal aparece el valor de cero porque se supone que, si cada estÚmulo fuera comparado consigo mismo, se obtendrÚan valores de 50 y 50, que darÚan una razµn
de 1.0 y un logaritmo de 0. Esta tabla puede interpretarse exactamente de la misma manera que la tabla 6.
Cada columna de la tabla da una escala psicolµgica perfectamente vÃlida, en la que todos los estÚmulos se han comparado con un solo estÃndar; pero este es
diferente en cada columna. Excepto por el error de medida estas escalas son iguales, aunque el punto cero sea diferente en cada una debido al diferente
estÚmulo estÃndar usado. Es entonces una escala de intervalo en forma logarÚtmica. Un cambio en el punto cero equivale aquÚ a la multiplicaciµn por una constante.
El mÕtodo de suma constante*
Bill Joe Andy Jack Sam Para obtener una escala promedio, podemos calcular, precisamente como en las comparaciones por pares normalizados, la diferencia promedio entre los valores
escalares de todos los pares de estÚmulos, independientemente del estÃndar. Si algunos estÚmulos recibieron los 100 puntos cuando se compararon con otros,
entonces no tenemos ninguna diferencia escalar, porque la razµn es infinita. Obtenemos asÚ el promedio sµlo para diferencias reales de pares; despuÕs
agregamos estas diferencias para obtener la escala completa en forma logarÚtmica. Todo lo que se requiere es convertir estos valores a forma
numÕrica. Podemos, claro estÃ, multiplicar estos nºmeros por el valor constante que queramos.
Nuestra prueba de consistencia interna se basa en el hecho de que cada estÚmulo se usµ tanto de estÃndar como de comparaciµn para cada uno de los demÃs
estÚmulos. En otras palabras, cada estÚmulo sirve de mµdulo, y un cambio en Õste no debe afectar la escala, excepto en el caso de un multiplicador constante.
Cuando las escalas no son iguales, sabemos de inmediato que no es vÃlida nuestra suposiciµn de propiedades de razµn.
Una tÕcnica de razµn latente Una escala con propiedades de mediciµn mÃs eficaces abarca todas las propiedades
de la escala mÃs dÕbil. AsÚ, una escala de intervalo tiene tambiÕn la propiedad ordinal y una escala de razµn tiene propiedades intervalares ademÃs de las
ordinales. Este hecho indica que un procedimiento lµgico para comprobar la consistencia interna de una escala es mostrar que la escala obtenida es
compatible con las propiedades de una escala de orden inferior. Para ser mÃs especÚficos, supongamos que hemos elaborado una escala de sonoridad mediante una
de las tres tÕcnicas manifiestas de razµn. Es muy posible obtener una escala que sea consistente dentro de la estructura de la mediciµn, pero puede no ser
compatible con las propiedades de una escala obtenida mediante una tÕcnica manifiesta intervalar o latente intervalar. Como existen diferencias importantes
entre estas tÕcnicas, particularmente cuando se emplean procedimientos latentes, no siempre podemos esperar consistencia entre ellas; y en algºn grado dicha
falta de consistencia puede justificarse por las suposiciones fundamentalmente diferentes que intervienen.
Esto no impide que muchas de las tÕcnicas manifiestas sean bÃsicamente iguales y se apliquen a problemas de escalas intervalares o de razµn con la ºnica
diferencia de la capacidad asignada al sujeto para hacer uso de escalas con propiedades superiores (pero inclusivas). Por tanto, la tÕcnica de producciµn de
razµn es exactamente igual a la tÕcnica de equisecciµn, excepto en que en Õsta se indica al sujeto que produzca intervalos iguales, mientras que en la primera
se le pide que produzca una razµn dada. De manera similar, la tÕcnica de estimaciµn de magnitud es igual a las tÕcnicas de categorÚas numÕricas (y aºn al
mÕtodo de intervalos aparentemente iguales o escalas de estimaciµn). En estos casos de tÕcnicas anÃlogas serÚa razonable suponer que una escala
basada en la tÕcnica de razµn puede predecir exactamente la escala basada en su tÕcnica intervalar equivalente. Sin embargo, es raro que estos procedimientos
anÃlogos conduzcan a la misma escala psicolµgica (vÕase Stevens y Galanter, 1957), hecho que debe plantear seria duda acerca de la validez de los
procedimientos manifiestos. Cuando suceden estas fallas de concordancia, no sabemos, positivamente, quÕ tÕcnica es defectuosa o cuÃl de ellas es vÃlida.
Pero a pesar de lo anterior y como Stevens (1951) lo ha mostrado lµgicamente, es posible producir una escala con propiedades de razµn que no requiera las mismas
suposiciones radicales acerca de las propiedades manifiestas de las respuestas que exigen las tÕcnicas manifiestas de razµn. Una escala de razµn puede
elaborarse entonces con base en propiedades latentes de los datos. L =abx donde L es la funciµn verdadera de sonoridad, a es cierta unidad arbitraria de
medida, b el valor de la razµn desconocida y x el valor de la razµn sucesiva. Podemos asignar a a el valor que queramos, de manera que sµlo quede un valor
desconocido en el segundo miembro de esta ecuaciµn. A partir de los datos del experimento de equiseccion, podemos tambiÕn
determinar la funciµn de sonoridad, pero no conocemos el valor de la constante de intersecciµn, es decir la localizaciµn del punto cero. En forma de ecuaciµn
sabemos que L=c(Y-d) donde L tiene el mismo significado que arriba, c es una unidad arbitraria de
medida, Y es el valor asignado a la sonoridad de los datos intervalares, y d es la intersecciµn constante desconocida.
En realidad solamente tenemos dos tÕrminos desconocidos, el valor de la razµn del experimento de fraccionamiento y el valor de la
intersecciµn de los datos de equisecciµn. Pero contamos con dos conjuntos de datos independientes y, por tanto, podemos calcular estos dos valores
desconocidos de manera que se llegue a la misma escala de sonoridad. No es necesario entrar aquÚ en los detalles del procedimiento aritmÕtico usado para
determinar las estimaciones, pues lo mÃs importante es que estas satisfagan la condiciµn de una sola funciµn de sonoridad. En consecuencia, este procedimiento,
como las tÕcnicas de Guttman y Coombs, tiene por requisito principal la prueba de la consistencia interna; y no es posible escala psicolµgica alguna sin que
antes la prueba de consistencia interna haya mostrado la validez del supuesto atributo. Ha habido relativamente pocos intentos por usar las tÕcnicas latentes
para elaborar escalas de razµn de atributos psicolµgicos. Michels (1954) publicµ una escala de brillantez basada en juicios de fraccionamiento y Michels y Doser
(1955) hicieron lo propio con una escala de sonoridad. Pero sus tÕcnicas, que discutiremos con mayor amplitud mÃs adelante, estÃn mÃs relacionadas con la
teorizaciµn acerca de la naturaleza de las escalas mismas que con el desarrollo de un mÕtodo para elaborarlas.
Otras tÕcnicas de mediciµn El problema de mediciµn en psicologÚa es ubicuo. El anÃlisis
de las tÕcnicas para elaborar escalas psicolµgicas requiere considerable selecciµn arbitraria, toda vez que los problemas de mediciµn lµgica asociados
con lo que hemos llamado elaboraciµn de escalas presÕntanse tambiÕn en otras ramas de la psicologÚa. Los psicµlogos miden cosas tales como inteligencia,
habilidades, destrezas, actitudes, intereses, etc. Todo este cºmulo dÕ entidades puede considerarse problemÃtico en la mediciµn de atributos, no obstante la
existencia de algunas diferencias que nos llevan a excluirlas de nuestro anÃlisis. Hemos estudiado problemas donde hay poca duda respecto a la
existencia de cierto atributo psicolµgico. Nuestro interÕs ha sido el de cµmo determinar las propiedades escalares de un atributo, para obtener despuÕs un
conjunto de numerales para asignarlos a los objetos que contengan, en mayor o menor grado, el atributo. AdemÃs, nos hemos limitado a los casos donde el
atributo puede definirse como un solo continuo. No hemos analizado la mediciµn de cosas como inteligencia y
habilidad porque se definen comºnmente en tÕrminos de tareas mºltiples en donde la medida no pretende tener propiedades escalares asignables a un atributo. Por
ejemplo, el examen final de un curso de psicologÚa tendrà muchos reactivos y la calificaciµn final serà la suma de los reactivos correctos. Pero no todos los
reactivos miden el mismo atributo y, en realidad, la mayorÚa de los exÃmenes se elaboran de manera que no lo midan, incluyÕndose deliberadamente reactivos que
no estÃn correlacionados. Tales tests hacen los problemas de mediciµn no menos difÚciles e intricados; pero son, simplemente, de distinta clase.
Por otra parte, muchas tÕcnicas de mediciµn extremadamente sutiles se interesan principalmente por establecer la existencia de continuos
subyacentes o atributos. Por ejemplo, el anÃlisis factorial, como tÕcnica, se interesa menos en las propiedades de mediciµn de un atributo que en descubrir
cuantos de estos se presentan en un numero dado de personas y de tests. La tÕcnica de Lazarsfeld, de anÃlisis de estructura latente, tambiÕn se ha omitido
por esta razµn (quizÃs incorrectamente) dado que se ocupa mas de establecer la existencia de atributos que de medir sus cantidades.
LA SEGURIDAD EN AVIACIÆN: IMPORTANCIA DEL FACTOR HUMANO. XIX ALGUNAS TèCNICAS DE CONSTRUCCIÆN DE ESCALAS
Cada problema que se presenta al hacer escalas fija distintos requisitos de tÕcnica; esta es la razµn por la que se han desarrollado distintas tÕcnicas de
elaboraciµn. Muchas diferencias de tÕcnica se deben a diferencias en los atributos o en los objetos que se van a medir por medio de escalas. Estas
diferencias dificultan la agrupaciµn significativa de las diferentes tÕcnicas. Debemos encontrar maneras de organizar las tÕcnicas para presentar un cuadro
claro. PodrÚamos organizarlas segºn la naturaleza del atributo, segºn la naturaleza de los objetos que se van a medir y hasta por la naturaleza de la
respuesta usada. Pero estos mÕtodos no tienen en cuenta los aspectos conexos mÃs importantes de una escala psicolµgica, a saber, cuÃles son sus propiedades de
mediciµn y cµmo se relaciona la escala con el atributo subyacente. Se han organizado, por tanto, las tÕcnicas segºn estos dos criterios importantes:
primero, las propiedades de mediciµn de la escala, y segundo, si la escala se basa fundamentalmente en propiedades latentes o manifiestas de los datos. Para
describir los tipos de escalas, se emplean tÕrminos como "intervalo-manifiesto", que significa que la escala obtenida tiene propiedades
de intervalo y que estas propiedades eran inherentes a la respuesta manifiesta. Consistencia interna de las escalas.
Antes de describir las tÕcnicas concretas, es conveniente hacer otro comentario acerca de los problemas experimentales de la elaboraciµn de escalas psicolµgicas. Una buena
tÕcnica experimental requiere la comprobaciµn de la consistencia interna de los datos. El concepto de consistencia interna es importante y con frecuencia nos
referiremos a Õl. BÃsicamente se refiere a la validez de un procedimiento particular de elaboraciµn de escalas o a la validez de la suposiciµn de que se
puede hacer una escala para un atributo particular con las propiedades de la escala especificada.
La esencia del concepto es: si una escala tiene las propiedades supuestas, y si la tÕcnica particular de su elaboraciµn es vÃlida para determinar estas
propiedades, entonces los resultados experimentales deben presentar ciertas relaciones internas compatibles con las propiedades que se le adjudican.
Supongamos, por ejemplo, que tratamos de establecer una escala ordinal para tres objetos, A, B y C. Si un gran nºmero de sujetos concuerda en que A es mÃs grande
que B y B es mÃs grande que C, entonces tambiÕn deben coincidir en que A es mÃs grande que C, para que estos datos tengan consistencia interna. Si en lugar de
esto, todos concuerdan en que C es mÃs grande que A, entonces tendremos un resultado confiable (confiable debido al acuerdo intersujeto); pero pondrÚamos
en duda la legitimidad de la escala debido a la falta de consistencia interna. Otro ejemplo, supongamos que hemos encontrado experimentalmente que A es dos
veces mayor que B y que B es dos veces mayor que C. Entonces, nuestro procedimiento experimental tambiÕn debe indicar que A es cuatro veces mayor que
C. Si no sucede asÚ, entonces rechazamos la suposiciµn de que se haya logrado la escala de razµn adecuada.
Aunque un conjunto de datos carezca de consistencia interna, no siempre estaremos seguros del por quÕ. Es posible que sea errµnea la suposiciµn de la
existencia de una escala con las propiedades especificadas. O es posible que nuestra tÕcnica experimental sea inadecuada para determinar dicha escala. Si los
datos no tienen consistencia interna, a menudo se ensaya otra tÕcnica para determinar si la tÕcnica original es defectuosa y no la suposiciµn acerca de las
propiedades del atributo mismo. Muchos procedimientos de elaboraciµn de escalas contienen comprobaciones de la
consistencia interna como parte integral de la tÕcnica misma. En particular, las tÕcnicas latentes a menudo contienen y aºn hacen hincapiÕ en tales
comprobaciones debido a la importancia de la suposiciµn de mensurabilidad por escala en estas tÕcnicas. Con las tÕcnicas manifiestas, estas comprobaciones
pueden y deben hacerse; pero ordinariamente implican realizar mÃs de un experimento. TÕcnicas manifiestas ordinales
La propiedad ordinal de las escalas psicolµgicas es de aceptaciµn tan comºn que todas las escalas que solo tienen propiedades ordinales se basan en datos
manifiestos. En otras palabras, las tÕcnicas latentes no se usan por lo comºn para obtener escalas ordinales porque la mayorÚa de los experimentadores
consideran que el sujeto promedio es capaz para hacer juicios ordinales. Ordenaciµn por rangos. Probablemente la mÃs sencilla de todas las
tÕcnicas de elaboraciµn de escalas es la ordenaciµn jerÃrquica simple. Se presenta a un sujeto un conjunto de estÚmulos para que juzgue, por ejemplo, su
valor estÕtico; o a un supervisor se le pide que ordene a los empleados supervisados por Õl; o se le pide a un sujeto que juzgue la brillantez de varios
estÚmulos grises. En cada caso, si el nºmero de objetos que se van a ordenar es relativamente pequeþo, se pide simplemente al sujeto que ponga los objetos en
orden de rango o que asigne un nºmero de orden a cada objeto. Estos nºmeros se consideran despuÕs como valores escalares. Con el fin de proporcionar alguna
generalidad a la escala y con ello ofrecer alguna comprobaciµn de la validez de la suposiciµn de que existe un atributo mensurable por escala, puede pedirse a
varios sujetos o estimadores que ordenen los mismos objetos. Los datos de la tabla 1 presentan las posiciones de un ejemplo hipotÕtico donde cuatro
estimadores apreciaron cada uno a cinco trabajadores. Los nºmeros de orden se pueden sumar para ofrecer una escala de rangos compuestos, o se pueden calcular
promedios para cada trabajador, obteniÕndose de tal modo un rango promedio. Sin embargo, debe estar claro que estos rangos promedio, con sus intervalos
numÕricos desiguales entre los estÚmulos, no dan propiedades escalares superiores a las de las escalas ordinales. Para evitar cualquier interpretaciµn
errµnea del significado de estos rangos promedio, es conveniente reasignar nºmeros enteros de rango a los objetos, como se ha hecho en la tabla l.
Comparaciones por pares. Cuando tenemos un nºmero relativamente pequeþo de
objetos para ser colocados en orden, puede usarse una tÕcnica ligeramente menos elaborada, que suministra una comprobaciµn mejor de la consistencia interna de
las suposiciones ordinales. En esta tÕcnica, los objetos, por ejemplo, diez, se agrupan en todas las parejas posibles (con diez objetos podemos hacer 45
parejas); despuÕs se presentan estas parejas, una a la vez, y se le pide al sujeto que diga cuÃl estÚmulo tiene mayor proporciµn del atributo, o quÕ
persona, por ejemplo, es mÃs diestra como maquinista. AsÚ, con esta tÕcnica, en lugar de que cada sujeto ordene los diez objetos a la vez, ordena dos objetos en
cada una de las 45 parejas. La ventaja de esta tÕcnica es que suministra una comprobaciµn de la capacidad de
los sujetos para ordenar los estÚmulos, porque si todos los objetos tienen realmente un orden consistente para el sujeto, entonces muchos de los juicios
sobre los pares son predecibles a partir de otros. Por ejemplo, supongamos que un sujeto escoge a A como mÃs grande que B y luego escoge a B como mÃs grande
que C. Entonces es claro que tambiÕn debe escoger a A como mÃs grande que C, y si falla con mÃs frecuencia de la predecible atribuyÕndola al azar o al error,
rechazarÚamos la suposiciµn de que pueden ordenarse los sujetos con respecto al atributo especificado. La tabla 2 presenta un conjunto de datos hipotÕticos resultantes de un
experimento de comparaciµn por pares, expuestos en la forma usual. En esta tabla se enumeran los estÚmulos en la parte superior y a un lado, y cada celdilla
representa un solo par juzgado. El valor en una celdilla de la tabla indica la proporciµn de veces (de todos los sujetos que hacen las selecciones) que el
estÚmulo mencionado arriba fue preferido al estÚmulo indicado al lado. En el ejemplo, se pidiµ a 50 sujetos que seleccionaran entre pares de pinturas basÃndose en sus preferencias estÕticas.
En esta ilustraciµn, la pintura "A" fue preferida a la "B" por 35 de los 50 sujetos en una proporciµn de 70. Todos los sujetos prefirieron ademÃs la pintura
"A" a la pintura "H".
En este tipo de experimento, de ordenaciµn simple, los datos de un solo sujeto podrÚan darnos los valores de rango de los objetos si sus selecciones por pareja
tuvieran consistencia interna. Sin embargo, podemos obtener mayor generalidad combinando las respuestas de los sujetos, como hemos hecho en el ejemplo. Con
solo sumar el nºmero total (o proporciµn) de veces que cada objeto es seleccionado cuando se iguala con cada uno de los demÃs, tenemos una escala de
rangos promedio. Y nuevamente, como en la ordenaciµn jerÃrquica, asignaremos a los estÚmulos nºmeros enteros de rango, ya que las diferencias entre los nºmeros
de selecciones no reflejan necesariamente diferencias en los intervalos entre los objetos. De esta manera tenemos aºn una escala ordinal, basada en las
propiedades manifiestas ordinales de los juicios. Rangos de categorÚa. Tanto las tÕcnicas de ordenaciµn como la de comparaciones
por pares son factibles solamente cuando se va a establecer una escala para un nºmero relativamente pequeþo de objetos. Ya con unos 20 objetos se dificulta la
ordenaciµn, y la comparaciµn por pares (190, en este caso) es prohibitiva Debemos entonces recurrir a una tÕcnica modificada de ordenaciµn. En la tÕcnica
de categorÚas de rango, se usan menos categorÚas de Õste que el nºmero de objetos que se van a juzgar. Por ejemplo, tenemos 60 estructuras diferentes de
estÚmulos que se van a juzgar por su calidad, pero pedimos a los jueces que usen solo cinco categorÚas diferentes de respuesta, y ºnicamente como rangos. En
nuestro ejemplo de la tabla 3, hay solo cinco categorÚas de rango, donde el rango "1 " significa las mejores estructuras, y el rango "5" las estructuras
mÃs pobres. En esta tÕcnica cada categorÚa de rango se usa con muchos
estÚmulos diferentes, pero los diferentes sujetos o jueces no asignan los rangos a los objetos estÚmulo de la misma manera exactamente. AsÚ, cada estÚmulo tendrÃ
una distribuciµn de categorÚas de rango. En esta distribuciµn podemos computar un rango medio como lo hicimos en la tabla 3, pero esto es discutible porque las
categorÚas de rango no tienen propiedades de intervalo. Un procedimiento mejor, que tambiÕn se presenta en la tabla 3, es calcular la mediana de los rangos
asignados a cada estÚmulo, por interpolaciµn en la distribuciµn acumulativa de frecuencias; estas medianas de rango se presentan en la tabla.
Vemos otra vez que la reasignaciµn de nºmeros enteros de rango a los estÚmulos es adecuada, habida cuenta de que las diferencias en
mediana de rango no indican propiedades intervalares del atributo en cuestiµn. AnÃlisis de escalograma de Guttman. Existen dos
tÕcnicas de elaboraciµn de escalas que conducen a escalas ordinales que dependan en algºn grado de las propiedades latentes de los datos. Una es la tÕcnica de
escalograma de Guttman (1950), que produce una escala en la que puede colocarse tanto a los objetos estÚmulo (generalmente reactivos de test) como a los
sujetos. Lo fundamental de la tÕcnica es determinar la validez de la suposiciµn ordinal con respecto a un atributo. Guttman sostiene que a menos que pueda
demostrarse que tanto los objetos como los sujetos pueden ordenarse con respecto a un solo atributo, no existe fundamento para intentar la elaboraciµn de una
escala ordinal. Esta tÕcnica es mÃs adecuada con atributos tales como capacidades, donde puede suponerse que tanto los estÚmulos como los sujetos
muestran el atributo. La tÕcnica de Guttman ha alcanzado caracteres en extremo sutiles, describimos sµlo lo suficiente para presentar los principios bÃsicos que
utiliza. Los tipos, de reactivos de estimulo que se usan en una escala de Guttman son por lo comºn los que pueden contestarse en forma dicotµmica: aceptar o rechazar,
correcto o equivocado, etc. La principal limitaciµn que impone esta tÕcnica es que solamente deben usarse reactivos que puedan ordenarse en forma consistente
con respecto a preferencia o capacidad y tambiÕn que los sujetos puedan ordenarse en forma consistente con respecto a los reactivos. El ejemplo que
hemos seleccionado se presenta en la tabla 4 y consiste en cinco preguntas de aritmÕtica. Estos reactivos escogidos corresponden a un nivel
creciente de dificultad, pues el problema de la adiciµn simple es mÃs fÃcil que el problema de la adiciµn de nºmeros con dos dÚgitos, y asÚ sucesivamente. Si
estos reactivos representan efectivamente un continuo de un solo atributo, entonces los sujetos deben contestar correctamente todos los problemas mÃs
fÃciles que el mÃs difÚcil que resolvieron, y deben fallar en todos los problemas mÃs difÚciles que el mÃs fÃcil en que fallaron. AsÚ, el sujeto que
contestµ correctamente el ºltimo reactivo debe haber contestado correctamente todos los demÃs; y el sujeto que fallµ en el primero debe haber fallado en todos
los demÃs, porque son mÃs difÚciles.
Este requerimiento, de ordenaciµn perfecta de los objetos de estÚmulo, significa que existen sµlo seis puntuaciones posibles y cada puntuaciµn representa un solo
tipo de escala de sujeto. Por supuesto, las seis puntuaciones posibles son los nºmeros desde el "0" hasta el "5", y cada nºmero se asocia ºnicamente a un
patrµn particular de respuestas correctas y errµneas. AsÚ, un "3" significa que estos sujetos acertaron en el tercer reactivo y en todos los demÃs menos
difÚciles, pero que fallaron en los ºltimos dos reactivos. Existen naturalmente muchas dificultades para establecer semejante escala con
reactivos mÃs realistas y con reactivos que no se contesten en forma dicotµmica; tales problemas se discuten en la obra de Stouffer y colaboradores (1950). Pero
el concepto bÃsico de esta tÕcnica no es difÚcil y tiene interÕs por su Õnfasis en la prueba de consistencia interna como requisito fundamental que debe
satisfacerse. Hemos advertido que la mayorÚa de las tÕcnicas de elaboraciµn de escalas disponen de alguna forma de prueba de consistencia interna que forma
parte de ellas; pero ninguna establece tan cabalmente la validez de la suposiciµn fundamental que interviene en todo problema de dicha elaboraciµn, a
saber, que existe realmente un atributo con las propiedades de mediciµn adjudicadas o expresadas. Muy a menudo esta suposiciµn sigue siendo eso, una
suposiciµn, con escasa prueba de su validez. TÕcnica de despliegue de Coombs. Coombs (1950) ha descrito una tÕcnica
para elaborar escalas que tambiÕn ubica a los objetos estÚmulo y a los sujetos en el mismo atributo. Su tÕcnica hace uso directo de la ordenaciµn por parte de
los sujetos y en este respecto se basa en las propiedades manifiestas de los datos. Pero esta tÕcnica, tambiÕn permite, con datos suficientes, la
determinaciµn de una ordenaciµn de los intervalos, que conduce a lo que Coombs llama un tipo de escala mÕtrica ordenada, intermedia entre las escalas con
propiedades ordinales y las escalas con propiedades intervalares. La mejor manera de explicar la tÕcnica de despliegue es comenzar con el producto
final deseado y ver quÕ clases de datos se obtendrÚan si esta escala fuera realmente asÚ. Tenemos, siguiendo la terminologÚa de Coombs, una escala J
de algºn atributo, en la que pueden ubicarse los estÚmulos y tambiÕn la posiciµn deseada o preferencia del sujeto. Por ejemplo, supongamos que tenemos cinco
niveles diferentes de concentraciµn de azºcar en una bebida suave y que conocemos los valores escalares del atributo de dulzura, y tambiÕn la posiciµn
de preferencia de cada sujeto con respecto al mismo atributo. La figura 1 muestra dos posibilidades de escalas J. En la escala J1,
se sitºan cinco estÚmulos equidistantes; de esta manera hemos supuesto temporalmente que esos cinco estÚmulos constituyen una escala conocida de
intervalos iguales. Ahora bien, cada sujeto tendrà un grado de dulzura preferido; asÚ que cada sujeto puede ubicarse en la escala. Los nºmeros arÃbigos
indican la amplitud dentro de la que puede estar la preferencia del sujeto, y cada amplitud tendrà un efecto diferente sobre las respuestas dadas por el
sujeto. En el experimento real pedimos a cada sujeto que ordene su preferencia por los
cinco niveles de dulzura, y suponemos que los ordenarà segºn la cercanÚa de la dulzura efectiva con su dulzura preferida. Con esta suposiciµn, podemos predecir
exactamente cuÃles serÃn los lugares de orden de los cinco estÚmulos para cada amplitud de posiciones de preferencia posible. Las ordenaciones para cada
posiciµn de preferencia son: 1 ABCDE 5 CDBEA En esta escala particular J, posiblemente no se presente ninguna otra ordenaciµn,
y si en un experimento obtenemos solamente estas ordenaciones de todas las posibles ordenaciones de cinco objetos ( 5 o 120), entonces habremos aprendido
dos cosas: primero, sabemos que los estÚmulos pueden efectivamente ordenarse; y segundo, que podemos determinar la ordenaciµn desplegando los diferentes rangos
de preferencia para obtener la escala original de los estÚmulos mismos. El tÕrmino "desplegar" se usa porque, en efecto, cuando el sujeto hace sus
ordenaciones de preferencia, dobla la escala de dulzura usando como eje su propia posiciµn en la escala, y al reconstruir Õsta, nosotros, en efecto,
desplegamos las ordenaciones. Ahora veremos quÕ sucederÚa si los intervalos entre los estÚmulos sobre la
escala f no fueran desiguales. La escala J2 de la figura 1 presenta dicha escala hipotÕtica y ahora nos preguntamos quÕ ordenaciones harÚan los sujetos si sus
posiciones de preferencia estuvieran en los intervalos indicados por los nºmeros arÃbigos. En este caso, podrÚan presentarse las siguientes ordenaciones de
preferencia: 1 ABCDE Donde hay mÃs de una ordenaciµn de preferencia posible para una amplitud dada de posiciones, la ordenaciµn exacta de rango depende precisamente de la posiciµn de
la preferencia del sujeto. En total, con este conjunto de valores escalares para el atributo de dulzura, pueden presentarse 11 ordenaciones diferentes y podemos
asÚ reconstruir la ordenaciµn de los estÚmulos desplegando las ordenaciones de preferencia. Aunque no entraremos en mÃs detalles sobre la tÕcnica de despliegue debe quedar
claro que en cualquier escala particular de dulzura, puede presentarse un nºmero limitado de ordenaciones de preferencia posibles; y que si pedimos a suficientes
sujetos diferentes que ordenen los estÚmulos para obtener un gran nºmero de posiciones de preferencia diferentes, entonces no solo podemos conocer la
ordenaciµn de los estÚmulos, sino tambiÕn ordenar los tamaþos de los intervalos entre los estÚmulos. De esta manera podemos obtener una escala mÕtrica de orden. ObsÕrvese que tanto en la tÕcnica de Coombs como en la de Guttman la
consistencia, interna es la parte crÚtica del procedimiento. AdemÃs, en ambas tÕcnicas se usa el mismo principio para determinar la consistencia interna:
limitar el nºmero de resultados posibles que pueden suceder y que sean aceptables para satisfacer los requerimientos de mediciµn de la escala. En la
tÕcnica de Guttman, con reactivos dicotµmicos, es posible que sucedan 2n patrones de resultados con n reactivos diferentes, pero solamente se
aceptan (n + 1) ; resultados que satisfacen los requerimientos ordinales. En la tÕcnica de Coombs, existen n! maneras de ordenar n reactivos, pero en
cualquier escala de ordenaciµn solamente se darÃn [1/2n(n - 1) + 1] ordenaciones posibles. En nuestro ejemplo de cinco estÚmulos, hay 120 maneras
de ordenar los estÚmulos pero solamente 11 maneras de una ordenaciµn efectiva. TÕcnicas de intervalo manifiesto El
aspecto principal de las tÕcnicas escalares de intervalo manifiesto es que se requiere una respuesta directa; y ya por las instrucciones dadas al sujeto o ya
por una suposiciµn de parte del experimentador, los datos se tratan como si tuvieran propiedades intervalares. Las principales diferencias de tÕcnica se
refieren a los tipos de objetos estÚmulo usados y a las limitaciones que imponen al procedimiento experimental.
Equisecciµn. Supongamos que deseamos determinar los valores escalares psicolµgicos de estÚmulos que estÃn en un continuo fÚsico verdadero, donde puede
manipularse fÃcilmente para producir variaciµn continua. No existen muchos continuos fÚsicos de este tipo que interesen al psicµlogo. Tanto la frecuencia
como la intensidad de los sonidos pueden manipularse asÚ; y, con un aparato complejo, tambiÕn la brillantez fÚsica y aºn el matiz o la saturaciµn. A lo
anterior agregamos el choque elÕctrico, la vibraciµn y la intensidad de los olores. En nuestro ejemplo, usaremos la
intensidad de los sonidos, y la sonoridad serà el atributo psicolµgico cuya escala deseamos determinar. El procedimiento es muy sencillo: suministramos dos
sonidos de intensidad fija y pedimos al sujeto que ajuste la intensidad de otros sonidos hasta que los ordene dentro de una serie de intervalos iguales de
sonoridad. A cada uno de los sonidos obtenidos y a los dos sonidos que definieron la amplitud original de sonoridad, se les asignan valores numÕricos separados por
intervalos iguales para estar de acuerdo con la suposiciµn de que los sonidos producidos por el sujeto proporcionan una escala intervalar de sonoridad.
El nºmero de estÚmulos que debe ajustar el sujeto lo decide el experimentador. En el caso lÚmite, en que se suministran dos estÚmulos extremos y el sujeto
tiene que ajustar un solo estÚmulo al valor medio entre los dos, el mÕtodo se llama "bisecciµn", porque se pide al sujeto que bisecte un intervalo.
Con el fin de verificar la consistencia interna, es conveniente usar por lo menos dos conjuntos diferentes de valores para los estÚmulos extremos, fijos, y
hacer que las amplitudes se traslapen. En tal circunstancia, desearÚamos usar suficientes estÚmulos dentro de cada amplitud para lograr un traslapamiento
sustancial en el nºmero de estÚmulos comunes a ambos conjuntos. En los datos del ejemplo presentados en la figura 2, se emplearon siete estÚmulos (dos estÚmulos
extremos y cinco estÚmulos ajustables) y dos amplitudes de intensidad (de 50 a 90 db y 70 a 110 db de intensidad sonora). Se pidiµ a los mismos sujetos que
ajustaran cinco estÚmulos dentro de cada amplitud; los datos presentados en la figura 2 son los promedios de las intensidades ajustadas. En cada amplitud, se
asignaron valores numÕricos de 3 a 9 a los siete estÚmulos. Esto se indica con puntos en la amplitud superior y con triÃngulos unidos con lÚnea interrumpida en
la amplitud inferior. Para construir la
escala final, descrita por la lÚnea continua, se redujo el tamaþo del intervalo de la unidad en los datos de la amplitud inferior; y, sustrayendo una constante,
la curva entera se trasladµ hacia abajo. Debe recordarse que en una escala de intervalo tenemos libertad para usar cualquier transformaciµn lineal de los
valores escalares; y esto significa que podemos ajustar la intersecciµn y la pendiente hasta lograr el mejor ajuste de los dos conjuntos de datos de
equisecciµn traslapados. Es decir, usamos dos de los grados de libertad de los valores inferiores para establecer nuestra unidad de escala en los valores
superiores; y ahora debe estar claro por quÕ es mejor usar varios estÚmulos intermedios en equisecciµn. Si tuviÕramos solamente dos puntos de traslapamiento
y, por tanto, dos grados de libertad para determinar los valores escalares, podrÚamos asegurarnos de que las dos secciones de la curva se ajustaran dentro
de la amplitud de traslapamiento. Y serÚa todavÚa posible que las dos secciones proporcionaran una funciµn aparentemente discontinua; pero una curva de forma
rara o quebrada serÚa, precisamente, la ºnica verificaciµn de la validez de la suposiciµn intervalar. Por otra parte,
si tres o mÃs valores de estÚmulos se traslapan, entonces la curvatura o la forma de la funciµn puede considerarse la misma o diferente para la misma
amplitud de intensidades. Evidentemente si nuestra suposiciµn de que puede formarse una escala de intervalo es vÃlida, entonces debemos obtener la misma
escala para la misma amplitud de intensidades, independientemente de los estÚmulos extremos usados para obtener estos valores escalares particulares.
Podemos de este modo proporcionar una verificaciµn de consistencia interna, y al mismo tiempo extender la amplitud de intensidad en la que obtenemos una escala
psicolµgica. Intervalos aparentemente iguales. Cuando los objetos para los que deseamos hacer una escala no pueden
medirse por una dimensiµn fÚsica continua, podemos recurrir entonces a otros procedimientos. Por ejemplo, supongamos que deseamos construir una escala de la
capacidad verbal de individuos tal como es juzgada por otras personas; o bien que deseamos una escala para la "bondad del patrµn" de varios patrones
geomÕtricos. En estos casos no podemos decir al sujeto o al juez que ajuste los estÚmulos para suministrar intervalos iguales, porque los estÚmulos son fijos y
no pueden ajustarse. En este caso podemos instruir al sujeto para que dÕ un nºmero a cada estÚmulo, de manera que
los nºmeros que use estÕn separados por intervalos iguales. O, alternativamente, podrÚamos pedirle al sujeto que clasifique a los estÚmulos en categorÚas
adyacentes de modo que Õstas satisfagan los requisitos intervalares. Los datos adoptarÚan exactamente la misma forma que los del mÕtodo de categorÚas de rango,
como se ve en la tabla 3. La ºnica diferencia radica en la indicaciµn de que el sujeto use sus categorÚas como intervalos iguales y no como rangos. Sin embargo,
con la suposiciµn de que lo hace asÚ, es lÚcito usar el valor medio de categorÚa para cada estÚmulo en vez de la mediana, como se indicµ antes.
Para contrastar el mÕtodo de intervalos aparentemente iguales con el de equisecciµn, advirtamos que en el ºltimo mÕtodo los estÚmulos son escogidos o
colocados por el sujeto, a modo de definir una serie de puntos sobre el continuo del atributo y que luego se supone que son iguales los intervalos entre estos
puntos. Sin embargo, en los intervalos aparentemente iguales nunca tenemos estÚmulos que definan intervalos iguales como puntos sobre el continuo, ni los
valores de categorÚa ya sea usados o asignados lo hacen, dado que definen una amplitud de valores, y no puntos. En vez de eso, se supone que cada categorÚa de
respuesta proporciona una amplitud de valores, un intervalo, que es igual a todos los demÃs intervalos. Y tambiÕn se supone, desde luego, que los intervalos
estÃn en orden adecuado y son contiguos. Escalas de categorÚas numÕricas. El mÕtodo de intervalos aparentemente iguales
se usa comºnmente cuando debe juzgarse un gran nºmero de estÚmulos y cada sujeto evalºa o juzga a cada estÚmulo sµlo una vez. Un mÕtodo semejante (en realidad,
idÕntico lµgicamente) se usa cuando se tienen relativamente pocos estÚmulos; pero cada uno de ellos es evaluado varias veces por cada sujeto, sobre una
escala numÕrica con la indicaciµn de que use los valores escalares como una escala de intervalo. El tÕrmino "escala de categorÚas" se aplica a menudo a este
mÕtodo; y nosotros lo llamamos mÕtodo de escalas de categorÚas numÕricas para distinguirlo de los mÕtodos en que se usan categorÚas verbales o que estÃn
ordenadas espacialmente. Como ejemplo del uso de esta escala, la figura 3 presenta algunos datos de un experimento de
Torgerson (1960). Como estÚmulo se usaron 17 matices de papel gris neutro y cada uno fue juzgado cinco veces por cada uno de 16 sujetos. Los estÚmulos se
presentaron al azar y los sujetos evaluaron cada estÚmulo sobre una escala de 11 puntos (del 0 al 10); se les indicµ que usaran la escala numÕrica como una
escala de intervalo. En un conjunto de experimentos juzgaron la claridad; aquÚ, los nºmeros mÃs grandes indicaban mayor claridad. En otro conjunto juzgaron la
oscuridad, y ahora los nºmeros mÃs grandes indicaban mayor oscuridad. En la figura 3 se aprecian las evaluaciones medias de categorÚa como una funciµn de la
reflectancia, en cada tipo de juicio. En este experimento particular se demostrµ la consistencia interna por el hecho de que la funciµn en el atributo de
claridad es la inversa de la funciµn para el atributo de oscuridad. Esta comprobaciµn, solo es posible, naturalmente, cuando los mismos estÚmulos pueden
juzgarse con respecto a dos atributos en que uno es el inverso del otro.
Escalas de evaluaciµn verbal. Una ºltima tÕcnica digna de menciµn es la escala de evaluaciµn verbal. El tÕrmino "escala de evaluaciµn" es muy general y puede
usarse para describir cualquier escala de respuestas a la que recurra el sujeto para efectuar una tarea de evaluaciµn o de juicio. Una escala de evaluaciµn
verbal difiere de un mÕtodo de intervalos aparentemente iguales o de una escala de categorÚas numÕricas solamente en que se usan rµtulos verbales como
respuestas. La siguiente, por ejemplo, podrÚa constituir una escala de siete categorÚas para juzgar la brillantez: completamente oscuro, muy oscuro, oscuro,
neutro, claro, muy claro, completamente claro. Si al resumir los datos asignamos numerales espaciados igualmente a estas categorÚas de respuesta y usamos
estadÚsticas mÕtricas, en realidad asignamos propiedades intervalares a la escala. La ºnica diferencia bÃsica entre este mÕtodo y otras tÕcnicas
manifiestas intervalares es el tipo de escala de respuesta que se usa. La escala habitual de calificaciones mencionada al principio como ejemplo de
escala ordinal, trÃtase a menudo como si tuviera propiedades intervalares, como si fuera una escala de evaluaciµn verbal. Esto sucede cuando se asignan nºmeros
arbitrarios a las calificaciones con el propµsito de obtener promedios de puntuaciones de calificaciµn. La suposiciµn es que la distancia entre "A" y "B"
es igual a la distancia entre "D" y "E" -precisamente la suposiciµn de la escala de intervalo- cuando se asignan nºmeros consecutivos a las calificaciones.
Pruebas de consistencia interna. Las tÕcnicas de construcciµn de escalas basadas
en propiedades manifiestas de los datos no incluyen generalmente procedimientos de comprobaciµn de la consistencia interna como un aspecto inherente de
aquÕllas. En consecuencia, con estas tÕcnicas debe suministrarse prueba de la consistencia interna realizando dos o mÃs experimentos, que deben conducir
lµgicamente a la misma escala resultante, ya sea total o parcialmente. El experimento de Torgerson, sobre juicios de claridad y oscuridad, ilustra un
mÕtodo para comprobar la consistencia interna, pero obviamente tal comprobaciµn depende tanto de la naturaleza de los estÚmulos como de la de los atributos. No
existe, por ejemplo, atributo inverso de lanzar, de destreza o de la mayorÚa de las aptitudes. La otra comprobaciµn de
la consistencia interna, de uso sencillo, es la que mencionamos en la tÕcnica de equisecciµn, a saber, la duplicaciµn del experimento con amplitudes diferentes
de estÚmulos, pero que se traslapan. En el caso del experimento de sonoridad tenÚamos una dimensiµn fÚsica que correspondÚa al atributo; esta es la razµn por
la que pudimos seleccionar de antemano estÚmulos extremos fijos, y estÃbamos seguros de que se obtendrÚan valores escalares traslapados. El problema es
diferente cuando los estÚmulos son del tipo de objetos de arte, comidas cuyas preferencia relativa tratamos de evaluar o la sociabilidad de las personas. En
este caso, como vimos, se usa por lo comºn la tÕcnica de intervalos aparentemente iguales, toda vez que no podemos dar a los sujetos control directo
sobre los estÚmulos. Es, posible un procedimiento equivalente a la prueba de consistencia usada en la equisecciµn. Podemos realizar subexperimentos en los
que se dupliquen tres o mÃs estÚmulos en conjuntos diferentes de estos. Entonces tendrÚamos la misma clase de prueba anterior en la que los valores escalares
asignados a los estÚmulos se transforman de manera que coincidan los que resulten ser comunes en subexperimentos diferentes. Si esto puede hacerse con
tres o mÃs estÚmulos, habrà entonces evidencia clara de que es vÃlida la propiedad intervalar asumida con respecto a las respuestas. Desafortunadamente
este tipo de prueba interna muy raramente se efectºa. LA SEGURIDAD EN AVIACIÆN: IMPORTANCIA DEL FACTOR HUMANO. XVIII PROBLEMAS Y MèTODOS DE LA ELABORACIÆN DE ESCALAS PSICOLÆGICAS
Cuantificaciµn, mediciµn, elaboraciµn de escalas, todas son palabras que connotan el uso de
nºmeros para describir fenµmenos. Pero cualquiera que sea el tÕrmino usado, la metodologÚa cuantitativa ha sido la marca distintiva de una ciencia madura y asÚ
sucede con la psicologÚa. La metodologÚa cuantitativa y la mediciµn desempeþan funciones muy amplias en la psicologÚa, de la misma manera que en cualquier otra
ciencia. Uno de los primeros usos de la metodologÚa cuantitativa consiste en especificar
rigurosamente las condiciones que priven en un experimento, de modo que puedan reproducirse con fidelidad en otra ocasiµn y quizà por otro experimentador. Por
ejemplo, especificamos la intensidad fÚsica de una luz o de un estÚmulo de sonido en tÕrminos exactos, como forma para evitar confusiµn en otros psicµlogos
experimentales que necesiten saber las condiciones de nuestro experimento. AdemÃs de la declaraciµn precisa de las condiciones del experimento, el mÕtodo cuantitativo
debe incluir tambiÕn el tratamiento que haya de darse a los datos obtenidos. Necesitamos expresar nuestros resultados en forma que puedan comprobarse
exactamente por otro experimentador. Usamos tÕcnicas estadÚsticas para describir los resultados de un experimento y tambiÕn con gran frecuencia para estimar la
probabilidad de que se presenten los mismos resultados, dentro de un margen previsto de error, cuando se repita dicho experimento.
Podemos recurrir tambiÕn a matemÃticas, ya mÃs abstractas, para expresar relaciones entre las variables dependiente e independiente, y el efecto de la
variable independiente sobre algºn aspecto de la conducta. Una ecuaciµn matemÃtica puede resumir y presentar la mayorÚa de las relaciones entre
variables mucho mÃs eficazmente y tal vez con mayor significado que la simple enumeraciµn de las condiciones experimentales y los resultados. En aþos
recientes, la psicologÚa ha hecho uso considerable de la matemÃtica abstracta para describir los fenµmenos, que estudia.
Estas aplicaciones del mÕtodo cuantitativo no son exclusivas de la ciencia de la psicologÚa ni el tema principal de este capÚtulo. Nos ocuparemos de la mediciµn
de atributos psicolµgicos, campo de estudio que se ha denominado elaboraciµn de escalas psicolµgicas.
LA NATURALEZA DE LOS ATRIBUTOS Atributo es una propiedad abstraÚda de la experiencia humana. Hay dos aspectos
importantes en esta definiciµn, cada uno de los cuales entraþa algunos problemas especiales en la mediciµn de atributos, lo que ha hecho un tanto confusa la
naturaleza de la elaboraciµn de escalas psicolµgicas. El primer aspecto es que el atributo es una propiedad abstraÚda de alguna cosa; y no la cosa misma. Este
hecho bastante interesante produce muchas dificultades en la mediciµn; pero no es privativo de la mediciµn psicolµgica. Cuando hablamos de medir alguna cosa en
una situaciµn de la vida diaria, no hablamos realmente de medir un objeto o un suceso, sino alguna propiedad abstraÚda de uno y otro. Por ejemplo, cuando
medimos la longitud o el peso, no medimos el objeto que tiene la longitud o el peso, sino que medimos una propiedad abstraÚda o dimensiµn del objeto.
El segundo aspecto de nuestra definiciµn es que un atributo se relaciona con la experiencia psicolµgica, lo que lo hace singularmente psicolµgico y crea
dificultades. QuizÃs podamos esclarecer este problema al contrastar un atributo (de experiencia) con una dimensiµn fÚsica que estÕ Úntimamente relacionada con
la experiencia. Un sonido tiene intensidad fÚsica, la cual podemos medir aplicando tÕcnicas estÃndar de mediciµn fÚsica. Y podemos experimentar la
sonoridad; pero esta no es idÕntica a la intensidad fÚsica. La sonoridad es algo que experimentamos; la intensidad es un aspecto del estÚmulo mismo.
Hablamos, casualmente, de la sonoridad de un sonido y no de la sonoridad de nuestra experiencia. Esto causa comºnmente poca confusiµn. Pero cuando nos
interesamos por la mediciµn de la sonoridad, la distinciµn se vuelve importante, ya que necesitamos investigar las propiedades del atributo sonoridad, aunque no
podamos observar, en el sentido fÚsico, la cosa que estamos tratando de medir. Esta distinciµn entre el atributo y la dimensiµn del objeto fÚsico o
acontecimiento es fÃcil de apreciar en los casos en que hay una evidente contraparte fÚsica del atributo que nos interesa. En otros casos la distinciµn
es mÃs sutil. Por ejemplo, cuando las personas son el estÚmulo que nos interesa y deseamos medir algo que llamamos capacidad de liderazgo o actitudes, a menudo
es difÚcil percatarse de que la medida que nos interesa no es la del estÚmulo externo sino la del atributo subyacente que se experimenta. En tales casos, la
distinciµn adquiere aºn mayor importancia. LA NATURALEZA DE LA MEDICIÆN
Al elaborar escalas psicolµgicas el interÕs se centra en el desarrollo de escalas de mediciµn para atributos psicolµgicos. Antes de presentar tÕcnicas
concretas de mediciµn, es conveniente analizar la naturaleza de la mediciµn en tÕrminos generales y, despuÕs, algunos de los problemas especiales que reviste
la mediciµn de atributos psicolµgicos. Medir, en sentido amplio, es asignar numerales a objetos, conforme a una regla
especificada. Pero esta definiciµn es demasiado simple y aun confusa, a menos que consideremos los problemas especiales del uso de numerales. Los numerales
son ºnicamente sÚmbolos -el "1 ", "2", "53", etc., que escribimos o imprimimos.
De esta manera, si el problema de la mediciµn fuera simplemente asignar numerales a objetos mediante alguna regla, podrÚamos usar cualquier regla que
deseÃramos, siempre que tal uso fuese consistente. La escala numÕrica
Los numerales representan, empero, una clase particular de escala: la escala numÕrica. El numeral "1" representa un solo objeto, el numeral "2" representa
dos objetos; y cada numeral que usamos tiene un significado directo en cuanto que representa un nºmero de objetos o acontecimientos. La escala numÕrica es una
escala de contar y es la escala de mediciµn mÃs sencilla y elemental que tenemos. En sentido estricto, los numerales pueden tener cualesquiera de las propiedades
-matemÃticas o de otra clase- que les asignemos. Pero, en vista de que los numerales representan la escala fundamental de los nºmeros, es comºn suponer que
tienen las propiedades de la escala de estos. Supongamos por ejemplo, que tenemos 12 objetos. Podemos realizar varias operaciones con estos objetos y
podemos tambiÕn realizar las operaciones equivalentes con los numerales mismos. Podemos agregar 3 objetos a nuestros 12; si entonces, los contamos, tendremos 15
objetos. Pero podemos agregar el numeral "3" al numeral "12" y obtener asÚ el mismo resultado con mÃs rapidez. O podemos sustraer objetos o sus nºmeros
equivalentes y obtener de las dos maneras el mismo resultado. Podemos aºn dividir los 12 objetos en dos grupos iguales y entonces al contar cada grupo
encontraremos que hay 6 objetos en cada uno, hecho que puede determinarse fÃcilmente haciendo la divisiµn en el papel.
La escala numÕrica tiene muchas propiedades; pero cuando les asignamos numerales a los atributos o bien le asignamos dimensiones diferentes de los nºmeros,
necesitamos ser cuidadosos para determinar quÕ propiedades de la escala numÕrica son aplicables. Este problema no tiene nada que ver con la determinaciµn de las
propiedades de la escala de los nºmeros; lo que se impone es determinar las propiedades del atributo mismo y despuÕs asegurarnos de que los numerales se
asignan de manera que reflejen las propiedades de ese atributo. Algunas propiedades de las escalas
Hemos hecho breve alusiµn a ciertas propiedades de la escala numÕrica; pero las mÃs importantes de ellas necesitan mayor explicaciµn. Estas propiedades suelen
usarse para describir la naturaleza de una escala psicolµgica, ya que limitan la interpretaciµn de los valores escalares.
Escalas nominales. La propiedad mÃs sencilla y fundamental de la escala numÕrica es la de nombrar o identificar artÚculos u objetos. Como ejemplo
sencillo, podemos preguntar su sexo a varias personas y despuÕs asignarle a cada una el nºmero clave "1" si dice que es masculino y el nºmero "2" si es femenino.
Este uso de los numerales tambiÕn es mediciµn pero en sentido muy primitivo. Cumple, sin embargo, con el requisito de la asignaciµn de nºmeros segºn una
regla. Pero adviÕrtase que la ºnica propiedad de la escala de los nºmeros que es aplicable aquÚ es la relaciµn de identidad, a saber, que todos los objetos que
recibieron el mismo nºmero tienen el mismo sexo. No podemos, en este caso, usar ninguna otra propiedad de la escala numÕrica. Por ejemplo, no podemos decir que
las mujeres son "mÃs" que los hombres, o que son dos veces el nºmero de hombres, aunque los numerales representen estas propiedades de la escala numÕrica.
Nµtese, sin embargo, que podemos cambiar libremente los numerales asignados en tanto que se haga el cambio en todas las mujeres y en todos los hombres.
PodÚamos haba llamado a las mujeres "1 " y a los hombres "2". La razµn de esto es que la calidad que se "mide" no tiene ninguna otra propiedad mensurable que
la de identidad o equivalencia. El aspecto general que hemos ilustrado es sencillamente este: Las reglas permisibles paro asignar numerales a objetos
dependen de las propiedades del atributo que se mide, y no de las propiedades de la escala de los nºmeros. Por tanto no podemos determinar quÕ regias son
permisibles sin conocer algo de las propiedades del atributo mismo. Escalas ordinales. Una segunda propiedad de la escala numÕrica es la de
orden: el nºmero "10" es mÃs grande que el nºmero "6", y tambiÕn mÃs grande que todos los nºmeros menores que 10. Es de notarse que esta propiedad supone la
propiedad nominal, toda vez que se usa el mismo numeral para todos los objetos que son idÕnticos.
En psicologÚa, el uso mÃs simple de las escalas ordinales aparece cuando ordenamos un conjunto de objetos con respecto a un atributo asignÃndole a cada
objeto un solo numeral que refleje su posiciµn ordinal. Pero podemos usar tambiÕn una escala de orden y asignar a diferentes objetos el mismo nºmero de
orden. La escala de calificaciones escolares de "A", "B", "C", "D" y "F" es una
escala semejante, aun cuando se utilicen letras y no numerales, puesto que todas las calificaciones de "A" son mejores que todas las de "B", etc.
Con la escala nominal decimos que podemos transformar los numerales en cualquier modo que conserve la relaciµn de identidad. En una escala ordinal podemos hacer
transformaciones bajo cualquier regla que conserve el orden original de los nºmeros asignados a los objetos. Es decir, una vez que se asigna un conjunto de
numerales, podemos cambiarlos libremente, escribiendo cualquier nuevo conjunto de nºmeros en tanto que estos sean una funciµn monotµnica positiva de los
nºmeros originales. Vemos asÚ cµmo el uso de la propiedad ordinal de la escala de los nºmeros para
asignar los numerales a los objetos depende de que el atributo mismo tenga la propiedad ordinal. Si es asÚ, entonces podemos usar esta regla mÃs restrictiva.
Escalas de intervalos. Una tercera propiedad de la escala numÕrica, aºn mÃs restrictiva, es la de igualdad de intervalos. Si agregamos 6 objetos a 24,
obtenemos 30 objetos; y los 6 objetos son los mismos que necesitamos agregar a 40 objetos para obtener 46. De esta manera la diferencia entre 30 y 24
representa la misma cantidad que la diferencia entre 46 y 40. Los intervalos numÕricamente iguales representan diferencias iguales en nºmero y cuando un
atributo tiene esta misma propiedad, entonces la regla para asignar numerales debe asegurar que se refleje adecuadamente esta propiedad. AdviÕrtase que en el
anterior ejemplo numÕrico , podÚamos cambiar todos los nºmeros con solo sumar una constante y esto no cambia el valor numÕrico de la diferencia; y una y otra
vez los intervalos seguirÚan siendo iguales. Cuando hablamos acerca de nºmeros efectivos, es claro que no podemos cambiar el
6 y seguir denotando la misma cosa, ya que 6 objetos adicionales son justamente eso, 6 mÃs, ni mÃs ni menos. Pero cuando representamos un atributo que no tiene
todas las propiedades de la escala de los nºmeros, aunque sÚ la propiedad de intervalos iguales, podrÚamos multiplicar todos nuestros numerales por una
constante y las dos diferencias aºn serÚan iguales. Es decir, en escalas de intervalos, podemos transformar la nuestra por medio de cualquier funciµn lineal
positiva -la cual es una transformaciµn mÃs restrictiva que la funciµn monotµnica positiva admisible en la escala ordinal. En forma matemÃtica, estÃ
permitido asignar cualquier nuevo conjunto de numerales, en tanto que se satisfaga la condiciµn de que
y'= a + by donde y es el numeral original y y' es el numeral transformado. La condiciµn
importante de la igualdad de diferencias se mantendrà aºn con los nuevos nºmeros. La psicologÚa nos proporciona incontables ejemplos de que puede asumirse la
propiedad ordinal de la escala de los nºmeros con respecto a un atributo psicolµgico; pero en lo que ataþe a propiedades intervalares estamos en un
terreno mucho menos seguro y a menudo no puede probarse la propiedad intervalar. La escala de CI es un buen ejemplo de una escala supuesta de intervalo, toda vez
que la diferencia entre un CI de 120 y uno de 130 se supone igual a la diferencia entre los CI de 90 y 100. Hay que observar que la escala entera
podrÚa trasladarse de modo que su centro fuera 200 y no 100; y esto no cambiarÚa ninguna de las propiedades de la escala. TambiÕn podrÚamos duplicar todos los
nºmeros y no cambiarÚamos la propiedad de igualdad de intervalos. Los numerales efectivos asignados son, entonces, completamente arbitrarios, pero tienen la
restricciµn de que la propiedad de intervalos iguales debe reflejarse en los numerales.
Escalas de razµn. Una propiedad aºn mÃs restrictiva de la escala numÕrica es la de igualdad de razones. El numeral "10" es dos veces el numeral "5", asÚ como
el numeral "90" es el doble del numeral "45". Por tanto, estas dos razones son iguales y asimismo sus contrapartes en la escala de los nºmeros, porque si en
cada caso se divide el nºmero mÃs grande en grupos que contengan cada uno al nºmero respectivo mÃs pequeþo, habrà exactamente dos grupos. Esta propiedad
significa que las operaciones numÕricas de multiplicaciµn y divisiµn son aplicables al atributo que se mide y lo son en el caso de una escala de nºmeros.
Nµtese que en este caso no tenemos libertad de transformar los nºmeros originales sumando o sustrayendo un nºmero, porque si lo hiciÕramos las razones dejarÚan de ser
iguales. Cuando tratamos con un atributo que tiene la propiedad de razµn, podemos multiplicar todos los numerales por una constante sin que se afecte la
propiedad de razµn. Lo que no podemos hacer es agregar o sustraer una constante. Por tanto, si tenemos una escala con propiedades de razµn, podemos transformar
nuestros numerales de tal manera que y' = by donde y' es el numeral transformado del original y. En
la investigaciµn psicolµgica hay pocos ejemplos de atributos que podamos asegurar que tienen la propiedad de razµn. La dificultad proviene del problema
de un cero absoluto. ObsÕrvese que ninguna transformaciµn admisible de una escala de razµn cambia el punto cero de la escala, aunque esto sÚ sucede en una
escala de intervalo. En efecto, el requerimiento bÃsico de una escala con propiedades de razµn es que exista un cero absoluto, lo que significarÚa
literalmente que se carece por completo del atributo. Pero no basta con tener un punto cero en una escala a menos que tambiÕn estemos seguros de que el cero
representa la carencia absoluta del atributo. En psicologÚa, el problema es doble. Primero, no hay muchos atributos de los que
podamos suponer razonablemente que tienen un cero absoluto. Por ejemplo, ¢cuÃl serÚa el cero absoluto de la inteligencia? o ¢cuÃl es el cero absoluto de la
actitud hacia el partido republicano? Puede, sÚ, haber un sentimiento de neutralidad; y la posiciµn neutral se usa corrientemente como el punto cero
sobre una escala; pero no representa la carencia absoluta del atributo. El cero es sencillamente una posiciµn entre las actitudes positivas y negativas. O, en
un ejemplo mÃs, ¢cuÃl serÚa el cero absoluto de arrojar? Es difÚcil describir lo que significamos por "ninguna cantidad de lanzamiento", ya que el lanzamiento
existe como diferencia, pero no estrictamente como magnitud. El otro aspecto del problema tiene que ver con nuestra capacidad para determinar
el cero verdadero o absoluto en el dado caso de que existiera lµgicamente. Por ejemplo, consideremos el atributo psicolµgico de brillantez. Podemos producir
una condiciµn de carencia de luz pero tal situaciµn fÚsica no garantiza la falta absoluta de brillantez, ya que es posible obtener un negro mÃs negro que el que
hayamos experimentado. En tÕrminos neurolµgicos, sabemos que la completa ausencia de luz no produce ausencia completa de actividad nerviosa (Kuffler,
FitzHugh y Barlow, 1957); de ahÚ que parezca muy razonable suponer que el negro psicolµgico absoluto nunca puede experimentarse. De la misma manera sucede con
cosas como la sonoridad, que probablemente nunca podamos experimentarlas directamente. La
escala de temperatura es un ejemplo fÚsico de este problema. Se sabe desde hace tiempo que hay un cero absoluto de temperatura (el cual, por supuesto, no
corresponde al cero de las escalas Fahrenheit o centÚgrada); pero producir fÚsicamente tal condiciµn es un problema harto diferente. La existencia de un
cero absoluto pudo deducirse del comportamiento de las temperaturas mensurables, y se determinµ finalmente su valor relativo a la escala centÚgrada. Pero,
histµricamente, la tarea de obtener una escala de razµn se dificultµ por la incapacidad de trabajar directamente con el cero absoluto.
Este ejemplo seþala otra manera de caracterizar una escala de razµn; es aquÕlla en la que no pueden asignarse nºmeros negativos. Podemos ver que este es el caso
de contar objetos, como en la escala de los nºmeros, y de la escala Kelvin de temperatura. En cada caso carece de sentido hablar de un nºmero de objetos menor
que cero o de una temperatura menor que cero absoluto. Otras propiedades de la escala. Las cuatro clases de escalas que hemos
analizado son ciertamente cuatro de los tipos mÃs importantes que se emplean comºnmente, pero no significa de ninguna manera que sean las ºnicas posibles.
Hay muchas otras combinaciones de las propiedades de la escala numÕrica que tambiÕn podrÚan ser propiedades de un atributo psicolµgico. Es posible, por
ejemplo, que sepamos que un intervalo, en una escala, es mÃs grande que en otra, pero no podemos especificar exactamente cuÃnto mÃs grande. En tal situaciµn, no
solamente podrÚamos ordenar los objetos, sino tambiÕn ordenar los intervalos entre los objetos. Coombs (1950) ha propuesto tal escala, que estudiaremos en
una secciµn posterior. TambiÕn es posible tener una escala verdadera de razµn para intervalos entre objetos, y no solamente una escala de intervalo para los
objetos mismos. Esta situaciµn se presentarÚa si pudiÕramos identificar y medir una diferencia de cero entre objetos y al mismo tiempo estuviÕramos seguros de
las propiedades de razµn de las diferencias. Eficacia y limitaciones de las escalas. Es muy frecuente hablar de la
eficacia de una escala, tÕrmino que alude a los tipos de propiedades matemÃticas que hemos estudiado. Una escala de razµn es mÃs eficaz que una escala de
intervalo porque no solamente nos indica los intervalos numÕricos del atributo medido, sino que tambiÕn nos habla de razones. Y una escala de intervalo es, a
su vez, mÃs eficaz que una escala ordinal porque nos informa de todo lo de Õsta, y ademÃs nos habla de intervalos. Los especialistas en escalas psicolµgicas
procuran por lo comºn inventar escalas que tengan cuando menos propiedades intervalares, aunque sea necesario hacer algunas suposiciones para obtener la
mayor eficacia. Existen algunas ventajas reales en la especificaciµn mayor de un atributo, que dÕ lugar a las escalas de mayor alcance.
Hay, sin embargo, otro aspecto del problema que igualmente se considera al elaborar escalas: que el especialista encuentra mÃs restringido para usar los
nºmeros en las escalas mÃs eficaces. Como hemos visto en una escala tan dÕbil como la nominal, la ºnica restricciµn es que se use el mismo nºmero para objetos
o cantidades idÕnticas de un atributo. Pero, en una escala ordinal, deben asignarse los nºmeros de manera que se reflejen las relaciones ordinales
inherentes al atributo medido; y esto mismo, en las escalas mÃs poderosas, està aºn mÃs restringido. En la propia escala de los nºmeros, la escala mÃs eficaz,
no tiene por supuesto ninguna alternativa, porque debe asignar los nºmeros a los atributos de la manera especificada exactamente: el nºmero "10", por ejemplo,
puede usarse solamente para diez objetos, ni mÃs ni menos. Una vez establecida, la escala de mayor alcance tiene mayor utilidad; pero el
especialista tiene mucho menos libertad para fijar los valores escalares. En efecto, siempre se encuentra en conflicto. Desea establecer una escala tan
eficaz como le sea posible, pero està mucho menos seguro de haberlo hecho con acierto que si hubiera intentado formular una escala mÃs dÕbil. La escala
resultante a menudo representa un ajuste entre una escala con el mÃximo alcance y otra con la mÚnima restricciµn para el especialista.
EL PROBLEMA BêSICO DE LA ELABORACIÆN DE ESCALAS Cualquier experimento en el terreno de la elaboraciµn de escalas se ocupa de
tres conjuntos de variables, que tambiÕn es el principio para entender los diferentes papeles que desempeþan cada uno. En los casos mÃs sencillos esto es
fÃcil de ver. Las tres variables son: los estÚmulos, el conjunto de objetos que hemos seleccionado; los sujetos, a quienes se presentarÃn los objetos; y las
respuestas que la situaciµn experimental requiera. El papel que puede desempeþar cada una de estas variables en el proceso de elaborar escalas puede variar, pero
siempre se puede escoger un conjunto anÃlogo de tres variables. Cada uno es importante y debe escogerse cuidadosamente.
SerÚa bueno recordar que el problema de formular escalas psicolµgicas es el de asignar numerales a un atributo, que es una propiedad abstracta y no debe
confundirse con el objeto mismo. Sin embargo, a menudo la ºnica manera de especificar quÕ proporciµn del atributo corresponde a un numeral indicado es
seþalar un objeto particular como ejemplo. Por tanto, como hecho prÃctico, concluimos asignando numerales a los objetos, pero nuestro propµsito no es decir
que el objeto es el numeral, sino mÃs bien que el objeto contiene el atributo en esa medida. Por otra
parte, mientras estamos interesados en el efecto de los objetos estÚmulo sobre las personas a quienes se presentan, la verdad es que todo lo que poseemos para
empezar son las respuestas que obtenemos de nuestros sujetos. Entonces en el proceso de construir escalas es necesario una doble cadena inferencial. Los
estÚmulos se escogen, primero, para representar de manera distintiva el mundo de los estÚmulos posibles; despuÕs, se toman las respuestas que reflejen, en
sentido significativo, la experiencia del sujeto. La respuesta debe reflejar tambiÕn el aspecto del experimento que nos interesa. Esto no siempre es tan
fÃcil como podrÚa parecer. Por ejemplo, la respuesta de un sujeto al efecto de ver una luz muy dÕbil no siempre puede tomarse por su valor aparente, sino que
està determinada por muchos aspectos de la situaciµn diferentes de la intensidad de la luz. Hemos
estado hablando de objetos considerÃndolos las fuentes del atributo, aunque en algunos de nuestros ejemplos hemos usado personas como objetos. En realidad, si
pensamos en los objetos como estÚmulos, podemos hacer escalas para cualquiera de las tres variables: los estÚmulos, los sujetos o las respuestas. No existe, por
ejemplo, una relaciµn simple entre las respuestas dadas por el sujeto durante el experimento y la mÕtrica subyacente del atributo. Ciertamente si las respuestas
son verbales y no numÕricas, necesitamos incluir en escalas las respuestas antes de que podamos hacer lo mismo con los estÚmulos; en efecto, difÚcilmente puede
hacerse una cosa sin la otra. Si tratamos de asignar correctamente numerales a los estÚmulos, tambiÕn podemos encontrar una escala numÕrica para las
respuestas, porque estamos buscando una relaciµn funcional entre los estÚmulos y las respuestas. Es
tambiÕn completamente posible que podamos determinar la cantidad de un atributo correspondiente al sujeto mismo. Este es comºnmente el caso que se presenta
cuando medimos actitudes. AquÚ, la funciµn de los objetos es proporcionar una forma en la que el sujeto exprese la cantidad del atributo que se halle en Õl
mismo y no en el objeto. Por ejemplo, si los objetos tienen una cantidad predeterminada del atributo, entonces podemos determinar la percepciµn que el
sujeto tiene de sÚ mismo, encontrando quÕ objetos aceptarà como representativos de sÚ mismo o deseables para Õl. Abelson (1960) ha
expresado estas interrelaciones en otra forma. Distingue entre agentes, objetos y modos, que son las tres variables requeridas en el problema de establecer
escalas psicolµgicas. A pesar de que esta distinciµn sea algo ambigua, en principio es confiable. Ilustremos a grandes rasgos este punto, suponiendo que
deseamos hacer una escala de la sonoridad de varios ruidos de trÃnsito. Nuestro problema serà entonces asignar numerales a los diferentes ruidos, que son los
objetos, de tal manera que el atributo subyacente se refleje adecuadamente. Pero debemos tener
un agente que defina al atributo, asÚ que usamos uno o mÃs sujetos para juzgar la sonoridad de los estÚmulos. Los sujetos son entonces los agentes a travÕs de
los cuales determinamos los valores escalares que asignamos a los estÚmulos. El agente expresa, su juicio de cierta manera o modo, que es el conjunto real de
respuesta que se le permite usar. Esta es una manera ºtil de plantear el problema de la elaboraciµn de escalas;
sin embargo, como veremos aquÚ està exageradamente simplificado (como la mayorÚa de las formas que describen los problemas construir de escalas psicolµgicas).
Hay algunas tÕcnicas para elaborar escalas en que tanto los estÚmulos como los sujetos se ubican en sus escalas respectivas a partir de los mismos datos, asÚ
que los objetos y los agentes desempeþan papeles intercambiables dentro del mismo problema. Y hay otros casos en que las escalas para estÚmulos y las
respuestas se establecen a partir del mismo conjunto de datos y realmente desempeþan papeles intercambiables como objetos y modos.
No obstante, debe quedar claro que nos interesa hacer escalas para un atributo, una abstracciµn de la percepciµn ya sea de estÚmulos, de personas o incluso de
respuestas. Dado que nuestro interÕs es el atributo abstraÚdo, podemos confeccionarle una escala
fundÃndonos en una o mÃs de estas tres variables bÃsicas, algunas veces simultÃneamente, o por lo menos a partir del mismo conjunto de datos.
El problema de la generalidad. Existe otra razµn para que en nuestro esquema original de tres variables hayamos usado el tÕrmino sujetos y no agentes, la
cual ilustra un problema que se presenta en toda investigaciµn psicolµgica. En mayor grado que en otras ciencias, la psicologÚa siempre tiene que hacer frente
a y procurar contestar la cuestiµn de la generalidad del resultado de un experimento, generalidad que no siempre se refiere a una poblaciµn especificada
de individuos. Para elaborar la escala de sonoridad de los estÚmulos, podÚamos usar solamente un sujeto como agente, con un solo modo de respuesta; pero no lo
hacemos asÚ porque deseamos estar seguros de que la escala obtenida no es exclusivamente de nuestro sujeto. Empleamos, en consecuencia, varios sujetos, y
combinamos o promediamos los datos de ellos para tener la mayor generalidad posible que nos permitan los datos promedio. O, en su lugar, podemos buscar
diferencias entre los sujetos para determinar quÕ tan general es la aplicaciµn de la escala. Si
nuestro propµsito es establecer diferencias entre sujetos, entonces los objetos son a menudo los medios para establecer la generalidad; por ejemplo, si deseamos
saber si los sonidos parecen mÃs sonoros a una persona que a otra. Pero comºnmente nos desagradarÚa sacar tal conclusiµn con base en juicios acerca de
un solo estÚmulo. En vez de eso, desearÚamos saber si el sujeto A siempre estima los estÚmulos auditivos como mÃs sonoros de lo que le parecen al sujeto B. Por
tanto, pueden usarse los sujetos o los objetos para establecer la generalidad. En otros casos mÃs, deseamos establecer la generalidad a travÕs de las
respuestas, ya que la escala que obtenemos no debe ser ºnicamente de un conjunto particular de respuestas posibles. Por ejemplo, si se pide a los sujetos que
juzguen la brillantez de una luz, la escala que obtengamos debe ser la misma ya sea que use respuestas entre cero y diez o entre cero y cien.
Propiedades latentes y manifiestas de las escalas. Los datos obtenidos para elaborar una escala psicolµgica pueden usarse de muchas maneras; pero
existen diferencias en cuanto al modo cµmo puede elaborarse la escala, que son distintas a las que hemos estudiado; y una de las mÃs importantes es la del uso
de las propiedades latentes o manifiestas para elaborar esa escala. Las propiedades manifiestas de los datos, son, como lo indica el tÕrmino, las
propiedades evidentes fÃcilmente apreciables e interpretables. Las propiedades latentes son las que deben Õxtraerse de los datos, inherentes a ellos, pero no
perceptibles fÃcilmente. Las propiedades latentes son tan importantes como las manifiestas y quizÃs un poco mÃs. Las tÕcnicas de elaboraciµn de escalas
psicolµgicas se han inclinado cada vez mÃs hacia el uso de las propiedades latentes, por diversas razones.
Cuando distinguimos entre escalas basadas en propiedades manifiestas y latentes de los datos, nos desentendemos de si los datos mismos tienen propiedades
manifiestas: todos los datos las tienen. Nuestro interÕs se relaciona con las propiedades de mediciµn de la escala que elaboramos en conexiµn con las
propiedades de mediciµn de los datos manifiestos. Las escalas basadas en propiedades latentes tendrÃn de ordinario propiedades de mediciµn diferentes y a
menudo mÃs poderosas que las propiedades de mediciµn de las respuestas (los datos manifiestos). Indudablemente, el objetivo de la mayorÚa de las tÕcnicas de
elaboraciµn de escalas latentes es lograr parecidas propiedades eficaces de mediciµn. Existen tres aspectos importantes en la elaboraciµn de una escala
psicolµgica que ataþen a la cuestiµn de si tenemos una escala basada en propiedades manifiestas o latentes.
Lo naturaleza de las respuestas del sujeto. La primera y a menudo mÃs importante consideraciµn se refiere a la naturaleza de la respuesta que se espera del
sujeto. Podemos pedirle que emplee tipos de respuesta de escala nominal, ordinal, intervalar o aºn de razµn, y si pretendemos que aplique las propiedades
manifiestas de los datos entonces podemos construir una escala que no haga suposiciones de medida de mayor eficacia que las que se permitiµ usar al sujeto.
Por ejemplo, si pedimos simplemente a los sujetos que ordenen varios estÚmulos por preferencia estÕtica, entonces podemos construir una escala intervalar o de
razµn que se base en las propiedades manifiestas de estos datos. La propiedad supuesta de la respuesta. No es necesario, por supuesto, que el
experimentador suponga que las respuestas tienen las propiedades de mediciµn que se le dijo al sujeto que usara. Si se le indicµ al sujeto que hiciera juicios de
razµn de la brillantez de las luces, no necesitamos suponer que pudo hacerlo, podÚamos suponer que sµlo fue capaz de hacer juicios intervalares o quizÃs sµlo
ordinales. Lµgicamente, es posible suponer las propiedades mÃs poderosas del continuo de la respuesta que usµ el sujeto, aunque rara vez se hace. Por
ejemplo, podemos pedirle al sujeto que ordene un conjunto de estÚmulos y suponer luego que en realidad las posiciones de orden representan una escala de
intervalo. Si lo hiciÕramos asÚ estarÚamos entonces explorando una propiedad latente de los nºmeros, ya que la propiedad intervalar no era evidente.
La propiedad supuesta de la escala. La escala elaborada finalmente no tendrà por fuerza la misma propiedad de medida que las respuestas usadas por el sujeto, y
ni siquiera las asumidas por el experimentador. Como adelante veremos, se puede suponer solamente que el sujeto dio respuestas ordinales, pero que a partir de
estas se elaborµ una escala de intervalo, si se hacen algunas suposiciones adicionales al tratar los datos.
Cuando la naturaleza de la respuesta, sus propiedades asumidas y la propiedad supuesta de la escala son congruentes, tenemos entonces una escala basada en
propiedades manifiestas de los datos. Si no son congruentes, entonces la escala se basa en algºn grado en propiedades latentes. Debe estar claro que la
distinciµn entre escalas latentes y manifiestas no es una dicotomÚa definida; existen mÃs bien todos los grados de variaciµn, desde escalas basadas total y
sencillamente en datos manifiestos, incluyendo escalas basadas parcialmente en propiedades latentes de los datos, hasta escalas que tienen poca relaciµn con
propiedades evidentes o manifiestas de los datos. ¢Por quÕ escalas de propiedad latente?
La elaboraciµn de una escala basada en datos manifiestos es bÃsicamente tan simple y directa que podemos preguntarnos por quÕ se usan tÕcnicas de propiedad
latente. Si podemos preguntar directamente a un sujeto quÕ tan fuerte es un sonido o quÕ tan bello es un Ãrbol, ¢por quÕ no hacerlo asÚ? y ¢por quÕ no se ha
hecho? La respuesta se encuentra en la misma naturaleza del problema de elaboraciµn de escalas psicolµgicas.
En la elaboraciµn de esta clase de escalas tratamos de asignar numerales que reflejen las propiedades de un atributo, la fracciµn que no podemos observar
directamente. Por consiguiente, cuando usamos datos manifiestos damos por supuesta la cuestiµn, quizà la mÃs importante de todas, de si en efecto existe
tal atributo, y en ese caso, quÕ propiedades tiene. El uso de propiedades manifiestas de la respuesta requiere un par de suposiciones muy poderosas.
Necesitamos suponer que existe el atributo y que tiene las propiedades de mediciµn que le asignamos, y tambiÕn suponer que estas propiedades pueden ser
reflejadas directamente por el sujeto en su respuesta manifiesta. No es suficiente afirmar que tenemos una escala para un atributo, tan solo
porque podamos demostrar una relaciµn funcional entre un conjunto de objetos y un conjunto de valores escalares. Antes que nada, debemos determinar cuÃles son
las propiedades del atributo mismo (por ejemplo, ¢tiene un cero absoluto? ); y despuÕs quÕ numerales asignaremos a los objetos que posean tal propiedad. Es
decir, debemos establecer una relaciµn entre el atributo mismo y algunos aspectos de la escala de los nºmeros.
Las escalas basadas en propiedades latentes de los datos son muy semejantes a las construcciones hipotÕticas o variables interventoras (Green, 1954); se
construye matemÃticamente para explicar relaciones entre otras variables. Rara vez estas escalas tienen propiedades mÃs eficaces que las de una escala de
intervalo, pero es frecuente que esta propiedad se garantice en forma significativa. Una escala basada en datos manifiestos en que las respuestas
tienen propiedades de razµn con frecuencia parece tener estas propiedades; pero la mayor eficacia de la escala de razµn se logra a un costo considerable. Rara
vez hay evidencia de la significaciµn del atributo asumido. La mayorÚa de las tÕcnicas de escalas latentes han incorporado operaciones
convergentes experimentales o matemÃticas (Garner, Hake y Eriksen, 1956). Las operaciones convergentes sirven para comprobar la legitimidad del concepto.
Porque, despuÕs de todo, un atributo (por definiciµn no es observable directamente) es justamente eso, un concepto, y un concepto carece de
significado a menos que sea abstracto y general. Identificar un concepto a partir de una sola operaciµn experimental o matemÃtica es establecer la
significaciµn por mandato, procedimiento que no es aceptable cientÚficamente. Las tÕcnicas latentes proporcionan asÚ mayor generalidad, aunque a costa del
alcance de la medida. LA SEGURIDAD EN AVIACIÆN: IMPORTANCIA DEL FACTOR HUMANO. XVII
TRATAMIENTO MUESTRAS Medidas en que las inferencias se hacen a partir de la observaciµn de conducta manifiesta.
Muchos investigadores han seþalado la conveniencia de usar medidas en que la
conducta manifiesta hacia miembros de una clase de objetos sirva como base de inferencias sobre la actitud hacia dicha clase de objetos. Como sucede con las
medidas hechas por medio de informes sobre sÚ mismo, la base de inferencia es clara; y todas las definiciones de actitud especifican quÕ conducta puede
tomarse como indicador de actitud. Como en el caso de las medidas de autoinforme, la suposiciµn comºn es que hay una correspondencia simple entre el carÃcter de
la conducta y el carÃcter de la actitud subyacente, por ejemplo, que la conducta amistosa hacia un miembro de una clase dada de objetos indica una actitud
favorable hacia tal clase de objetos. De este tipo de medidas ha habido un desarrollo menor que de medidas de informes
sobre sÚ mismo. Las situaciones capaces de producir conductas hacia un objeto actitudinal son mÃs difÚciles de inventar y estandarizar, a la vez que requieren
mÃs tiempo y es mÃs onerosa su aplicaciµn; y no asÚ con las medidas hechas por medio de informe sobre sÚ mismo. Aunque se han inventado algunas medidas de este
tipo, no se han usado lo suficiente para probar su fuerza y debilidad especÚficas, ni para estimular los esfuerzos por corregir sus defectos. Sin
embargo, el anÃlisis de sus caracterÚsticas proporciona medios para estimar su probable susceptibilidad a influencias diferentes de la actitud y las
posibilidades de reducir tal susceptibilidad.
Hasta ahora, el desarrollo de las medidas conductuales ha seguido tres
orientaciones generales. Una consiste en enfrentar a los sujetos a situaciones estandarizadas, cuyos arreglos se ocultan a dichos sujetos, con el fin de que
crean entonces que sus conductas tendrÃn consecuencias. En tales situaciones, el objeto actitudinal se representa de manera diferente a la presencia efectiva de
miembro de la clase de objetos. Por ejemplo, puede pedÚrsele a los sujetos que firmen una peticiµn en favor de un instructor que fue despedido por pertenecer
al partido comunista; que contribuyan con dinero al mejoramiento de las condiciones de los trabajadores migratorios; que indiquen si estarÚan dispuestos
a tener por compaþero de cuarto a un negro. DeFleur y Westie (1958) se propusieron establecer una medida de esta clase que se adaptara a diferentes
situaciones de prueba. En su procedimiento, que era parte de un programa mÃs extenso de investigaciµn, los sujetos blancos vieron varias transparencias que
presentaban a un joven negro y a una joven blanca, o a un joven blanco y a una joven negra, en una situaciµn social; los sujetos describieron las fotografÚas y
contestaron preguntas concretas acerca de ellas. Al final de una entrevista que siguiµ a esta sesiµn se introdujo el procedimiento de medida que se estÃ
describiendo. DeFleur y Westie describen el procedimiento como sigue: se dice al sujeto que se necesita otro grupo de transparencias semejantes para
investigaciones posteriores; se le pregunta si estarÚa dispuesto a ser fotografiado junto con un negro de sexo opuesto y despuÕs se le da "un contrato
de cesiµn de derechos por una fotografÚa estÃndar", que especifica la diversidad de usos que se podrÚa dar a esa fotografÚa, y que van desde experimentos de
laboratorio, donde solamente seria vista por sociµlogos profesionales, hasta campaþas de publicidad en escala nacional que abogarÚan por la integraciµn
racial. Finalmente se pidiµ a cada sujeto que autorizara con su firma los distintos usos de la fotografÚa. Los mencionados investigadores informaron que
los sujetos "percibieron uniformemente la situaciµn conductual propuesta como una peticiµn muy realista".
Semejantes medios difieren de las mÕdidas basadas en informes sobre sÚ mismo
cuyo contenido es similar en que, en las medidas conductuales, el sujeto realiza efectivamente la conducta (firma una peticiµn, hace una aportaciµn, etc.), o se
le hace creer que su aceptaciµn traerà consecuencias reales (se le pide posar para una fotografÚa que tendrà usos especÚficos, se le asigna a un negro de
compaþero de cuarto, etc.). Otro procedimiento consiste en presentar al sujeto una situaciµn preparada de
antemano y se le pide que desempeþe un papel, quizà que se comporte como lo harÚa en una situaciµn semejante de la vida real, o bien que asuma la parte de
alguien o que actºe de una manera especÚfica. Stanton y Litwak (1955) presentaron a padres adoptivos reales y potenciales situaciones de tensiµn
interpersonal en las que se les instruyµ para que se comportaran de una manera determinada (definida de tal modo que no manifestaran tipos especÚficos de
conducta indeseable o neurµtica); por ejemplo, en una escena se instruyµ al sujeto para que desempeþara el papel de un hombre casado, que come con sus
padres; el investigador, que hace el papel de padre del sujeto, trata a su hijo como un niþo, critica a su esposa y la ofende. Nuestros investigadores
encontraron que las estimaciones basadas en media hora de desempeþo del papel fueron mejores pronosticadores de la conducta de los sujetos como padres
adoptivos (evaluados por trabajadores sociales que habÚan mantenido contacto con ellos) que las estimaciones basadas en 12 horas de entrevista intensiva con un
trabajador social adiestrado. Stanton, Back y Litwak (1956) informaron que un procedimiento de desempeþo de papeles tuvo Õxito en el descubrimiento de los
lÚmites de los sentimientos positivos y negativos de parte de los habitantes de barrios bajos en Puerto Rico. Estos investigadores hicieron hincapiÕ en la
importancia de diseþar la escena especÚficamente para producir respuestas correspondientes a la conducta o actitud particular en que estÕ interesado el
investigador. Un tercer enfoque conductual, empleado en el estudio de las actitudes hacia grupos
sociales, es pedir que se hagan selecciones sociomÕtricas entre individuos donde figuren algunos miembros del grupo objeto, de la actitud preferiblemente en
circunstancias que induzcan a creer a los participantes que tales selecciones tendrÃn consecuencias en la forma de asignar subsecuentemente determinada
situaciµn. Las primeras aplicaciones de esta tÕcnica al estudio de las actitudes intergrupales fueron hechas en los estudios de Moreno (1943) y de Criswell
(1937, 1939), donde las estructuras de las selecciones hechas por niþos escolares fueron analizadas basÃndose en el desarrollo de divisiones entre
lÚneas raciales. MÃs tarde, las tÕcnicas sociomÕtricas se han usado en la investigaciµn para evaluar los efectos de ciertas experiencias sobre las
actitudes (por ejemplo, Mann, 1959a; Mussen, 1950a, 19506) y de las relaciones entre diferentes aspectos de las actitudes (por ejemplo, Mann, 19596).
Existen diferencias entre estos tres tipos de medidas conductuales -situaciones
que aparecen al sujeto como no preparadas, desempeþo de papeles y selecciones sociomÕtricas- en caracterÚsticas que afectan la probabilidad de que las
respuestas manifiestas correspondan a respuestas que se presentarÚan si el sujeto no procurara presentar (a los otros o a sÚ mismo) cierta imagen de Õl
mismo. Primero, consideremos el grado en que su propµsito es visible al sujeto. En el grado en que las situaciones pretendidamente no preparadas son aceptadas
como genuinas, el sujeto no las verà como diseþadas para obtener informaciµn acerca de sus actitudes; asÚ, se elimina una posible fuente de presiµn para dar
respuestas que probablemente se consideren deseables. Sin embargo, las implicaciones de su conducta al revelar ciertas caracterÚsticas pueden
evidenciarse a Õl; aun cuando acepte como genuina una pregunta acerca de su disposiciµn a posar junto con un negro o a tener como compaþero de cuarto a un
negro, puede darse cuenta de que una respuesta positiva lo presentarà como no prejuiciado y una respuesta negativa como prejuiciado. AsÚ, pese a percatarse de
que està siendo examinado, el individuo puede ser motivado a dar una respuesta que difiera de su respuesta espontÃnea y privada, para aparecer al examinador
como no prejuiciado o mantener la imagen de sÚ mismo como la de una persona cuyo comportamiento carece de prejuicios. El mÕtodo de selecciµn sociomÕtrica
parecerÚa ser semejante en estos aspectos, aunque acaso se suponga que, en ausencia de influencias especiales que llaman la atenciµn hacia la pertenencia
de grupo racial o Õtnico, las implicaciones de las selecciones son probablemente menos aparentes. En el caso del desempeþo de papel, el grado en que el propµsito
de la situaciµn y las implicaciones de las respuestas son claras depende, presumiblemente, de lo convincentemente que pueda presentarse la situaciµn como
medida de alguna otra caracterÚstica, tal como la capacidad de actuar.
Todos estos procedimientos conductuales tienen caracterÚsticas cuya operaciµn puede facilitar responder de manera que pueda considerarse indeseable. En muchas
situaciones, es posible justificar una respuesta negativa sobre bases neutrales o aceptables: uno no confÚa en firmar peticiones o no le gusta que le tomen
fotografÚas o prefiere a las personas A y B y no a X y Y porque comparten su interÕs por la mºsica. O, en la situaciµn de desempeþo de papeles, su conducta
se conforma no por sus propias reacciones hacia el objeto actitudinal sino por su interÕs en los requerimientos dramÃticos de la situaciµn. (Sin embargo, en el
grado en que estas explicaciones alternas sean posibilidades reales, se introducen otros problemas acerca de la interpretaciµn de la conducta como
indicador de la actitud en que estÕ interesado el investigador).
Algunas caracterÚsticas de los mÕtodos conductuales pueden reducir la probabilidad de que el individuo modifique su conducta a modo de ofrecer una
imagen aceptable de sÚ mismo. Cuando se espera que las respuestas tengan consecuencias reales, la previsiµn de tales consecuencias puede contrabalancear
el deseo de causar una buena impresiµn. En un cuestionario de distancia social, si uno desea presentarse (al examinador, a uno mismo o a ambos) como no
prejuiciado, hay poca presiµn efectiva en contra de la afirmaciµn consistente en que uno estarÚa dispuesto a trabajar con un negro o a tener un compaþero negro
de cuarto; pero si la pregunta se ubica dentro de un contexto en el que una contestaciµn positiva se considere conducente a la asignaciµn de un negro como
compaþero de trabajo o de cuarto, uno necesita ponderar su disposiciµn a aceptar esa consecuencia, contrastÃndola con el deseo de aparecer como no prejuiciado.
En el desempeþo de papeles, la presiµn para dar respuesta rÃpida a situaciones de estÚmulo no previstas, probablemente disminuya el control consciente de la
conducta dirigida a producir la impresiµn deseada. Al enfrentarse a la necesidad de hacer o decir algo para que la situaciµn continºe, el individuo posiblemente
no tenga tiempo de considerar la impresiµn que produce; en la medida que esto suceda, puede considerarse que este procedimiento disminuye la selecciµn
consciente que de su respuesta hace el individuo. Por tanto, las medidas conductuales parecen menos suceptibles de distorsiµn de
respuesta que las simples medidas con autoinformes cuando se trata de presentar cierto cuadro de sÚ mismo. Pero son tan susceptibles por lo menos como los
informes de sÚ mismo a los efectos de otras influencias extraþas. Algunas veces se ha sugerido que el modelo de medidas conductuales estarÚa formado por
situaciones aparentemente no preparadas en las que se encuentre presente un miembro de la clase de objetos. Pero es claro que en situaciones de la vida
diaria (a las que este modelo procura aproximarse) la conducta no està determinada exclusivamente por la actitud hacia el presunto objeto actitudinal.
En el caso de la conducta hacia grupos minoritarios, la costumbre social es, por ejemplo, un determinante importante; en las comunidades con sistemas de
transportes segregados, casi todos los blancos -independientemente de sus actitudes hacia los negros o hacia la segregaciµn- se sientan en la secciµn de
blancos, mientras que en las comunidades con sistemas de transporte no segregados, muy pocos blancos- independientemente de sus actitudes- rehusan
sentarse junto a los negros. Otros valores pueden anular las actitudes hacia el presunto objeto; un individuo que sienta repulsiµn a comer con negros, puede
hacerlo, no obstante, porque acaso crea que los ideales de la democracia, los principios religiosos de hermandad o la posiciµn de los Estados Unidos en el
mundo requieren que todos los hombres sean tratados como iguales. Finalmente, pueden predominar otras caracterÚsticas de los objetos individuales sobre su
identificaciµn Õtnica en la determinaciµn de su respuesta a ellos. AsÚ, LaPiere (1934) concluyµ que los factores que mÃs influyeron en la conducta del personal
del hotel y del restaurante, hacia la pareja china con quien viajµ, "no tenÚa nada que ver con la raza"; mÃs bien, fue la calidad y condiciones de su vestido,
la apariencia de su equipaje, su limpieza y pulcritud y sobre todo sus maneras agradables y su seguridad lo que determinµ las reacciones. Observaciones como
esta sugieren que, en el grado en que uno estÕ interesado en explorar disposiciones generalizadas hacia un grupo determinado, mÃs bien que predecir la
conducta en situaciones complejas, las medidas conductuales que requieren respuesta a una representaciµn simbµlica del grupo pueden estar menos sujetas a
la influencia de factores extraþos que las medidas que requieren respuesta a miembros del grupo que estÃn presentes fÚsicamente.
Campbell (1961) ha propuesto un procedimiento para usar medidas conductuales basadas en la premisa de que situaciones diferentes tienen distintos umbrales
para la manifestaciµn de conducta hostil, de evitaciµn o discriminatoria. Indica que, para obtener testimonios sobre la actitud de un individuo, es necesario
colocarlo en varias situaciones que difieran en umbrales; por ejemplo, situaciones que vayan desde comer con un negro en un restaurante de hombres de
negocios (que se supone es una situaciµn con un umbral bajo para conducta no discriminatoria, es decir, que es fÃcil comportarse en ella de una manera no
prejuiciada), hasta rentar la propia casa a un negro (que se supone tiene un umbral alto para conducta no discriminatoria). La situaciµn de umbral mÃs bajo
en la que un individuo exhiba conducta discriminatoria indicarÚa su posiciµn en una escala de actitud con respecto al grupo en cuestiµn. Semejante procedimiento
serÚa efectivo para tener en cuenta las presiones que sean constantes en todos o casi todos los individuos; pero nos parece que no eliminarÚa los efectos de las
diferencias de intensidad, en diferentes individuos, de influencias como el interÕs por la aprobaciµn social, otros valores considerados tambiÕn intrÚnsecos
de la situaciµn, etc.
Medidas en que las inferencias se obtienen de la reacciµn individual a, o de, la interpretaciµn de estÚmulos estructurados parcialmente.
La caracterÚstica comºn de las tÕcnicas de esta categorÚa es que, aun cuando es probable que no se procure disimular la referencia al objeto actitudinal, no se
le pide al sujeto que exprese sus reacciones directamente; està describiendo, ostensiblemente, una escena, un personaje o la conducta de una tercera persona.
Se le puede presentar la fotografÚa de un miembro de la clase del objeto (generalmente una persona de determinado grupo social) para despuÕs pedirle que
describa sus caracterÚsticas; o se le puede presentar una escena en la que estÕn presentes los miembros de la clase del objeto y pedirle que la describa, que
cuente una historia acerca de ella, que describa la conducta de uno de los personajes, etc. El material de estÚmulo puede ser verbal y no fotogrÃfico; por
ejemplo, se le puede pedir al sujeto que complete una oraciµn referente a una tercera persona hipotÕtica.
Las bases de inferencia acerca de las actitudes son las comunes a todos los tests proyectivos: las suposiciones de que la percepciµn de estÚmulos que no
estÃn estructurados claramente resulta influida por las propias necesidades y disposiciones del que percibe; que al proporcionarle una explicaciµn o
interpretaciµn para la cual el estÚmulo presentado no ofrece una seþal clara, el sujeto debe extraer de su propia experiencia o disposiciones o de sus propias
definiciones lo que serÚa probable o apropiado; que, al pedirle que atribuya formas de conducta a los demÃs, particularmente en condiciones de respuesta
rÃpida, la fuente mÃs asequible de hipµtesis es la propia disposiciµn de respuesta del individuo. Como en el informe sobre sÚ mismo y en los tests
conductuales, la suposiciµn comºn es que la respuesta expresada corresponde directamente a la actitud del individuo; por ejemplo, que la atribuciµn de
caracterÚsticas deseables a un miembro de determinado grupo representa una actitud favorable hacia ese grupo, que la interpretaciµn de una escena en la que
hay hostilidad hacia un miembro de, un grupo dado representa una actitud hostil hacia el grupo, que la atribuciµn de una respuesta positiva (o negativa) a una
tercera persona hipotÕtica con respecto a determinado objeto refleja una disposiciµn positiva (o negativa) hacia el objeto en cuestiµn.
Una razµn importante para el desarrollo de tales tÕcnicas es la suposiciµn de que, al disimular el propµsito del instrumento y las implicaciones de las
respuestas, disminuye la probabilidad de distorsiµn de las respuestas para presentar cierto cuadro de sÚ mismo. Se presentan al sujeto no como medidas de
actitud sino como tests de imaginaciµn, fluidez verbal, capacidad para juzgar el carÃcter, la sensibilidad social o alguna otra caracterÚstica semejante. Tanto
como el sujeto acepte estas explicaciones, es de suponerse que no solamente desconoce el propµsito del test sino tambiÕn que sus respuestas implican que
revela sus propias actitudes. Aun cuando el sujeto se dÕ cuenta de que està expresando su propia actitud, se presume que puede ser mÃs fÃcil expresar
opiniones que pueden considerarse indeseables cuando uno no las reconoce explÚcitamente como propias. En algunos casos, las preguntas no son evaluativas;
de ahÚ que las implicaciones de una u otra respuesta no se hagan probablemente evidentes al sujeto; por ejemplo: "¢QuÕ està haciendo el individuo de color que
està en la esquina? " (Horowitz y Horowitz, 1938).
Sin embargo, se han planteado preguntas acerca de la validez de la suposiciµn de que las respuestas, aun las espontÃneas y no distorsionadas, reflejan la propia
actitud del individuo hacia el objeto. Pero, aunque parece haberse establecido que la respuesta de un individuo puede reflejar su propia disposiciµn, no es
cierto que necesariamente la realice. En una escena en la que son ambiguos los papeles del negro y del blanco, el individuo que describe al negro como criado
puede reflejar asÚ su propia disposiciµn devaluativa hacia los negros; por otro lado, puede informar sencillamente de la organizaciµn mÃs comºnmente observada
en nuestra cultura. De manera semejante, las respuestas que atribuye a una tercera persona hipotÕtica pueden basarse ya sea en su propia disposiciµn de
respuesta o en su estimaciµn de cµmo reaccionarÚa la mayorÚa de la gente en tal situaciµn. Las tentativas por obtener
testimonios sobre si las respuestas a los instrumentos de este tipo reflejan en realidad las propias actitudes del individuo han seguido dos direcciones: examen
de la correspondencia entre las estimaciones basadas en estas medidas y las basadas en otras medidas (por lo comºn del tipo de informe de sÚ mismo); y
examen de datos obtenidos de instrumentos de esta clase basÃndose en las predicciones acerca de las estructuras de los resultados.
Varios estudios han encontrado correspondencia significativa entre resultados de medidas de este tipo y puntuaciones en medidas de informes de sÚ mismo.
Proshansky (1943) encontrµ correlaciones altas entre puntuaciones basadas en una escala estÃndar de informes sobre sÚ mismo para medir la actitud hacia el
trabajo organizado y las puntuaciones basadas en descripciones de cuadros ambiguos, de exposiciµn breve y de situaciones sociales relacionadas.
Riddleberger y Motz (1957) encontraron que los sujetos con puntuaciµn alta y los de puntuaciµn baja en una medida con informes sobre sÚ mismo, de actitud hacia
los negros, diferÚan en sus explicaciones acerca de cµmo habÚan entablado relaciµn los miembros de un grupo interracial dibujado. Sommer (1954), con una
forma modificada de la adaptaciµn de Brown (1957), del test de frustraciµn de dibujos de Rosenzweig, pudo identificar con gran Õxito no solamente a los
individuos que calificaron alto y a los que calificaron bajo en una escala de informe sobre sÚ mismo, de actitud hacia los negros, sino tambiÕn a un subgrupo
al que se habÚa instruido para que respondiera al test de frustraciµn de cuadros como si no estuviera prejuiciado, aunque sus puntuaciones en el informe sobre sÚ
mismo eran desfavorables. Sin embargo, en vista de la suposiciµn de que una caracterÚstica importante de
los tests de este tipo es su relativa falta de susceptibilidad, comparada con la de medidas de informes de sÚ mismo, a los efectos de presentar cierta imagen de
sÚ mismos, su correspondencia con puntuaciones basadas en medidas de informe de sÚ mismo, es un criterio dudoso. Getzels (1951), admitiendo este hecho, planteµ
el problema al predecir las condiciones en las que la complementaciµn rÃpida de frases en tercera persona diferirÚa de la complementaciµn, hecha por los mismos
sujetos, de las mismas frases presentadas en primera persona. Hizo dos predicciones: a) que las respuestas en primera y tercera persona diferirÚan en
los reactivos sujetos a normas sociales firmes que no estuvieran completamente internalizadas por todos los miembros del grupo; y que no diferirÚan en los
reactivos libres de tales normas; y b) que en el caso de los primeros reactivos, las contestaciones de mayor aceptaciµn social serÚan dadas en la forma de
primera persona mÃs que en la de tercera persona. Ambas predicciones fueron comprobadas claramente. Getzels reconociµ la posibilidad de que las respuestas
en la forma de tercera persona se basaran en estimaciones de cµmo responderÚa la mayorÚa de las personas antes que en las disposiciones de respuesta de los
propios sujetos. De conformidad con esto, pidiµ a los sujetos que estimaran cµmo responderÚa la mayorÚa de las personas a los reactivos acerca de los negros, y
no encontrµ diferencia entre el promedio de las estimaciones hechas por aquellos cuyas respuestas de tercera persona habÚan sido favorables y el de aquellos
cuyas respuestas de tercera persona habÚa sido desfavorable.
Varias tÕcnicas en que interviene la percepciµn -en sentido literal- de material ambiguo o inestructurado pueden considerarse dentro de esta categorÚa. Por
ejemplo, varios psicµlogos han estado investigando la posible relaciµn de las actitudes con la percepciµn de estÚmulos presentados en condiciones
estereoscµpicas de rivalidad binocular. Bagby (1957), al presentar pares de tarjetas que diferÚan en contenido cultural (por ejemplo, un torero y un jugador
de bÕisbol) a sujetos de MÕxico y de los Estados Unidos, encontrµ que los mexicanos tendÚan a ver la tarjeta de contenido mexicano y los norteamericanos
las de contenido familiar en los Estados Unidos. Pettigrew, Alport y Barnette, (1958), al presentar a residentes de SudÃfrica pares de fotografÚas de
individuos de diferentes grupos raciales, encontraron que los africanos se desviaron mÃs consistentemente de otros grupos en sus respuestas, emplearon en
exceso las categorÚas de "europeo" y "africano" y muy poco las de "negro" o "indio". Un estudio
de Bray (1950) hizo uso de material visual no estructurado de una manera diferente. Haciendo uso del hallazgo de Sherif (1935) de que las estimaciones de
movimiento en el fenµmeno autocinÕtico son influÚdas notablemente por las estimaciones hechas por otros, Bray investigµ los efectos de estimaciones de
compaþeros que se identificaron como miembros de grupos minoritarios. Sostuvo la hipµtesis de que el grado y direcciµn de tales efectos estarÚa influido por la
actitud del sujeto hacia el grupo minoritario. AquÚ, el material perceptual no estructurado no se referÚa al objeto actitudinal, sino sencillamente
proporcionaba la oportunidad de expresar indirectamente una respuesta al objeto actitudinal, el miembro del grupo minoritario presente.
Persisten, pues, los problemas acerca de la naturaleza de las inferencias que pueden extraerse. Bray, por ejemplo, no encontrµ la relaciµn directa que habÚa
predicho entre la actitud hacia el grupo minoritario (medida por escalas de informes de sÚ mismo) y las respuestas a las estimaciones de los miembros del
grupo minoritario. En el caso de la rivalidad binocular, ¢de quÕ manera, en caso de haberla, la actitud influye en la percepciµn? ¢Ve uno la fotografÚa de
contenido mÃs familiar? ¢Ve uno al miembro del grupo racial hacia el que se siente mÃs a favor o hacia el que es mÃs hostil o se siente mÃs temeroso?
Preguntas como Õstas seþalan la necesidad de investigaciones ulteriores sobre la utilidad de estas tÕcnicas como medidas de actitud y las direcciones de
investigaciµn potencialmente fructÚferas acerca de la relaciµn entre las actitudes y la respuesta a varias clases de materiales en diferentes
condiciones.
Medidas en que las inferencias se extraen de la ejecuciµn de tareas "objetivas" Los
procedimientos de esta categorÚa presentan al sujeto tareas concretas a realizarse; se presentan como tests de informaciµn o capacidad o simplemente
como tareas que deben hacerse. La suposiciµn comºn a todas ellas es que la ejecuciµn puede ser influÚda por la actitud y que una desviaciµn sistemÃtica en
la ejecuciµn refleja la influencia de la actitud.
Por ejemplo, se puede pedir al sujeto que memorice material, parte del cual es favorable al objeto actitudinal, parte desfavorable y parte quizà neutral o no
relacionado con dicho objeto. La suposiciµn consiste en que el material anÃlogo a la posiciµn del propio sujeto se aprenderà mÃs rÃpidamente y se recordarà por
mÃs tiempo. Se ha obtenido comprobaciµn empÚrica de esta suposiciµn; por ejemplo, en un estudio de Levine y Murphy (1943), en el que se empleµ material
acerca de la Uniµn SoviÕtica y en otro de Jones y Kohler (1958) con aseveraciones acerca de la segregaciµn. O se le da al sujeto un test de
"informaciµn", en el que por lo menos algunos de los reactivos se refieran al objeto actitudinal y no tengan respuestas correctas o Õstas sean tan
desconocidas que pueda suponerse que, si acaso, unos cuantos sujetos conocerÃn las contestaciones acertadas; se proporcionan respuestas alternas que se cree
indican disposiciones relativamente favorables o desfavorables hacia el objeto. En este caso, la suposiciµn es de que cuando el sujeto es forzado a adivinar en
preguntas claramente referentes a hechos precisos, es probable que escoja la alternativa mÃs compatible con su propia disposiciµn actitudinal. TambiÕn esta
suposiciµn se apoya en evidencias empÚricas; por ejemplo, los estudios de Hammond (1948) y Weschler (1950) acerca de las actitudes hacia el trabajo y
hacia Rusia, y de Rankin y Campbell (1955) acerca de la actitud hacia los negros. O bien la tarea puede consistir en un test de "razonamiento", en que se
presentan silogismos u otras formas lµgicas y se pide al sujeto que indique cuÃl de varias conclusiones puede extraerse correctamente. Los reactivos referentes
al objeto actitudinal estÃn acompaþados por reactivos semejantes de contenido neutral o abstracto; la calificaciµn se hace conforme al nºmero y direcciµn de
los errores en los reactivos correspondientes a la actitud en comparaciµn con los reactivos de control. La suposiciµn reside en que el razonamiento puede
estar dominado por la disposiciµn actitudinal y asÚ los errores en los reactivos pertinentes a la actitud reflejan la propia posiciµn del individuo, cuando son
contestados correctamente los reactivos paralelos neutrales. Watson (1925), Morgan (1945) y Thistlethwaite (1950), entre otros, han desarrollado
instrumentos de este tipo. Thistlethwaite encontrµ diferencias significativas entre los estudiantes universitarios del norte y del sur en la frecuencia de
errores en reactivos referentes a negros (en comparaciµn con los errores en los reactivos neutrales) y ninguna diferencia correspondiente en reactivos acerca de
judÚos, mujeres o patriotismo. Otras medidas hacen hincapiÕ en el material que va a ser juzgado o en el
resultado que se va a lograr y no en la capacidad de ejecuciµn. Por ejemplo, se pide al sujeto que clasifique reactivos acerca del objeto actitudinal fundÃndose
en su posiciµn sobre una escala de favorabilidad-desfavorabilidad, con el fin expreso de que ayude en la elaboraciµn de una escala de Thurstone. En este caso,
la suposiciµn es que la propia actitud del evaluador hacia el objeto particularmente si es extrema -influye en sus juicios acerca de la favorabilidad
de las aseveraciones acerca del objeto. No obstante la creencia inicial de que las estimaciones de reactivos en las escalas de Thurstone no son afectadas por
las propias actitudes de los evaluadores, varios estudios recientes (por ejemplo, Hovland y Sherif, 1952) han encontrado que sÚ existen tales efectos.
Parece razonable suponer que la mayorÚa de los sujetos acepta estas tareas por su valor aparente; se presume que solo quien tenga un conocimiento mÃs que
ordin4rio de las tÕcnicas de investigaciµn de las ciencias sociales conocerÚa sus implicaciones actitudinales. Hay entonces las bases suficientes para asumir
que son relativamente invulnerables a la distorsiµn de querer presentar la imagen deseada de sÚ mismo.
Hay, sin embargo, objeciones acerca del carÃcter de las inferencias obtenidas. Cuando un sujeto presenta distorsiµn notable y consistente, se puede inferir que
tiene una actitud hacia el objeto lo bastante fuerte para afectar su ejecuciµn. Pero cuando tal distorsiµn no es consistente, ¢inferimos de ello que su actitud
no es fuerte o no es consistente? En otras palabras, ¢quÕ tan sensibles son esas medidas? ¢Es posible que los individuos con actitudes equivalentes difieran en
el grado en que su ejecuciµn en semejantes tareas està influida por esas actitudes? Otro
problema es el relativo a la direcciµn en que la actitud influye en la respuesta e, inversamente, en el carÃcter de la inferencia que se obtiene de determinada
respuesta. Las respuestas pueden reflejar deseos o temores; un miembro del partido comunista puede sobreestimar el nºmero de comunistas en los Estados
Unidos; pero tambiÕn puede hacerlo un miembro de la Sociedad John Birch. Una persona que subestima el nºmero de mÕdicos negros en los Estados Unidos puede
hacerlo porque cree que los negros no tienen la capacidad para ser mÕdicos, o porque cree que las oportunidades para que los negros obtengan preparaciµn
mÕdica son limitadas. Los juicios de favorabilidad o desfavorabilidad de las aseveraciones estÃn
sujetos a un problema similar de interpretaciµn. Hovland y Sherif (1952), empleando reactivos acerca de los negros, encontraron que las estimaciones
hechas por sujetos negros y por sujetos blancos que apoyaban activamente la integraciµn racial, diferÚan de las estimaciones hechas por sujetos "promedio",
y por blancos racistas. No obstante, otros investigadores (por ejemplo, Manis, 1960; Weiss, 1959), empleando reactivos acerca de diferentes objetos
actitudinales, encontraron que los sujetos con actitudes extremas -ya sea favorables o desfavorables- presentaron estructuras semejantes de estimaciones,
que diferÚan de las hechas por sujetos con actitudes moderadas.
Como en la categorÚa anterior, estos problemas de interpretaciµn seþalan la necesidad de ser cuidadosos al inferir la actitud de un individuo a partir de un
solo test de esta clase; pero parece seþalar tambiÕn la probable utilidad de la investigaciµn empÚrica ulterior acerca de la relaciµn entre las puntuaciones
basadas en semejantes medidas y las basadas en tests que proporcionan otros principios de inferencia.
Otro grupo de medidas presentadas como tareas objetivas o tests de capacidad se enfoca hacia el grado en que el objeto actitudinal figura de manera destacada en
la organizaciµn que de su ambiente realiza el sujeto, es decir, su importancia para Õl. Las clases de datos apropiados para inferencia acerca de la importancia
de un objeto actitudinal difieren en parte de los tipos adecuados de inferencia acerca de la naturaleza o direcciµn de la actitud. Se han desarrollado
principalmente medidas de predominio con respecto a actitudes hacia grupos sociales. Son de dos tipos: tÕcnicas para evaluar la tendencia a clasificar a
los individuos con fundamento en su pertenencia al grupo y tÕcnicas para evaluar la tendencia a subordinar las diferencias individuales a la identificaciµn con
el grupo. Una tÕcnica para evaluar la tendencia a clasificar a los individuos por su
pertenencia de grupo, desarrollada por Horowitz y Horowitz (1938), puede presentarse como test de formaciµn de conceptos. Consiste en presentar al sujeto
series de fotografÚas de individuos que difieren en raza, sexo, edad y posiciµn socioeconµmica, y luego pedirle que seleccione las que "deban ir juntas". Por
ejemplo, un conjunto puede contener fotografÚas de tres muchachos blancos, una muchacha blanca y un muchacho negro. Si el sujeto contesta que la muchacha
blanca no pertenece al grupo, vÕase en esto una indicaciµn de que para dicho sujeto el sexo es una base de clasificaciµn mÃs importante que la raza; si
contesta que el muchacho negro no pertenece al grupo, se infiere que la raza es para Õl una categorÚa mÃs importante que el sexo.
Otra tÕcnica para evaluar la tendencia a clasificar los individuos segºn su pertenencia de grupo, presentada como test de memoria, implica la agrupaciµn, en
el recuerdo, de sÚmbolos verbales, para lo cual se proporcionan principios clasificatorios alternos. Esta tÕcnica se apoya en el hallazgo realizado en
estudios de conducta verbal de que cuando se presentan al azar palabras sacadas de diferentes categorÚas, los sujetos tienden a recordarlas en grupos; se
recuerdan juntas palabras diferentes que representen una categorÚa dada aunque no estÕn prµximas en la lista presentada. Para estudiar el predominio de la raza
como base de clasificaciµn, se presentarÚan al sujeto, en orden aleatorio, los nombres de personas de diferentes categorÚas ocupacionales, por ejemplo,
jugadores de bÕisbol, mºsicos, polÚticos, actores; uno de los nombres en cada categorÚa corresponderÚa a un negro. El grado en que se agrupan en el recuerdo
los nombres de negros proporciona la base de inferencia en cuanto al predominio de la raza como fundamento para clasificar a los individuos.
Una medida de la tendencia a subordinar las diferencias individuales a la identificaciµn de grupo, desarrollada por Horowitz y Horowitz (1938), consiste
en presentar al sujeto varias fotografÚas de individuos de diferentes grupos Õtnicos y pedirle que identifique, en un gran nºmero de fotografÚas, a los que
ya ha visto. La tarea se presenta como un uso de la percepciµn, la memoria o ambas. La calificaciµn se hace conforme a la proporciµn de respuestas correctas
a los individuos de determinado grupo social dado en comparaciµn con la proporciµn de respuestas correctas sobre individuos de otros grupos. En este
caso, la inferencia es que la exactitud para identificar o no fotografÚas de individuos de un grupo social dado, que ya se han visto anteriormente, disminuye
con la tendencia a subordinar las diferencias individuales a la identificaciµn de grupo. Seeleman
(1940-41), empleando fotografÚas de blancos y negros, encontrµ una correlaciµn alta entre las puntuaciones en esta medida y las puntuaciones en un cuestionario
de informes sobre sÚ mismo diseþado para medir la actitud hacia los negros, donde los sujetos con actitud menos favorable fueron menos precisos para
identificar las fotografÚas de negros que se habÚan mostrado previamente. El problema reside en saber si hay, en general, una correlaciµn entre el predominio
de un objeto actitudinal y la favorabilidad de la disposiciµn hacia Õl, problema interesante para investigarlo empÚricamente.
Medidas en que las inferencias se obtienen de reacciones fisiolµgicas al objeto actitudinal o a representaciones de Õl.
En el extremo opuesto de las medidas que confÚan en el informe verbal del sujeto sobre sus creencias, sentimientos, etc., estÃn las que confÚan en respuestas
fisiolµgicas no sujetas a control consciente. Pueden ser medidas de la reacciµn del sujeto -por ejemplo, la respuesta galvÃnica de la piel (RGP), o contracciµn
vascular- a la presencia de un miembro del grupo de objetos o a las representaciones pictµricas de situaciones en que intervienen miembros del grupo
de objetos. Por ejemplo, Rankin y Campbell (1955) compararon las RGP obtenidas cuando el experimentador era negro con las obtenidas cuando el experimentador
era blanco; Westie y DeFleur (1959) registraron la RGP, la contracciµn vascular del dedo, la amplitud y duraciµn del latido del corazµn y la duraciµn del ciclo
cardÚaco mientras los sujetos veÚan fotografÚas de blancos y negros en situaciones sociales. Hess y Polt (1960) fotografiaron la contracciµn pupilar en
respuesta a estÚmulos displacenteros y la dilataciµn pupilar al responder a estÚmulos placenteros.
Bien puede suceder que esas medidas impliquen respuestas, como la salivaciµn, parpadeo, contracciµn vascular, que hayan sido condicionadas a un estÚmulo
verbal y, por un proceso de generalizaciµn semÃntica, aparezcan al responder a palabras, o bien que impliquen conceptos semejantes en significado al estÚmulo
original. Por ejemplo, Volkova (1953) informµ de una serie de experimentos, en Rusia, en los que ciertos sujetos fueron condicionados a salivar en respuesta a
la palabra BUENO; subsecuentemente, aseveraciones como "el joven pionero ayuda a su camarada" produjeron salivaciµn mÃxima, mientras que afirmaciones por el
estilo de "los fascistas destruyeron muchas ciudades" produjeron salivaciµn mÚnima. En el caso
de respuestas fisiolµgicas incondicionadas a la presencia o a la representaciµn del objeto actitudinal, la base de inferencia procede directamente del concepto
de actitud. Y como todas las definiciones de actitud inI-luyen creencias, sentimientos y conducta manifiesta como indicadores de la actitud, todas las
definiciones, explÚcita o implÚcitamente, incluyen tambiÕn respuestas fisiolµgicas. Se supone que la magnitud de la reacciµn fisiolµgica estÃ
relacionada en forma directa y positiva con el grado de activaciµn o intensidad del sentimiento; de esta manera, cuanto mayor es la respuesta fisiolµgica, tanto
mÃs intensa o extrema se supone que es la actitud. Sin embargo, subsisten los problemas para inferir el carÃcter de la actitud que se refleja. La mayorÚa de
las medidas de reacciµn fisiolµgica solamente dan indicaciones directas del grado de activaciµn; pero no revelan si la emociµn correspondiente es placentera
o displacentera. En general, en los ensayos para evaluar las actitudes hacia grupos sociales por medio de la medida de reacciones fisiolµgicas, se ha
supuesto que la amplitud del afecto no va desde completamente favorable hasta completamente desfavorable sino que se extiende desde la aceptaciµn o
neutralidad, hasta lo completamente desfavorable; se ha inferido asÚ que cuanto mayor sea la respuesta fisiolµgica, tanto mÃs desfavorable es la actitud. Si la
tÕcnica de Hess de fotografÚa de la contracciµn-dilataciµn pudiera adaptarse al estudio de las actitudes, proporcionarÚa una base de inferencia mucho mÃs firme
en lo referente a la direcciµn de la actitud, ya que la reacciµn que se mide presenta una respuesta diferencial a estÚmulos placenteros y displacenteros.
En el caso de las respuestas fisiolµgicas condicionadas, la base de inferencia es algo diferente, pues proviene de la teorÚa del aprendizaje. Una respuesta que
se ha condicionado a determinado estÚmulo tiende a generalizarse a estÚmulos que sean semejantes. De esta manera, si una respuesta que se ha condicionado al
concepto de "bueno" aparece cuando se presenta el objeto actitudinal, la inferencia es de que el sujeto considera bueno al objeto, es decir, que su
actitud hacia Õl es favorable; si la respuesta no aparece cuando se presenta el objeto actitudinal, se infiere que el sujeto no lo considera bueno, es decir,
que su actitud hacia Õl no es favorable. El propµsito de las medidas fisiolµgicas puede o no ser evidente al sujeto. En
el estudio de Westie y DeFleur (1959), por ejemplo, se admite que los sujetos comprobaron que se estaban usando las medidas fisiolµgicas como indicadores de
sus reacciones a los cuadros interraciales. Por otra parte, en el experimento de Rankin y Campbell (1955), se hizo creer a los sujetos que estaban tomando parte
en un estudio de asociaciµn de palabras y que sus RGP a las palabras estÚmulo (y no a los experimentadores negros y blancos) era lo que se estaba investigando.
EstÕ o no claro para el sujeto el verdadero propµsito, el hecho de que las respuestas medidas no estÕn sujetas a control consciente parecerÚa eliminar la
posibilidad de modificaciµn de las respuestas para presentar cierta imagen falsa de sÚ mismo. Sin
embargo, las respuestas fisiolµgicas pueden ser muy sensibles a influencias diferentes de las que interesan al investigador, tanto a diferentes aspectos del
material de estÚmulo como a otras influencias ambientales. Es difÚcil controlar la situaciµn experimental al extremo de que no intervengan otros factores como
posibles determinantes de la respuesta. Interrogantes como Õstas seþalan constantemente la necesidad de tener extremo
cuidado al sacar inferencias acerca de la actitud de un individuo dado a partir de una medida de este tipo. Pero, de la misma manera seþalan las posibilidades
alentadoras de investigaciµn empÚrica y la oportunidad de incrementar ampliamente nuestra comprensiµn de las actitudes y su relaciµn con varios tipos
de respuesta, mediante el uso de instrumentos que producen diferentes tipos de prueba.
BIBLIOGRAFIA
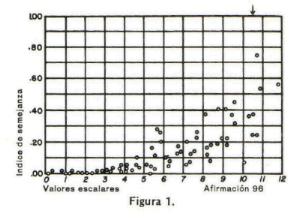
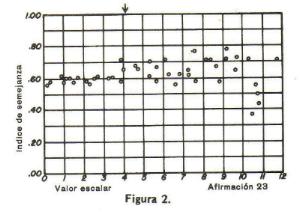
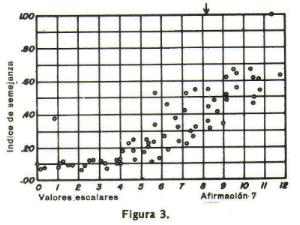
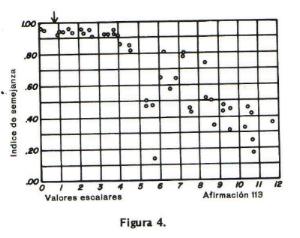
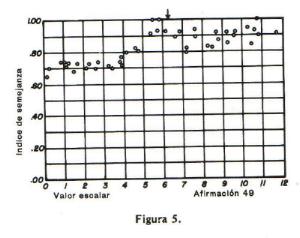
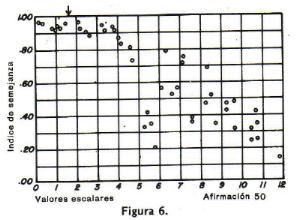
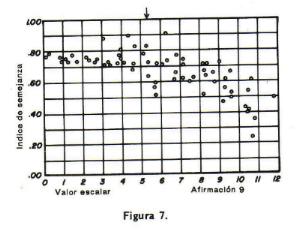
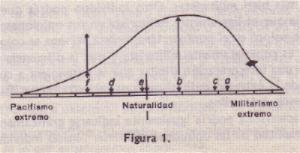
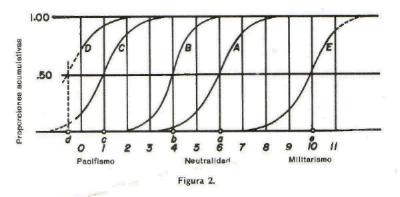
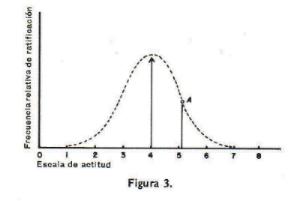
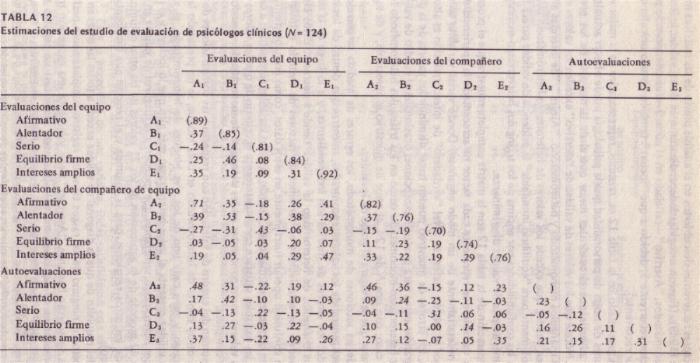
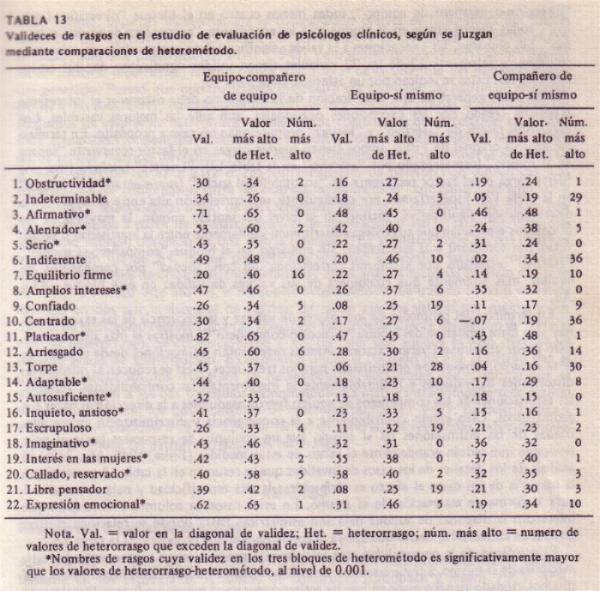

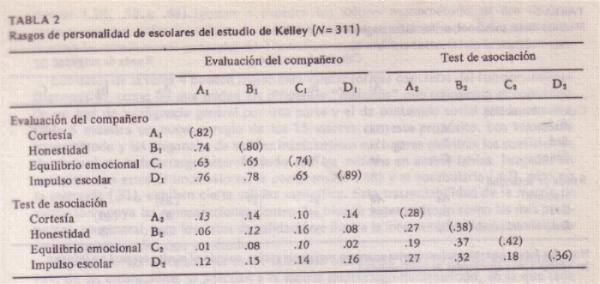
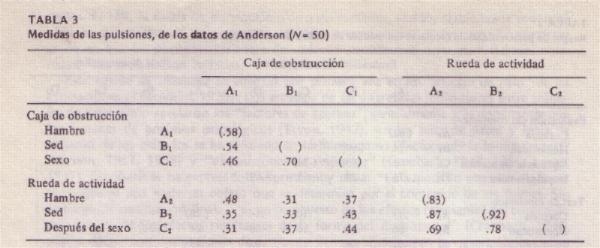




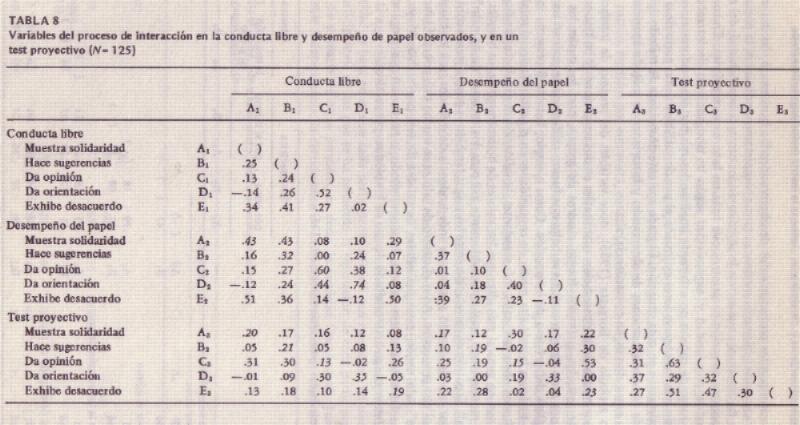


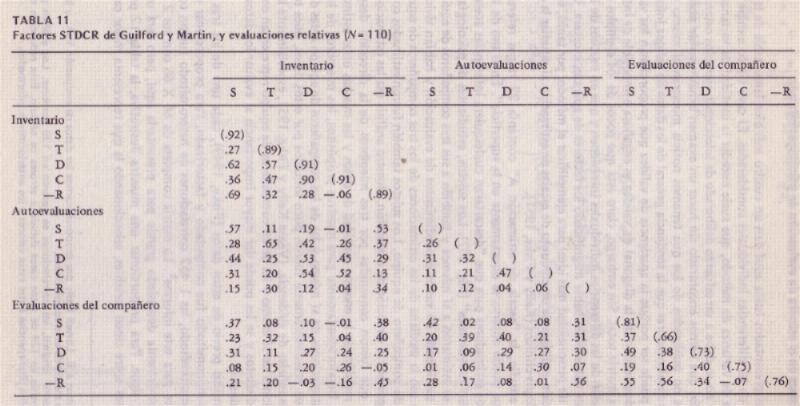
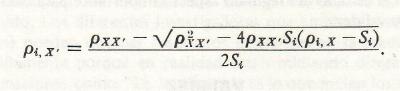
![]()
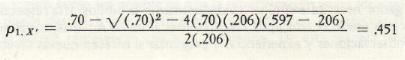
El anÃlisis factorial tambiÕn puede ser muy ºtil a) para determinar la
dimensionalidad de un dominio y b) para seleccionar los reactivos que se ajusten
mejor a los diferentes estratos del dominio. Esta tÕcnica proporciona la
correlaciµn de cada reactivo con cada faceta del dominio (tales facetas se
llaman "factores"). Los reactivos que se correlacionan bastante con un sµlo
factor reciben clara preferencia en la elaboraciµn de escalas.
(2b)ρTiei=0
(2c) ρTiej= 0
(2d )
ρeiej=0.
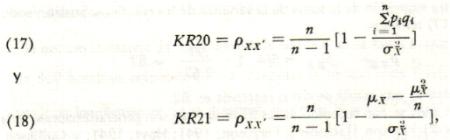
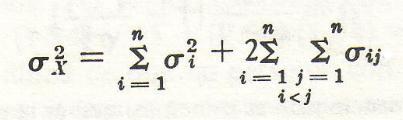
1
2
3
4
5
pi
p2i
1
0.09
.07
.05
.04
.08
.9
.81
2
.21
.11
.08
.14
.7
.49
3
.21
.07
.17
.7
.49
4
.24
.11
.6
.36
5
.16
.8
.64
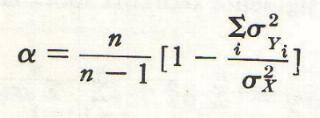
1
2
3
4
5
6
7
8
9
1
.534
.115
.168
.085
.118
.090
.167
.144
.129
2
.411
.114.
.062
.140
.080
.104
.065
.148
3
.814
.061
.118
.116
.177
.093
.272
4
.348
.087
.012
.103
.084
.054
5
.401
.072
.140
.123
.125
6
.465
.093
.052
.105
7
.645
.078
.127
8
.383
.093
9
.679
1954a "A technique and a scale for loudness measurement".
Journal of the Acoustical Society of America 26: 73-88.
1954b "Context effects and the validity of loudness scales".
Journal of Experimental Psychology 48: 218-224
1958 "Advantages of the discriminability criterion for a
loudness scale". Journal of the AcoustÚcal Society of America 30: 1005-1012.
1938 "The computation of psychological values from judgments in absolute
categories". Journal of Experimental Psychology 22: 34-42.
1954 Psychometric Methods. Segunda ediciµn. Nueva York, McGrawHill Book Company,
Inc. Gulliksen, H.
1950 Theory of Mental Tests. Nueva York, John Wiley & Sons, Inc.
1948 "Adaptation-level as a basis for a quantitative theory of frames of references". Psychological Review 55: 297-313.
1959 "Adaptation-Level Theory". En la obra Psychology: A Study Of a Science. Vol. I. (Koch, S., di rector) Nueva York; McGrawHill Book Company, Inc.
1951 Mathematics, measurement, and psychophysics". En la obra de S.S. Stevesns (Director), Hand book of Experimental Psychology. Nueva York; John Wiley & Sons, Inc.
1957 "On the psychological law". Psychological Review 64: 153-181.
1959 "Cross-modality validation of subjective scales for loudness, vibration,
and electric shock". Journal of Experimental Psychology 57: 201-209.
1958 Theory and Methods of Scaling. Nueva York; John Wiley & Sons, I nc.
1960 Quantitative judgment scales. (Gulliksen, H y Messick, S , Directores)
Nueva York; John Wiley & Sons, Inc.
El procedimiento de rangos normalizados*
Superintendente 0 .53 1.28 -1.28 -.53
Administrador .53 1.28 -.53 0 -1.28
Psicµlogo 0 .53 -.53 1.28 -1.28
Suma 1.06 - 3.62 .22 -.53 -4.37
Rango media normalizado .265 .905 .055 -.132 -1.092
Escala transformada 14.575 20.975 12.475 10.600 1.000
Pinturas
Diferencia media Valor escala
B
.52 0 -.31
-.77 -1.18 -1.41 -1.41
.592
2.194
C
1.08 .31 0
-.47 -.52 -1.08 -1.28
-1.55
.371
1.823
E
1.55 1.18 .52
.47 0
-.31 -.99 -1.28
.189
1.242
G
- 1.41 1.28
.92 .99
.36 0 .77
.381
.585
H
- -
1.55 1.41 1.28
1.28 .77 0
.585
0
TABLA 7
Rangos categoriales normalizados, usando los datos de la tabla 3*
1 00 -.25 -.13 -.52 -1.28 -
2 .84 .67 .25 .13 -1.28 -1.28
3 1.04 1.28 .67 .67 -.67 -.84
4 - 1.28 1.28 1.04 .38 .25
5
- - - - - -
Diferencia media .060 .287 .187 .100
Valor escala 0 .060 .347 .534 10.310 10.410
* En este caso hemos usado las proporciones acumulativas para obtener valores de
puntuaciµn estÃndar.
TABLA 9
Bill 0 -.71 -.66 -.88 -1.17
Joe .71 0 -,15 -.36 -.59
Andy .66 .15 0 -.07 -.22
Jack .88 .36 .07 0 -.18
Sam 1.17 .59 .22 .18 0
Diferencia media .606 .182 .122 .206
Escala logarÚtmica 1.116 .510 .328 .206 0
Escala de razµn 13.06 3.24 2.12 1.67 1
* Cada trabajador fue puesto a la par de cada uno de los demÃs; y los evaluadores dividieron el nºmero 100 de manera que reflejara la proporciµn de la
ejecuciµn efectiva. Las proporciones se convirtieron en logaritmos; el valor de cada celdilla es la media de los logaritmos, que equivale a la proporciµn
promedio del trabajador mencionado en la parte superior y el trabajador anotado a un lado de la tabla. DespuÕs, la diferencia media entre las columnas se
convierte, por adiciµn sucesiva, en una escala (como en una escala de intervalo); la escala final es el antilogaritmo de cada valor.
Garner (1954) desarrollµ y usµ una tÕcnica en la que aplicµ exactamente lo
anterior a la sonoridad. Primero elaboramos dos escalas de sonoridad, la primera basada en producciµn de razones (especÚficamente, fraccionamiento a la mitad de
sonoridad) y la segunda basada en equisecciµn. Pese a ello:, no hacemos la suposiciµn de que la razµn de un medio haya sido usada en realidad por los
sujetos, sino el supuesto. menos rotundo de que la proporciµn fue la misma en todos los juicios, pero que su valor se desconoce. Con esta suposiciµn, podemos
determinar aºn una funciµn de la sonoridad, pero no conocemos la razµn que se usµ. Esta funciµn està relacionada con la funciµn verdadera de la sonoridad
(latente) por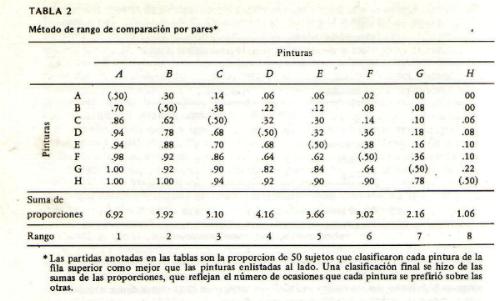
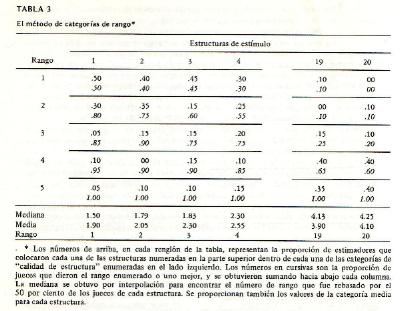

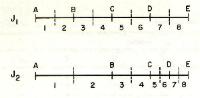
2 BACDE 6 DCEBA
3 BCADE 7 DECBA
4 CBDAE 8 EDCBA
2 BACDE o BCADEo BCDAE
3 BCDEA o BCDAE
4 CBDEA o CDBEA
5 CDEBA
6 DCEBA
7 DECBA
8 EDCBA