
Virgen de Loreto
Este espacio está reservado para los artículos ya publicados
Articulo Diciembre 2008 UNA TÉCNICA PARA ELABORAR ESCALAS DE ACTITUDES (II)
TÉCNICAS DE INFORMES SOBRE SI MISMO
El diferencial semántico no se concibió originalmente para
medir actitudes. El propósito inicial de Osgoad y colaboradores se encaminó hacia la exploración de las dimensiones del significado. Este esfuerzo fue
alentado por el rápido perfeccionamiento de las computadoras que pronto se convirtieron en invaluable ayuda para los tediosos cálculos del análisis
factorial. Que ha dado lugar al nuevo enfoque, en la semántica experimental, en la medición de actitudes.
El diferenciaˇ semántico no mide las reacciones de los individuos a objetos semánticos. Esto se consigue por estimaciones del objeto
sobre varias escalas sencillas de estimación, definidas por adjetivos bipolares; por ejemplo Bueno-Malo, Bonito-Feo, Caliente-Frio. Las estimaciones de cada
objeto se correlacionan y analizan factorialmente para determinar las dimensiones del significado.
Numerosas repeticiones dé éste procedimiento han
contribuido a demostrar la estabilidad de las tres dimensiones siguientes: la evaluativa; la de potencia y la de actividad. Teniendo en cuenta que la
actitud comprende claramente una respuesta evaluativa con respecto a un objeto de actitud, la aplicación del diferencial semántico a la medición de actitudes se ha iniciado con gran entusiasmo. Osgood, Tanenbaum y Suci,
en su libro "La medición del significado", definen su posición con respecto a la adaptación del diferencial semántico a la medición de actitudes.
Desde sus comienzos, el diferencial semántico ha cobrado extraordinaria popularidad entre
los investigadores de la rama. Por ello no deja de causar cierta sorpresa el hecho de que nadie, hasta ahora, haya resumido y examinado
críticamente su uso como método de medición de actitudes. A petición del director, David R. Heise escribió la revisión crítica. Esta es la única revisión completa de que se dispone hasta la fecha
y, por lo mismo será especialmente útil para quienes se interesen por la aplicación del tan citado diferencial semántico.
żCómo se sabe si los reactivos seleccionados para una medición de actitudes
basada en informes acerca de sí mismo reflejan la actitud que se supone están explorando? O, más sencillamente, żcómo puede establecerse si todos esos
reactivos captan la misma dimensión de actitud, cualquiera que sea? La validez de contenido, o lógica, de los reactivos de una escala de reactivos múltiples se
hace generalmente sobre una base a priori y a primera vista. Mas adelante
veremos dos métodos para establecer definiciones operacionales válidas de escalas de reactivos múltiples. Kerlinger y Kaya demuestran la utilidad del
análisis factorial para probar la monodimensionalidad de los reactivos que se tenga planeado incluir en una escala. Lingoes da a conocer un procedimiento de
computación para seleccionar grupos de reactivos monodimensionales a partir de una serie de reactivos dicotómicos que pueden tratarse posteriormente como una
escala de Guttman. Tradicionalmente, la medición de actitudes ha significado ubicar individuos a lo
largo de un continuo único de actitud, generalmente sobre una dimensión evaluativa. De ahí los grandes esfuerzos que se han dedicado al desarrollo de
escalas monodimensionales. Ha sido costumbre pensar que las personas son más o menos favorables, pro o anti, positivas o negativas, hacia determinado objeto de
actitud. Recientemente la atención se ha dirigido al estudio de
cómo ubicar los objetos en un espacio multidimensional. Esta via es prometedora, si bien sus progresos han sido lentos tal vez por la preparación
técnica que se requiere para ingresar al campo de la elaboración de escalas multidimensionales.
John Ross ha preparado una introducción, tan admirable como
técnicamente exacta, a la elaboración de escalas multidimensionales. Naturalmente que tal clase de escalas no tiene por qué limitarse a los
datos de informes sobre sí mismo. Como eńala Ross, puede esclarecer los aspectos teóricos de la actitud a la vez que mejorar la medición de actitudes.
Otra de las contribuciones recientes, digna de tenerse en cuenta dentro de la
medición de actitudes, es el "Enfoque de juicio social - implicación", de Sherif y Sherif, que se basa en los hallazgos del estudio experimental
del juicio -psicofísico y social- y en los de compromiso del si-mismo o del yo. Este enfoque permite tanto una estructura teórica de las actitudes, basada
sólidamente en investigaciones experimentales, como una técnica interesante de medición. Y como tal merece atenta consideración por parte de los investigadores
de actitudes. MEDICIÓN DE ACTITUDES
Uno de los resultados secundarios pero importantes de la investigación en semántica experimental, es un nuevo enfoque y fundamento de la medición
de actitudes. Ha sido posible identificar la "actitud" como una de las dimensiones importantes del significado general y con ello extender los
procedimientos de medición del diferencial semántico a uno de los campos primarios de la psicología social.
Al trabajar en este campo con el mencionado diferencial se han encontrado evidencias de un principio general que gobierna
algunos aspectos del proceso cognoscitivo o sea un principio de congruencia. Aunque la operación de este principio no se limita necesariamente a la dimensión actitudinal del espacio del significado,
se encuentra primeramente relacionado con la investigación sobre medición de actitudes y, por consiguiente, se usa dentro de este contexto.
Una definición de actitud
A pesar de la gran cantidad de definiciones de "actitud" en la ciencia social
contemporánea, es evidente cierto consenso y acuerdo, particularmente en lo que se refiere a las propiedades principales de aquéllas. La mayoría de las
autoridades en la materia están de acuerdo en que las actitudes se aprenden y permanecen implícitas; son estados inferidos del organismo que, al parecer, se
adquieren de manera muy semejante a como lo hacen otras actividades internas aprendidas. Son, al mismo tiempo, predisposiciones a responder; pero se
distinguen de otros estados similares en que predisponen a una respuesta evaluativa.
Por tanto, las actitudes se describen como "tendencias de acercamiento o evitación", o como "favorables o desfavorables", y así
sucesivamente. Esta noción se relaciona con otra opinión compartida: que las actitudes pueden adscribirse a un continuo básico bipolar, con un punto de
referencia neutral o cero, lo que implica que tienen dirección e intensidad y a la vez proporcionan una base para obtener índices cuantitativos de ellas. Para usar una nomenclatura diferente, las actitudes son procesos implícitos
que tienen propiedades recíprocamente antagónicas y que varían de intensidad.
Esta caracterización de la actitud como un proceso aprendido implícito, que es potencialmente bipolar, varía en su intensidad y media la conducta evaluativa,
sugiere que la actitud es parte para algunos especialistas, la parte principal de la actividad interna de mediación que opera entre la mayoría de las
estructuras de estímulo y de respuesta. Esta identificación de la actitud con la actividad mediatoria, ha sido hecha más explícita por Doob (1947), quien al
situarla dentro de la estructura de la teoría hulliana de la conducta, la identificó con el "acto puro de estímulo" en tanto que mecanismo mediador.
Sin embargo, aunque deficiente, es esta una identificación y localización de la actitud en sí, dentro de este sistema general de actividad de mediación. Nuestro
trabajo en la medición semántica parece sugerir tal identificación: si la actitud consiste en una porción de la actividad interna de mediación es,
entonces, por inferencia de nuestro modelo teórico, parte de la estructura semántica de un individuo y puede indicarse en correspondencia. Luego, el
análisis factorial del significado puede suministrar la base para extraer este componente actitudinal del significado.
En todos los análisis factoriales realizados hasta la fecha; ha aparecido invariablemente un factor de naturaleza evaluativa fácilmente
identificable; por lo común, ha sido el factor dominante, que explica la mayor proporción de la varianza total. A pesar de los diferentes conceptos y criterios
para seleccionar las escalas se obtuvieron consecuentemente valores altos y restrictivos en relación a este factor y con respecto a escalas como bueno-malo,
justo-injusto y valioso-inútil, mientras que escalas que eran intuitivamente de naturaleza no evaluativa, como rápido-lento, estable-mudable y pesado-ligero,
por lo común tuvieron valores pequeńos o despreciables con respecto a este factor. Parece razonable identificar la actitud, como se concibe generalmente en
el lenguaje común y corriente y en el científico, con la dimensión evaluativa del espacio semántico total, según se la aísla en la factorialización de juicios
significativos. Fundados en las operaciones de medida con el diferencial semántico, se ha
definido el significado de un concepto como su ubicación en un punto del espacio semántico multidimensional. Seguidamente, se define la actitud hacia un concepto
como la proyección de aquel punto sobre la dimensión evaluativa de dicho espacio. Obviamente, cada punto del espacio semántico tiene un componente
evaluativo (aunque el componente puede tener magnitud cero, cuando los juicios evaluativos son neutrales) y, por consiguiente, cada concepto debe tener un
componente actitudinal como parte de su significado total. Esto no implica que
la dimensión evaluativa o actitudinal sea inevitablemente estable en orientación con respecto a otras dimensiones del espacio; según sea el concepto o
conjunto de conceptos que se juzguen, pueden hacerse rotar escalas "puramente" evaluativos, como bueno-malo, de manera que queden alineadas con el factor de
potencia, el factor de "adiencia sensorial",, factor que dispone al organismo a la acción continua de un estímulo y así sucesivamente. En otras palabras, el tipo
de evaluación puede cambiar con el marco de referencia determinado por los conceptos (por ejemplo, político, estético, etc.).
Procedimiento de medición con el diferencial semántico
Conforme a la definición y fundamento dados anteriormente para medir la actitud, se usarían grupos de escalas con valores altos del factor evaluativo a través de
conceptos con valores despreciables de otros factores, según lo determinaran nuestros diferentes estudios de análisis factorial. Así, se usarían escalas como
bueno-malo, optimista-pesimista y positivo-negativo y no escalas como tierno-cruel, fuerte-débil o bello-feo, porque éstas resultarían generalmente
menos evaluativas a medida que se hace variar el concepto que se juzga. Sin
embargo, dado que el trabajo de factorialización de concepto a concepto en que se basan los principios presentes no se realizó en el momento en que se
emprendieron la mayoría de las medidas de actitud no siempre se cumplieron este criterio ideal. Para propósitos de consistencia de
calificación, se asignan uniformemente a los polos desfavorables de nuestras escalas evaluativas (por ejemplo, molo, injusto, insignificante, etc.) la
puntuación "1 " y a los polos favorables (bueno, justo, valioso) la puntuación "7", esto independientemente de la presentación de las escalas a los sujetos en
el diferencial gráfico, donde deben distribuirse aleatoriamente respecto a la dirección.
A continuación se suman simplemente todas las estimaciones evaluativas para obtener la "puntuación" de actitud. Un método más afinado sería valorar cada
escala con base en su carga de factor evaluativo con respecto a los conceptos que se juzgan; pero esto sería sumamente laborioso y, si las escalas son
"puramente" evaluativas, como se definieron arriba, es seguro que se mejoraría muy poco la precisión del instrumento. También debe seńalarse que en la práctica
incluimos por lo común un número considerable de escalas que representan otros factores; se hace esto tanto para oscurecer el propósito de la medición como
para proporcionar información adicional sobre el significado del concepto como un todo, además de la actitud hacia él.
Las propiedades principales de la actitud que se espera indique cualquier técnica de medición se estudian cómodamente por este procedimiento. La dirección
de la actitud favorable o desfavorable, queda indicada sencillamente en términos bipolares; si la puntuación cae más cerca de los polos favorables, entonces se
considera favorable la actitud, y viceversa. Una puntuación que cae en el origen, definido por el "4" de las escalas, se considera un índice de
neutralidad de la actitud. La intensidad de la actitud se indica por la distancia al origen de la puntuación sobre la dimensión evaluativa; es decir,
por la polarización de la puntuación de actitud. Aunque en una escala existen
solamente tres niveles de intensidad, "ligeramente", "bastante", y "extremadamente", en cualquier dirección, la suma en varias escalas evaluativas
produce grados más afinados de intensidad. Por ejemplo, si se usan seis escalas tenemos una amplitud de puntuaciones posibles desde seis (la más desfavorable),
pasando por 24 (exactamente neutral) hasta 42 (la más favorable), aparte de 18 grados de intensidad de puntuación de actitud en cada dirección. Con base en un
trabajo anterior Katz, y Cantril, se supuso que una puntuación neutral es de intensidad mínima en cuanto a actitud. La monodimensionalidad de
la escala de actitud resulta automáticamente de los procedimientos analítico factoriales a partir de los cuales se seleccionan las escalas.
Si las escalas usadas se seleccionan teniendo en cuenta que todas tienen valores puros y altos
del mismo factor -idealmente mantienen esta consistencia a través de varios análisis factoriales- debe lograrse monodimensionalidad. En otras palabras, el
análisis factorial es, en sí mismo, un método para probar la monodimensionalidad de los reactivos o escalas que forman un test.
Evaluación del diferencial como medida de actitud
Confiabilidad. Tannenbaum (1953) obtuvo datos de confiabilidad test-retest.
Empleando seis conceptos (Lideres sindicales, "The Chicago Tribune", Senador Robert Taft, Apuestas legalizadas, Arte abstracto y Programas universitarios acelerados)
fueron juzgados en relación a seis escalas evaluativas (bueno-malo, justo-injusto, valioso-insignificante, sabroso-desagradable, limpio sucio y
placentero-molesto) por 135 sujetos en dos ocasiones separadas entre sí por cinco semanas.
Se computaron puntuaciones de actitud sumando las seis escalas, después de realinearlas de acuerdo con una dirección evaluativa constante. Los
coeficientes de test-retest variaron desde .87 a .93, con una r media (computada por medio de la transformación z) de .91. En otro estudio, se obtuvieron datos
adicionales de confiabilidad, que confirman estos; aparecen en la tabla 1. Validez. La dimensión evaluativa del diferencial semántico muestra una validez
bastante razonable como medida de actitud. Por ejemplo, Suci (1952) pudo diferenciar entre etnocéntricos altos y bajos, determinados independientemente a
partir de la escala E de los estudios de personalidad autoritaria, con base en sus estimaciones de varios grupos étnicos en las escalas evaluativas del
diferencial. Similarmente, se encontró que las estimaciones de las escalas
evaluativas discriminan en las formas esperadas entre matices de preferencia política, en un estudio de Suci de la conducta del votante y en un estudio de
simbolismo pictórico político de Tannenbaum y Kerrick. Sin embargo, a diferencia
de la medida del significado en general, en el caso de la actitud tenemos otros instrumentos de medida desarrollados independientemente y con respecto a los
cuales se puede evaluar esta técnica. Veamos dos de estas comparaciones;
la primera, con las escalas de Thurstone; y la segunda, con una escala del tipo de Guttman.
Comparación con los escalas de Thurstone. Se evaluaron tres conceptos (Los
Negros, La Iglesia y La pena capital) con respecto a una serie de escalas, que incluían cinco puramente evaluativas (justo-injusto, valioso-insignificante, placenter-omolesto, limpio- sucio y bueno-malo). Además, los sujetos indicaron sus
actitudes en escalas de Thurstone diseńadas especialmente para medir estos objetos de actitud ; la escala estándar para la iglesia, la forma B de la escala
de los negros y la forma A de la escala de la pena capital de Thurstone. Los sujetos fueron divididos en dos grupos antes de someterlos a las
pruebas: a uno de los grupos (N=23) se le dio primero la forma del diferencial semántico; y una hora después los tests de Thurstone. El otro grupo (N=27)
recibió las mismas pruebas pero en orden contrario. Dos semanas después de esta sesión inicial, a los sujetos se les aplicaron nuevamente ambos tests, pero en
esta ocasión se invirtieron los órdenes respectivos. La segunda sesión se llevó a cabo para obtener información de confiabilidad sobre ambos tipos de
instrumentos de medición de las actitudes. Las columnas (1) y (2) de la tabla 1
muestran las correlaciones momento-producto entre las puntuaciones escalares del diferencial semántico (d) y de Thurstone (t) con respecto a tres objetos de
juicio, en la sesión inicial de examen (rd1t1,) y en la segunda sesión (rd2t2);
en las columnas (3) y (4) se ofrecen los coeficientes de confiabilidad de test-retest con respecto a las escalas de Thurstone (rt1t2) y las puntuaciones evaluativas
en el diferencial (rd1d2), nuevamente para cada uno de los tres conceptos juzgados.
Puede verse que las confiabilidades de los dos instrumentos
son altas y equivalentes. La correlación entre las puntuaciones del diferencial semántico y las puntuaciones correspondientes de Thurstone es significativamente
más grande de la que podría atribuirse al azar (p < .01) en cada caso; y en ninguno de estos la correlación entre las técnicas fue significativamente menor
que el coeficiente de confiabilidad del test de Thurstone. Las diferencias en
las correlaciones entre ambas técnicas, de la primera a la segunda sesión de examen, están dentro de los límites del azar. Claro está que cualquiera que sea lo que
midan las escalas de Thurstone, el factor evaluativo del diferencial semántico mide más o menos lo mismo. Ciertamente, cuando los seis coeficientes de validez se
corrigen por atenuación, se elevan a .90 o más. Comparación con una escala de Guttman.
En una revisión para examinar la validez del factor evaluativo del diferencial como medida de actitud en contraste con una escala
del tipo de Guttman. Se construyó una escala de 14 reactivos, del tipo Guttman (coeficiente de reproductibilidad de .92), con gran inversión de tiempo y
trabajo, para evaluar las actitudes de los agricultores hacia la práctica agrícola de la rotación de cultivos. Aproximadamente al mismo tiempo se usó el
diferencial semántico en conexión con una serie de programas de televisión que trataban de prácticas agrícolas y uno de los conceptos incluidos fue la rotación
de cultivos. Aunque estos estudios se realizaron independientemente, se encontró
que 28 sujetos habían sido sometidos a ambos instrumentos de examen. La escala de Guttman se había aplicado primero en todos los casos y el lapso entre los dos
exámenes varió considerablemente, desde solo tres días hasta casi cuatro semanas. Con las puntuaciones de actitud, en el diferencial, obtenidas sumando
las tres escalas evaluativas que se emplearon (bueno-malo, justo-injusto y valioso-insignificante) la correlación de orden de rango entre los dos
instrumentos fue muy significativa (rho = .78; p < .01). Por lo que se puede decir que la escala de Guttman y las escalas evaluativas del diferencial miden
en alto grado la misma cosa. Los resultados de estos dos estudios corroboran la noción de que el factor
evaluativo del diferencial semántico es un índice de actitud. Además, es un método de evaluación de actitudes relativamente fácil de aplicar y calificar.
Aunque no explora mucho el contenido de una actitud en el sentido del significado denotativo (por ejemplo, las reacciones específicas que presentarían
personas con diferentes actitudes, las aseveraciones específicas que podrían aceptar), parece proporcionar un índice de la ubicación del objeto de actitud a
lo largo de un continuo evaluativo general. Si el diferencial semántico en conjunto puede proporcionar un cuadro de mayor riqueza del significado del
objeto de actitud que la dimensión evaluativa solamente en conjunto puede proporcionar un cuadro de mayor riqueza del significado del objeto de actitud
que la dimensión evaluativa solamente, en un punto que se verá mas tarde.
Articulo Noviembre 2008 UNA TÉCNICA PARA ELABORAR ESCALAS DE ACTITUDES (II)
Análisis de reactivos Los 83 reactivos se adaptaron a respuestas del tipo de Likert.
Cada uno de ellos fue seguido por una escala obligatoria de 6 puntos (completamente de acuerdo, de acuerdo, ligeramente de acuerdo, ligeramente en
desacuerdo, en desacuerdo, completamente en desacuerdo). Se pidió a los sujetos que marcaran en cada reactivo la expresión que describiera mejor su propia
actitud hacia aquél. En total, 355 sujetos llenaron el cuestionario: 245 de clases de sociología, psicología e idiomas, de la Universidad de Washington; 60 de una
preparatoria local y 50 de una escuela de policías. De los 355 cuestionarios quedaron 346, porque 9 de ellos estaban incompletos o tenían más de una
respuesta en algún reactivo. La calificación se hizo de acuerdo con el método general de Likert, asignándose
valores de 0 a 5 a las 6 categorías de respuesta; el valor 5 fue para la respuesta completamente de acuerdo, en el caso de reactivos que expresaban una
opinión favorable sobre la ciencia; y también para la respuesta completamente en desacuerdo en los reactivos que expresaban una opinión desfavorable sobre la
ciencia. En cuanto a los 6 reactivos dentro del intervalo escalar de 4.0 a 4.9, la asignación de valores se hizo basándose en que el valor escalar del reactivo fuera
mayor o menor que 4.5. A cada sujeto se le sumaron los valores de las respuestas
en los 83 reactivos individuales y se dibujó una distribución de frecuencia de las puntuaciones resultantes. La amplitud obtenida de las puntuaciones fue
solamente el 64% de la amplitud posible (la obtenida de 140-405, la posible de 0-415) con una gran giba en el extremo superior (favorable) de la distribución.
Se escogieron dos grupos de criterio, aproximadamente el 27% superior e inferior, sobre la base de las puntuaciones totales. La amplitud de las
puntuaciones con respecto a los 94 cuestionarios inferiores fue de 140 a 300 y los 94 superiores tuvieron puntuaciones desde 343 hasta 405. Las 83
aseveraciones se sometieron entonces a análisis de reactivos. Para cada una, se tabularon las frecuencias en cada una de las categorías de respuesta tanto para
el grupo superior como para el inferior. Las 6 categorías se redujeron a 2, combinando las categorías 0, 1, 2, 3 y 4. Esta agrupación fue necesaria porque
los sujetos dieron respuestas predominantemente favorables a los reactivos. Si el universo de contenido hubiera sido la actitud hacia los sindicatos, se
hubiera esperado una distribución más simétrica de las respuestas y, consecuentemente, una agrupación diferente de las categorías. A partir de las tablas de 2 x 2
resultantes, se calcularon los coeficientes fi (11) (Φ), que variaron desde 16 a 0.78. Los nomogramas de Guilford y las tablas preparadas por Jurgensen
simplifican estos cálculos. Los 83 reactivos se dibujaron en una distribución bivariada con los valores (Φ)
sobre el eje Y y los valores escalares sobre el eje X. Una gráfica de los valores de fi, en contraste con los valores de Q, no
indicó relación discernible; y la variabilidad dentro de las columnas fue aproximadamente igual a la variabilidad total. Esto indicaría que en el
procedimiento de discriminación escalar seguido, el análisis de fi vigoriza el proceso de selección de reactivos cuando se usan reactivos con valores de Q
semejantes. En este momento se han eliminado ya el 50% de los reactivos con los valores de Q mayores.
Se seleccionaron de cada mitad del intervalo escalar los 4 reactivos con los mayores coeficientes fi;
debido a los huecos mencionados en el continuo de la escala solamente se abarcaron los intervalos entre .5 y 2.5 y entre 6.5 y 8.0. No se seleccionaron
reactivos entre los controles "neutrales" en el intervalo escalar de 4.0 a 4.9. Los 28 reactivos así seleccionados se asignaron a las formas A y B de los
cuestionarios, alternándose los valores escalares entre ambas formas.
Las escalas finales fueron de 14 reactivos cada una, con reactivos aproximadamente iguales en cuanto a valores escalares de Thurstone, valores Q y
valores fi. En las formas A y B, respectivamente, los valores escalares medios de los 14 reactivos fueron 3.85 y 3.91, los valores Q medios fueron .90 y .92.
Los coeficientes fi de los reactivos, en la forma A, variaron entre .58 y .78 con un valor mediano de .65; en la forma B variaron desde .58 a .76 con un
valor mediano de .66. Solamente 1 de los 10 reactivos de control restantes tuvo un valor fi por encima de .58. Fue precisamente uno de los 6 reactivos
"neutrales" el que tuvo un valor fi de .61. Los demás reactivos de control serían rechazados según el criterio fi.
CONFIABILIDAD Y REPRODUCTIBILIDAD DE LA ESCALA
El coeficiente de confiabilidad de las dos formas de la escala, de 14 reactivos, cada una, calculado según las respuestas de 248 sujetos
nuevos fue de .81, no corregido. Para ambas formas del test se restringió completamente la amplitud de las puntuaciones, de 30 a 70 en cada caso, con
amplitudes posibles de 0 a 70. Dentro de esta amplitud restringida se presentó una giba en el extremo superior o favorable. La puntuación media con respecto a
la forma A fue de 58.22 y la desviación estándar de 7.33. En cuanto a la forma B, la media fue de 57.20 y la desviación estándar de 7..79.
Se realizó el análisis escalar basado en la ejecución de una muestra de 87 sujetos extraídos de un grupo mayor de 248, en ambas formas del
test por medio de la técnica de Cornell (11). Se obtuvo un coeficiente de reproductibilidad de 87.5% con respecto a la forma A y un coeficiente de 87.2%
para la forma B. Las categorías de respuesta en cada caso se dicotomizaron.. Se establecieron puntos de corte y se observo la regla de Guttman de que "ninguna
categoría debe tener mayor número de errores que de aciertos". La amplitud de la categoría de respuesta modal fue de .51 a .82 en la forma A. El valor medio de
las categorías modales, .57, que es el valor mínimo del coeficiente de reproductibilidad para este conjunto de reactivos en la muestra usada, puede
compararse con el coeficiente observado de reproductibilidad del 87.5%. Este es el límite inferior porque la reproductibilidad de cualquier reactivo no puede
ser menor que la frecuencia de la categoría modal. El método para computar el valor mínimo del coeficiente supone independencia entre los reactivos. En cuanto
a la forma B, la amplitud de las categorías modales fue de .52 a .67. El valor medio, que es nuevamente el límite inferior del coeficiente de
reproductibilidad, fue de .57, mientras que el valor observado del mismo coeficiente fue del 87.2%.
Los dos valores observados del coeficiente de reproductibilidad son suficientemente altos para ofrecer pruebas de que una sola
variable dominante está comprendida en los grupos de reactivos o que, dicho de otra manera, existe monodimensionalidad. Se dice que tales grupos de reactivos
son adaptables a una escala o que constituyen una escala. Los coeficientes de reproducibilidad también significan que es posible reproducir las respuestas a
los reactivos a partir de las puntuaciones de orden jerárquico con el grado de exactitud indicado por el valor de aquellos mismos.
El error de reproductibilidad presente es sencillamente igual a 1.00 menos el coeficiente observado de reproductibitidad. Si puede suponerse
que tal error es al azar, entonces estos grupos de reactivos poseen una propiedad importante: la simple correlación entre las puntuaciones de orden
jerárquico y un criterio externo será igual a la correlación múltiple entre los reactivos y el criterio externo. Y esto, a su vez, significa que la eficiencia
de la predicción se hace máxima por la simple correlación. Sería igualmente verídico que en el caso de grupos de
reactivos que satisfacen los criterios exigidos para las escalas, la interpretación de las puntuaciones de orden jerárquico no es ambigua, y que es
posible hacer afirmaciones significativas tocante a que un sujeto es superior (más favorable) que otro en la variable en cuestión. En el caso de escalas
perfectas, donde el coeficiente de reproductibilidad es la unidad, se infiere igualmente que un individuo con una puntuación de orden jerárquico baja no daría
una respuesta más favorable a cierto reactivo que cualquier persona con una puntuación de orden jerárquico más alta.
Esto no sería cierto en un test que incluyese más de una variable. Supongamos, por ejemplo, que un test comprende dos variables. Entonces
un sujeto puede obtener determinada puntuación superior en una variable e inferior en la otra. Otro sujeto podría obtener la misma puntuación y ser
superior en la segunda variable e inferior en la primera. A partir de las puntuaciones de orden jerárquico únicamente, sería imposible indicar las
posiciones relativas de los sujetos en las dos variables; y, por tanto, es ambigua la interpretación de la puntuación compuesta. Podrían hacerse
afirmaciones de "mayor y menor que"; pero no sabriamos a qué se referiría el "mayor y menor que", porque al incrementar o disminuir el número de reactivos
relacionados con una de las variables, podrían alterarse las puntuaciones de orden jerárquico de los sujetos, no significa esto que las escalas
multidimensionales carezcan de valor. Esto no sería verdadero en un test donde todos los reactivos pertenecieran a un sólo continuo, es decir, en un test
monodimensional. En tal tipo de test, el incremento del número de reactivos no cambiaría las puntuaciones jerárquicas de los sujetos.
RESUMEN
Al método de discriminación escalar descrito ha recibido el nombre, por usar el procedimiento de elaboración de escalas de Thurstone; y
reserva el procedimiento de Likert para evaluar el poder discriminativo de los reactivos individuales. Además, los reactivos seleccionados por el método de
discriminación escalar, producen coeficientes de reproductibilidad satisfactorios y satisfacen los requisitos del análisis escalar de Guttman. El
método de discriminación escalar es esencialmente una síntesis de los métodos de evaluación de reactivos de Thurstone, Likert y Guttman. También posee ciertas
ventajas que no están presentes en ninguno de estos métodos, considerados separadamente.
Por ejemplo el método de discriminación escalar elimina los reactivos menos discriminantes en una muestra grande, tarea en la que falla el
metodo de Thurstone solo. El problema no resuelto en el procedimiento de Thurstone es el de seleccionar dentro de cada intervalo escalar los reactivos
más discriminantes. Los reactivos dentro de cualquier intervalo escalar pueden presentar un alto grado de variabilidad con respecto a una medida de
discriminación. Por ejemplo, encontramos dentro de un sólo intervalo reactivos con valores fi que van desde .24 a .78. Que el criterio Q de Thurstone no
ayuda materialmente a la selección de los reactivos discriminantes, lo índica la gráfica de los valores de fi contra los valores de Q, después que se ha
rechazado el 50% de los reactivos con los valores Q mayores. En tal circunstancia, los reactivos con valores de Q, desde 1.00 hasta 1.09, tuvieron
valores fi que oscilaban entre .32 y .76. El método de Thurstone, por la inclusión de reactivos "neutrales", tiende también a disminuir la confiabilidad
y la reproductibilidad del grupo de reactivos seleccionado finalmente. Por tanto, cuando seleccionamos reactivos únicamente por la
técnica de Thurstone, no tenemos base para seleccionar reactivos con valores escalares y valores Q semejantes, pese a que estos reactivos no sean igualmente
valiosos para la medición de actitudes. Disponiendo de alguna medida del poder discriminante de los reactivos, la selección se vuelve objetiva así como
ventajosa por lo que se refiere a la escala misma. La ventaja del método de discriminación escalar con respecto
al procedimiento de Guttman se basa esencialmente en el hecho de qué hemos suministrado una base objetiva para la selección de un conjunto de reactivos que
después son examinados en cuanto a su adaptabilidad a la escala. Es posible que el método de discriminación escalar no siempre produzca un conjunto de reactivos
con un coeficiente de reproductibilidad satisfactorio. Pero ésta no es una objeción mayor a la técnica, sino tan sólo la manifestación del hecho de que un
conjunto de reactivos seleccionados intuitivamente no siempre será adaptable a una escala. Al parecer, el método de discriminación escalar ofrece mayor
garantía de factibilidad de una escala que cualquier técnica intuitiva, como la aplicada por Guttman.
Además, el conjunto de reactivos seleccionado por la técnica
de discriminación escalar suministra una amplitud mayor de contenido que los reactivos intuitivos de Guttman. Por el método de discriminación escalar,
obtenemos reactivos que no son primordialmente expresiones múltiples de la misma pregunta, como a menudo sucede cuando la selección de un conjunto de reactivos
que van a ser examinados en cuanto a su adaptabilidad a la escala se deja a la experiencia del investigador.
BIBLIOGRAFIA
Articulo Octubre 2008 UNA TÉCNICA PARA ELABORAR ESCALAS DE ACTITUDES (I)
En artículos anteriores, se ha pasado revista a varios de los métodos que se siguen para elaborar escalas de actitudes; el método de intervalos
aparentemente iguales, desarrollado por Thurstone; el método de estimaciones sumatorias, desarrollado por Likert y el método de análisis
escalar creado por Guttman. El método de intervalos aparentemente iguales y el de estimaciones sumatorias son similares en cuanto que suministran técnicas
para seleccionar, de un numero grande de reactivos, un conjunto que constituye el instrumento de medida. El análisis escalar difiere de estos dos métodos en
que se ocupa de la evaluación de un conjunto de reactivos, después de que estos, de uno u otro modo, ya han sido seleccionados.
En el método de intervalos aparentemente iguales, un grupo de peritos clasifica reactivos de opinión en 9 u 11 categorías que constituyen un continuo que varia
de desfavorable a favorable. El valor escalar de cada reactivo se determina por el punto del continuo, por encima y por debajo, en el cual el 50% de los peritos
colocan tal reactivo. La dispersión de las estimaciones de los peritos se mide por Q, la amplitud intercuartilar. Un valor de Q alto para un reactivo indica
que los peritos están en desacuerdo con la ubicación del reactivo en el continuo, lo que a su vez significa que el reactivo es ambiguo. Tanto los
valores de Q como los escalares se usan en la selección de reactivos para el test de actitud. Con tal propósito se seleccionan aproximadamente 20 reactivos
con valores escalares espaciados igualmente a lo largo del continuo y con valores de Q pequeńos. Se determinan las puntuaciones del test hallando la
mediana de los valores escalares de los reactivos con los que esta de acuerdo el sujeto. En el método de estimaciones sumatorias se seleccionan reactivos con un criterio
de consistencia interna. Los sujetos indican si están: completamente de acuerdo, de acuerdo, en duda, en desacuerdo o completamente en desacuerdo, con cada
reactivo. Se asignan valores numéricos a estas categorías de respuesta usando los enteros sucesivos de 0 a 4; el valor más alto se asigna consecuentemente a
la categoría que indica la actitud más favorable. Se selecciona un grupo superior y uno inferior, con base en las puntuaciones totales obtenidas de la
suma de los valores de los reactivos. Después se comparan las respuestas de estos dos grupos en los reactivos individuales; y los 20 reactivos más
discriminantes o poco más o menos se seleccionan para el test de actitud. Una puntuación de actitud en este test se determina sumando los valores asignados a
las respuestas del sujeto a los 20 reactivos. En el análisis escalar, se prueba un conjunto completo de reactivos para
determinar si, como grupo, constituyen una escala en el sentido de que a partir de la puntuación de orden jerárquico sea posible reproducir la respuesta de un
sujeto a los reactivos individuales. El grado en que esto es posible se expresa por el coeficiente de reproductibilidad. Aunque ordinariamente Guttman emplea
de 10 a 12 reactivos, para explicar con claridad ate coeficiente supongamos que tenemos tres reactivos, cada uno con sólo dos categorías de respuesta: de
acuerdo y en desacuerdo. Supondremos que la respuesta "de acuerdo", en cada caso, representa una actitud favorable y la respuesta "en desacuerdo" una
actitud desfavorable. Se asigna el valor 0 a la respuesta en desacuerdo y el valor 1 a la respuesta de acuerdo. Supongamos también que con respecto al primer
reactivo tenemos en nuestra muestra 10 sujetos con valor 1, y 90 con valor 0; con respecto al segundo reactivo tenemos 20 sujetos con valores de 1, y 80 con
valores de 0; y para el tercer reactivo tenemos 40 con valores de 1, y 60 con valores de 0. En el caso de reproductibilidad perfecta, los 10 sujetos con valor 1 en el
primer reactivo serán los 10 sujetos con las puntuaciones de orden jerárquico más altas. Estos 10 sujetos también estarán comprendidos en los 20 que tienen
valor 1 en el segundo reactivo; y estos 20 a su vez estarán comprendidos en los 40 que tienen valor 1 en el tercer reactivo. En la misma forma sería cierto que
solamente se presentarían 4 patrones de respuesta de reactivo, si el conjunto de estos fuera perfectamente reproductible. Tocante a la muestra disponible, los
patrones y puntuaciones asociadas a ello; serían: AAA-3; DAA-2; DDA-1; DDD-0. Establecido que todas las respuestas podrían predecirse perfectamente a partir
de las puntuaciones, en este caso, el coeficiente de reproductibilidad sería del 100%. Sin embargo, rara vez se obtiene una reproductibilidad perfecta y en la
práctica se considera satisfactorio un coeficiente del 85% o más, para que un conjunto de reactivos constituya una escala. Se han desarrollado varias técnicas
para computar el coeficiente de reproductibilidad, que han sido documentadas por Festinger, Clark y Kreidt y Guttman. Además del coeficiente de reproductibilidad (10, 12), existen
otros criterios que se aplican para determinar si un conjunto de reactivos constituye una escala. Sin embargo, poco se ha publicado tocante a los casos en
que se han aplicado empíricamente estos criterios a un conjunto concreto de datos. El coeficiente de reproductibilidad ha sido destacado en todas las
publicaciones de Guttman, quizá porque se considera una condición primaria e inevitable, pero insuficiente, de una escala.
El análisis escalar, en el sentido antes mencionado, se convierte entonces en una técnica secundaria dentro del problema de la selección
de reactivos; esto no niega la importancia de la teoría que fundamenta el análisis escalar. Lo importante es obtener un conjunto de reactivos que den
alguna seguridad al investigador de que formarán una escala cuando se aplique una técnica particular para probar su adaptabilidad a una escala. Hasta época
reciente, el problema de la selección de reactivos en el análisis escalar parece haberse dejado a la intuición y experiencia del investigador. Las únicas reglas
prácticas sugieren que uno debe expresar, sencillamente, la misma pregunta, de maneras ligeramente diferentes, o que uno debe buscar reactivos cuyo contenido
sea lo más homogéneo posible. Esta última recomendación implica que, si estuviéramos interesados en el problema de la actitud hacia los negros, deberíamos dividir
este universo de contenido en subuniversos que constituyeran tal vez áreas tales como la actitud hacia los negros en restaurantes; la actitud hacia los negros
como residente en la comunidad, como votantes y como patrones; la actitud hacia los negros en los transportes públicos y así sucesivamente. Pero aún aquí
encontramos que la actitud hacia los negros, digamos en los transportes públicos, puede dividirse en áreas de contenido aún más homogéneas al
especificar los transportes: tranvías, autobuses, trenes, aviones, etc. Cada una de estas áreas de contenido quizás pueda dividirse en otras aún más homogéneas y
vendríamos a terminar seguramente como !o indica Festinger, con múltiples expresiones de la misma pregunta; y así nuestras dos reglas no son sino una.
Cualquier técnica que nos permitiera seleccionar un conjunto de reactivos del conjunto más grande de posibles reactivos, con cierta seguridad
en que el conjunto seleccionado llenaría los requisitos del análisis escalar, sería de gran valor. En este artículo se describe una técnica que ha tenido
éxito en la tarea. Por razones que se conocerán más adelante, hemos llamado a esta técnica "método de discriminación escalar para elaborar escalas de
actitud". LA TÉCNICA DE DISCRIMINACIÓN ESCALAR El método de discriminación escalar se basa en
investigaciones previas que mostraron que el punto de corte (el punto de corte de un reactivo indica el lugar de las puntuaciones de orden jerárquico de los
sujetos donde la respuesta más común cambia de una categoría (de acuerdo) a la siguiente (en desacuerdo). Entre los puntos de corte de una escala perfecta,
todas las respuestas caen en la misma categoría.), de un reactivo está relacionado con el valor escalar thurstoniano del reactivo; y que su
reproductibilidad (la reproductibilidad de un reactivo se mide por el grado en que pueden reproducirse las respuestas al reactivo a partir de las puntuaciones
de orden jerárquico de los sujetos) se vincula con su poder discriminativo. Este, como ya se hizo notar, no es, contra lo que pudiese
parecer a primera vista, solamente una función del valor escalar del reactivo. Puede demostrarse expeditamente que reactivos con valores escalares
thurstonianos y valores de Q semejantes pueden diferir grandemente en su eficacia para diferenciar los que tienen actitudes favorables de los de
actitudes desfaborables. Por ejemplo, el reactivo extremo: "Todos los xxxx deben ser ejecutados" indudablemente presentaría un valor escalar en un extremo del
continuo y un valor Q claramente pequeńo. Pero este reactivo no establecerá diferencia entre los que tienen actitudes favorables o desfavorables hacia los
xxxx por la evidente razón de que ambos grupos probablemente reaccionarían a él del mismo modo. Se reunieron aseveraciones de opinión sobre ciencia, de muy
diversas fuentes. Se consultaron libros y ensayos. Se pidió a individuos que expresaran sus opiniones en breves afirmaciones escritas; y se lograron reunir
266 aseveraciones sobre el particular. En la edición de estos reactivos, se atendió especialmente a la eliminación de aquellos reactivos que: Gracias al cuidado con que se realizó la recolección y la edición de las aseveraciones, la mayoría de las 155 seleccionadas finalmente
expresaron una opinión claramente favorable o desfavorable hacia la ciencia. Otros 13 reactivos, que pudiésemos llamar de control, se
agregaron a los 155 originales. Estos 13 últimos se agregaron para determinar lo que les sucedía a lo largo de las diferentes etapas del método de discriminación
escalar. De los 13 reactivos, 7 se juzgaron "neutrales", en el sentido de Thurstone; 2 podían interpretarse como relativos a hechos precisos; uno se
consideró demasiado extremo para recibir muchas ratificaciones, otro se juzgó ambiguo porque las palabras "scientific holiday" (festividad científica) podrían
interpretarse como una moratoria o como una celebración; otro más se consideró ambiguo porque comprendía más de una dimensión; y un último se consideró
inadecuado. Había, en consecuencia, 168 reactivos que se emplearon para probar el método de discriminación escalar de elaboración de escalas. Debe recalcarse
que la inclusión de reactivos de "control" no se considera parte del procedimiento de discriminación escalar Determinación de los valores escalares y valores Q de los
reactivos Se prepararon sobres numerados del 1 al 110. En cada sobre se colocó un conjunto de tarjetas de 8 x 12 cm. marcadas con las letras A, B, C, D,
E, F, G, H, I y un paquete de tiras de papel de 5 X 10 cm aproximadamente. En cada tira de papel, se imprimió uno de los 168 reactivos junto con el número del
reactivo. En cada caso se barajó el paquete de tiras de modo que los reactivos quedaran absolutamente desordenados. Se entregaron los sobres a un grupo de
estudiantes de la clase de psicología elemental, junto con las instrucciones que describen el procedimiento de clasificación de Thurstone, y se les pidió que
clasificaran los reactivos de acuerdo con las instrucciones. Se examinaron las clasificaciones de cada sujeto y se
descartaron aquéllos cuyas clasificaciones presentaban inversiones obvias del continuo o que no atendieron las instrucciones. Sobre esta base se quedaron con
82 grupos de juicios. Se tabularon las frecuencias de juicio en cada una de las 9 categorías con respecto a cada reactivo; se transformaron en frecuencias
acumulativas y después en proporciones acumulativas, ( Esta tarea fue muy laboriosa. Casi 14000 tiras de papel tuvieron que clasificarse para después ser
tabuladas. Algunas técnicas de juicio similares a las empleadas por Ballin y Famworth o Seashore y Hevner reducirían mucho este trabajo, pero aún así
la tarea no es sencilla. Varios métodos que simplifican el proceso de juicio se están usando actualmente). Se dibujó la ojiva correspondiente a cada reactivo; las
proporciones acumulativas se colocaron en el eje de las ordenadas y los valores escalares en el eje de las abscisas. Estos valores se escribieron con dos cifras
decimales (el segundo decimal fue solamente una aproximación) las cuales se obtuvieron trazando una perpendicular a la línea base de los valores escalares
en el punto donde la curva de proporción acumulativa cruzó la marca del 50%. De manera similar se determinaron valores Q trazando perpendiculares en los niveles
del 25 y 75%; Q era la distancia entre estos dos puntos, o sea la amplitud intercuartilar; (Esta operación se simplificó estableciendo una gráfica maestra
con las proporciones acumulativas en el eje Y y los valores escalares en el eje X. Se enrolló la gráfica en una placa de vidrio granulado que se adaptó a una
caja de madera cerrada que contenía un bulbo de 100 vatios. Luego se colocó papel para dibujar sobre dicha gráfica y se representaron rápidamente las ojivas
de los reactivos individuales.) Posteriormente se dibujaron los 168 reactivos en una distribución bivariada de acuerdo con los valores escalares y de Q; los valores
escalares se representaron en la línea base. La distribución de estos adquirió la forma bimodal. Hubo muy pocos reactivos en la zona "neutral" (ninguno entre
5.0 y 5.9); las categorías modales iban de 1.0 a 1.9 y de 7.0 a 7.9. Los valores Q de los 7 reactivos que cayeron en el intervalo escalar "neutral" (de 4.0 a
4.9) fueron muy bajos; 6 de ellos cayeron por debajo del valor Q mediano de los 168 reactivos. Estos 7 reactivos fueron los de "control", descritos
anteriormente. Se dibujó una línea a través de la distribución aproximadamente en la mediana de los valores Q de todos los reactivos, en 1.29.
Todos los reactivos con valores Q por encima de este punto fueron rechazados. A partir de este momento trabajamos solamente con los 83 reactivos restantes, o
sea aproximadamente el 50% del conjunto inicial de reactivos con el menor grado de ambigüedad según es medida por Q. Uno de los reactivos de control "neutral"
se eliminó por medio de este estándar; pero 6 fueron aceptables. Estos 6 reactivos tuvieron valores escalares entre 4.0 y 4.9. Ningún reactivo se
encontró en el intervalo escalar de 5.0 a 5.9 y el criterio de Q eliminó a todos los que estuvieran dentro del intervalo de 3.0 a 3.9. Uno de los 2 reactivos
referente a hechos precisos fue eliminado por el criterio de Q y también se eliminó el reactivo ambiguo con las palabras "scientific holiday". Los 10
reactivos restantes de control se consideraron aceptables por medio del criterio Q.
Articulo
Septiembre 2008 COMO ELABORAR ESCALAS TECNICAS DE GUTTMAN
LA FUNCIÓN DE INTENSIDAD. Guttman (1954) concibió dos métodos para ordenar a los individuos sobre un
continuo de contenido. Uno de ellos, que se utiliza habitualmente y queda sobreentendido, hace uso de los marginales de respuesta, que se observan en los
reactivos seleccionados a partir de un universo de actitud, para obtener puntos de corte o para establecer rangos de contenido.
El otro método utiliza puntos de torsión de las regresiones de los componentes principales superiores de
actitudes mensurables, para obtener los diferentes puntos de corte.
Con base en un modelo matemático, se han propuesto cuatro variables psicológicas como componentes principales de actitudes mensurables por escala. La intensidad, segundo componente, se concibe como un medio para obtener una dicotomía de los sujetos, a lo largo de un
continuo de contenido, en actitudes positivas y negativas. El tercer componente,
identificado provisionalmente como cierre, se pretende que discrimina entre los sujetos dentro de la dicotomía positiva-negativa. Por tanto, se considera que la
función del tercer componente es la de colocar a los sujetos en posiciones de positivo extremo, positivo moderado, negativo moderado y negativo extremo.
Se supone que cada componente principal superior da lugar a puntos de corte
teóricamente más objetivos y más significativos. El análisis matemático, de Guttman, propone un número
infinito de componentes principales para las escalas perfectas. Este análisis matemático, que usa el criterio de consistencia interna máxima, en el sentido de
mínimos cuadrados, predice también el tipo de curva obtenida cuando la regresión de un componente se dibuja sobre el orden jerárquico original de las escalas
perfectas. En relación con éstas, la primera mejor solución produce una
relación lineal. La segunda mejor solución establece el segundo componente, que da una curva en forma de U y un solo punto de inflexión. Se obtiene un punto de
torsión adicional para cada solución o componente superior sucesivo. Aunque Guttman informa de cierto grado de éxito en la prueba
del cierre y de la involución como referentes empíricas de los componentes matemáticos tercero y cuarto, la investigación subsecuente indica que estas
variables componentes y otras más que ha propuesto no satisfacen los criterios fijados por el modelo matemático (Henry, 1957; Riland, 1959; Dotson, 1962). Sin
embargo, es común que se establezca el contenido y la intensidad. El primer componente es el del contenido con respecto a un
universo específico de actitud. Por ejemplo, la actitud entre los blancos sureńos hacia la segregación de los negros podría ser ese universo mensurable de
contenido. El segundo componente, considerado generalmente, es la
intensidad con que se mantiene la actitud. Cuando se dibuja la intensidad de la actitud en contraste con su rango de contenido, debe obtenerse una curva en
forma de U, en la que los sujetos más negativos y los más positivos muestran intensidades altas. La investigación empírica sugiere que el punto de torsión de
la curva de intensidad indica un "punto de indiferencia" o punto cero, en el orden jerárquico fundamental. Guttman, (1954) además, sostiene que el punto de
inflexión separa a los sujetos en tipos escalares positivos o negativos, según a qué lado del punto cero estén ubicados.
Brim adopta una posición diferente. Indica que "las respuestas de contenido a las preguntas de actitud se basan en una clase de expectativas
P1, que se refieren a probabilidades acerca de la satisfacción que se logrará en varios estados de cosas" (1955,). El cree que la intensidad o "fuerza del
sentimiento" es equivalente a una estimación P2 de que la primera expectativa es correcta". Brim indica que el punto de torsión de la curva de intensidad seńala
a los sujetos que no saben si deberían o no estar satisfechos con el estado de cosas que describen los reactivos. De esta manera, los sujetos que caen en tipos
escalares a un lado del punto cero se definen como aquéllos que estiman la probabilidad de satisfacción superior al 50%. Los que caen al otro lado
(negativo) se definen como aquéllos que estiman la probabilidad de satisfacción inferior al 50%. Esta es en esencia la discusión de Brim y Guttman, muchos
investigadores adoptan la posición de Henry: Si se acepta que el punto cero define a aquéllos que no saben
cuál sería su satisfacción probable -por consiguiente, la estiman 50-50 de acuerdo con un principio de "equiprobable por defecto de la ignorancia"- o que
define a aquéllos que no les interesa o son indiferentes, parece que nos hallamos ante una técnica útil para separar los favorables de los desfavorables
(1957). Pueden obtenerse medidas de intensidad ya sea por la técnica
de doblado o por la de bipartición, ninguna de las cuales forma escalas en el sentido de Guttman (Suchman, 1950). La técnica de doblado implica el uso de
reactivos que midan las dimensiones de contenido e intensidad simultáneamente. Para obtener puntuaciones de intensidad mediante esta técnica, con reactivos
compuestos de seis categorías de respuesta, las categorías positiva extrema y negativa extrema se combinan o "doblan" para obtener valores de intensidad más
altos; las categorías positiva media y negativa media se combinan para formar una puntuación de intensidad baja; y las respuestas positiva mínima y negativa
mínima se doblan para formar el valor de intensidad más bajo. Se asignan después valores arbitrarios, por ejemplo 2, 1 y 0 a las tres categorías de intensidades
respectivamente. De esta manera se da a cada sujeto una puntuación de intensidad con respecto a cada reactivo; y finalmente se suman las distintas puntuaciones
de intensidad de cada individuo. La técnica de bipartición emplea una pregunta de intensidad
diferente, con respecto a cada pregunta de contenido. Por ejemplo, después de un reactivo de contenido se formula una pregunta de intensidad como ésta: "żQué tan
profundo es su sentimiento con respecto a X? " Se utilizan opciones de respuesta del tipo 1. "muy profundo", 2. "mediano" y 3. "leve"; luego se asignan valores
arbitrarios y se suman según la respuesta de cada sujeto, como en la técnica de doblar. De ambos métodos, la técnica de doblado tiene la cualidad de economizar
espacio en un cuestionario; sin embargo, la técnica de bipartición proporciona mayor rigor, en la medición debido a la independencia de las medidas de
contenido e intensidad. La tabulación transversal de las puntuaciones de intensidad y
contenido de todos los sujetos, sirve para ubicar el punto de indiferencia o punto cero en el continuo del contenido. Después de colocar a los sujetos en los
tipos escalares definidos por los puntos de corte, resultantes de la observación de marginales de respuesta en reactivos de contenido, se computa el rango
mediano de intensidad para cada rango de contenido. La curva de estas medianas se usa como una aproximación a la curva de regresión del segundo componente
intrínseco. "Se usan las medianas y no las medias aritméticas o promedios similares, porque aquéllas son independientes de cualquier métrica, excepto del
orden jerárquico" (Suchman, 1950). Los valores correspondientes a los puntos dibujados se
determinan de la siguiente manera: Se computan porcentajes acumulativos con respecto a las
frecuencias totales tanto de contenido como de intensidad, acumulando del negativo al positivo en contenido y del menor al mayor en intensidad. Para
determinar el valor de contenido que se va a dibujar, calculamos el punto medio del intervalo de percentiles correspondiente a cada rango de contenido. El valor
de intensidad que se dibuja es el percentil de intensidad mediano del rango de contenido. . . (Suchman, 1950).
Para determinar la mediana de datos agrupados; es aplicable la fórmula general:
Mediana = lx +
(N/2 - fx acu/fx)(i)
donde lx es el límite inferior del intervalo que contiene a la mediana, N es el
número de casos incluidos en el análisis, fx acu es la suma acumulativa de las frecuencias absolutas hacia arriba, sin incluir el intervalo que contiene la
mediana, fx es la frecuencia absoluta en el intervalo que contiene la mediana e i es el tamańo del intervalo. Como ejemplo, véanse la tabla 1 y la figura 2, que
ilustran este punto. Para computar la puntuación mediana de intensidad para el tipo escalar 0, en la tabla 1, los valores que se sustituyen en la fórmula son:
Mediana = 49 + (209/2 - 68 )/51 (69 -49)
= 49 + (.71) (20) = 63. Este valor mediano de intensidad se dibuja después para representar el punto medio de rango 0 de
contenido, en la figura 2. Cuando se dibuja el valor mediano de la intensidad de cada uno de los rangos de contenido, se obtiene una curva de regresión en forma
de U o J (figura 2). El punto cero o zona de indiferencia, en la figura 2, se ubica en el tipo escalar 2. De esta manera, los tipos escalares 0 y 1 se definen
como negativos y los tipos escalares 3 y 4 como positivos. El procedimiento anterior
hace uso de la regresión de intensidad sobre el contenido para identificar la zona de indiferencia. Una ubicación más precisa del punto cero puede obtenerse
por medio de lo que Guttman llama la técnica de "punta de flecha", en la que la colocación se determina por la regresión del contenido sobre la intensidad. "La
estimación que se emplea es el percentil mediano de contenido del subgrupo con el rango de intensidad más pequeńo (seleccionando, por ejemplo, no menos de 100
personas con este grupo de intensidad menor, a fin de conservar la confiabilidad del muestreo)" (Guttman, 1954).
Usando la misma fórmula general anterior para calcular la mediana de datos agrupados, se determina el
punto cero correspondiente a los datos de la tabla 1, combinando los rangos de intensidad menores para proporcionar un número suficiente de observaciones.
Combinando los rangos originales de intensidad 0, 1 y 2, se colocan 146 sujetos en la categoría de intensidad más pequeńa. La mediana cae en el rango de
contenido que incluye el caso número 73. Sumando transversalmente los rangos de contenido, se encuentra que la mediana cae en el rango 2 de contenido. La
mediana del percentil de contenido correspondiente al rango de intensidad más pequeńo, en este caso, se obtiene entonces como sigue:
Por tanto, para estos datos el punto cero se ubica en el
percentil 57; y puede concluirse que aproximadamente el 57% de los sujetos fueron negativos en su actitud y el 43% positivos.
El punto de corte o punto cero, definido por la función de intensidad, tiene la propiedad de invarianza, es decir, no depende de la muestra
de reactivos que se use. La invarianza del punto cero se ha demostrado empíricamente al comparar los análisis de intensidad de dos conjuntos de
reactivos procedentes del mismo universo de contenido. Aunque un conjunto de reactivos estaba inclinado negativamente y el otro positivamente, se obtuvo la
misma curva de intensidad para ambos grupos de datos (Schuman, 1950). El punto de torsión de la curva de intensidad tiene la
propiedad de invarianza, porque la métrica de contenido o de intensidad puede ampliarse o contraerse "y el punto de torsión seguirá en el mismo porcentil" (Guttman,
1954). Sin embargo, puede esperarse que el punto cero varíe de un estudio de población a otro y que varíe en una población a través del tiempo. Por
consiguiente, el análisis de intensidad es útil para comparar dos poblaciones y para medir el cambio en una población a través del tiempo.
Han transcurrido ya varios ańos desde que Guttman desarrolló la teoría de los componentes principales de actitudes mensurables por escala.
Durante este tiempo se ha realizado poco con respecto al aislamiento e identificación de referentes empíricos para los componentes tercero y cuarto.
Los ańos venideros pueden demostrar que el modelo de Guttman no produce mejor ajuste con el mundo empírico; sin embargo, la utilidad de la intensidad y su
ajuste al modelo matemático sugiere la validez del modelo entero. Se considera que los puntos de torsión de cada una de las curvas de regresión de los
componentes superiores poseen la misma propiedad de invarianza que el punto de torsión de la curva de intensidad. Además, el modelo es más preciso con respecto
a la relación entre los puntos de torsión de un conjunto de componentes (Guttman, 1954). De esta manera, se suministran al investigador criterios para aceptar o
rechazar variables como componentes empíricos tercero y cuarto de actitudes mensurables por escala. La investigación futura en la teoría de componentes
puede ser muy provechosa. Indudablemente, son grandes los beneficios potenciales que ofrece la identificación de correlatos de los componentes para el
perfeccionamiento de la medición cualitativa.
COMO ELABORAR ESCALAS TECNICAS DE GUTTMAN Introduccion. Desde los primeros trabajos de Guttman, la escala monodimensional ha sido ampliamente usada por sociólogos y psicólogos sociales.
Su utilidad se revela no solamente por el número de científicos sociales que la han empleado sino por el número de mediciones diferentes para las que se ha
adaptado. Aunque desde su aparición han transcurrido ya medio siglo, que ha servido para evaluar exactamente su contribución a la sociología y a la
psicología social. Es verdad que la técnica de Guttman permite el tratamiento de
datos cualitativos sin hacer la discutible conversión a datos cuantitativos como se hace en algunas otras técnicas de elaboración de escalas. De esta manera, los
investigadores han reducido al mínimo las interpretaciones erróneas, al evitar suposiciones de medida equivocadas. Pero lo más importante para el desarrollo de
la ciencia conductual es que el modelo de Guttman contenga cierto mecanismo intrínseco (el coeficiente de reproductibilidad) por el cual uno se ve obligado
a examinar la consistencia interna de los reactivos que componen la escala.
Este mecanismo compele la atención hacia lo que realmente se
está midiendo. Aunque en ocasiones se han obtenido medidas "estériles", no
obstante las pruebas de consistencia interna, generalmente los requerimientos de
reproductibilidad han favorecido la mayor claridad conceptual. Es,
indudablemente, difícil examinar la consistencia interna de un conjunto de
reactivos sin ocuparnos de lo que realmente se está midiendo o, por lo menos, de
lo que se está haciendo variar en los reactivos, para explicar la variación de
las frecuencias de respuesta, de tos reactivos. Es asimismo inevitable la
obtención de mayor claridad conceptual sobre el requerimiento de que, cada vez
que se use una escala, su consistencia interna haya de ser reexaminada. Así,
cuando con un conjunto de reactivos puede hacerse una escala para un grupo pero
no para otro, o suceda lo anterior con un grupo particular en el tiempo 1 pero
no en el tiempo 2, es preciso explicar el porqué. La técnica de Guttman ha
suministrado además un modelo para la organización de datos colectivos y otros
no actitudinales (Rifey y colaboradores, 1954). Ha habido y han sido estimulados
los considerables esfuerzos por mejorar el procedimiento original, de Guttman,
para elaborar escalas. La mayoría de las mejoras al método de Guttman para construir
escalas, desde los últimos ańos de la década del 40, se han concentrado en las
técnicas para evaluar una escala (es decir, las técnicas para determinar con más
precisión el grado en que un conjunto de reactivos se convierte en una escala
eficaz) y en la mecánica de la elaboración de escalas cuando se utiliza equipo
electrónico de procesamiento de datos.
Aunque parece que existe mayor interés en los criterios del
reconocimiento de errores que en los criterios de prevención de los mismos, en
la construcción de escalas ha habido notables aportaciones. Entre ellas se han
seleccionado para su estudio:
La mecánica de Guttman de elaboración de Escalas La noción básica de la escala de Guttman o acumulativa es que
entre los reactivos que forman la escala existe una relación interna tal, que una persona que ratifica o concuerda con un reactivo que ocupa una posición
escalar dada, ratificará todos los reactivos que estén por debajo de ella en la escala. Si se sabe que una persona ratificó tres reactivos de una escala
compuesta de cuatro, se sabe también cuáles fueron los tres reactivos que ella ratificó. Por otra parte, todos los individuos que ratifiquen solamente tres
reactivos, ratificarán los mismos tres. De esta manera, es posible ordenar a los individuos en categorías o posiciones relativas definidas por las posiciones de
los reactivos ratificados. Es cierto, empero, que estas cualidades de la escala de Guttman se deterioran a medida que disminuye la consistencia interna.
Se han inventado varias técnicas para elaborar escalas de Guttman. En el trabajo inicial se usó la técnica de tablas de escalograma (Suchman,
1950). En este procedimiento se usaba una tabla compuesta de una serie de tablillas movibles en las que se colocaban marcas que representaban las
respuestas de los sujetos a cada reactivo. Las tablillas podían manipularse de tal manera que se podía determinar visualmente la consistencia interna de los
reactivos que componían la escala.
Se han desarrollado otras técnicas, que incluyen la técnica de Cornell (Guttman, 1947), el método de cuadrados mínimos (Guttman, 1941) y la
técnica de tabulación transversal (Toby y Toby, 1954), así como varias modificaciones de ellas para usarlas con equipo de procesamiento de datos y
computadoras electrónicas.
En algunas técnicas se emplean valores asignados arbitrariamente, los cuales se suman para obtener una puntuación escalar para
cada sujeto; en otras técnicas no se hace así. Pueden usarse valores, pero nada se gana con ello. A Stauffer se le da crédito por el desarrollo de una técnica
que no usa un sistema de valores. En esta técnica se determinan puntos de corte con respecto a reactivos de respuesta múltiple tratados en forma dicotómica al
tabular transversalmente cada reactivo con todos los demás. Se desarrolló con el fin de usarse en un clasificador electrónico de tarjetas, pero puede adaptarse
fácilmente para usarse con computadoras. Debido a su sencillez, este método, algo modificado, se resume más abajo. En esta técnica, como en otras que también
se usan para construir escalas de Guttman, debe predecirse el orden jerárquico de los reactivos antes de que los datos sean examinados. Al reactivo más difícil
(o el menos favorable) debe asignársele el rango 1, al siguiente más difícil, el rango 2,. . ., y al menos difícil, el rango n.
De esta manera, la confianza en una escala se incrementa en la medida en que la predicción del orden jerárquico de los reactivos se
fundamente en los datos. Para verificar la predicción del orden jerárquico, se determina la frecuencia de respuestas de cada categoría de respuesta con
respecto a cada reactivo. Por ejemplo, si cada reactivo tiene cinco opciones de respuesta, de "completamente de acuerdo", "de acuerdo", "en duda", "en
desacuerdo" y "completamente en desacuerdo", determínese la distribución de respuestas de cada reactivo y conviértanse en porcentajes acumulativos desde la
más positiva hasta la más negativa.
En el paso siguiente, esta información servirá para seleccionar los puntos de corte de los reactivos de selección múltiple que son
tratados dicotómicamente. Cuando los reactivos son verdaderamente dicotómicos, por ejemplo, si-no, de acuerdo-desacuerdo, se pueden determinar directamente los
porcentajes acumulativos. El paso siguiente es decidir lo que se considerará una ratificación (+) en cada reactivo. Generalmente, en un reactivo con las cinco
opciones de respuesta anteriores, marcar ya sea "completamente de acuerdo" o "de acuerdo" se interpretaría como ratificación (+). Marcar cualquiera de las
opciones restantes se consideraría como no ratificación (-) del reactivo. Con reactivos verdaderamente dicotómicos esto es muy sencillo; con reactivos de
opción múltiple no lo es. El punto de corte de un reactivo es el punto dentro de las opciones ordenadas, que separa la ratificación de la no ratificación. En este
ejemplo, el punto de corte está entre "de acuerdo" y "en duda". Hay ocasiones en que se desea trasladar el punto de corte. Esto, obviamente, cambia la proporción
de sujetos que ratifican el reactivo. Al mover el punto de corte hacia abajo, aumenta el porcentaje de ratificación; al moverlo hacia arriba, disminuye.
Existen, básicamente, dos razones para cambiar el punto de corte de un reactivo. Primero, porque puede ser conveniente cambiar la
distribución marginal de los reactivos. Por ejemplo, la distribución podría ser de 20, 30, 60, 80% de ratificación, con el punto de corte entre "de acuerdo" y
"en duda", con respecto a todos los reactivos. Al trasladar el punto de corte al reactivo del 30%, para incluir "en duda" como ratificación, puede convertirse
ese reactivo en uno de 40%. Esta es una distribución marginal, preferible por razones que serán descritas más adelante. Segundo, al trasladar el punto de
corte de un reactivo a veces es posible convertir un reactivo impropio de la escala en uno adecuado. Manteniendo constante, en la medida de lo posible, el punto
de corte de respuesta (por ejemplo, entre las respuestas "de acuerdo" y "en duda" en el grupo de opciones anterior), el investigador debe seleccionar los
reactivos que hagan máxima la distancia entre los reactivos marginales (la proporción de sujetos que ratifican el reactivo). Por ejemplo, una escala de
cuatro reactivos debe contener reactivos marginales de 20, 40, 60 y 80%. Cuanto más separados estén los marginales, tanto menos probable es una inversión del
orden de los reactivos del preexamen al estudio final, o en dos aplicaciones cualesquiera de la escala. Deben evitarse asimismo reactivos con marginales
extremos. Los reactivos necesariamente tienen reproductibilidades iguales a la respuesta modal (ya sea + o -). Esto quiere decir que reactivos con marginales
más grandes del 80% o de menos del 20% pueden infundir excesiva confianza en la factibilidad de hacer una escala del universo de contenido que se esté
considerando. En el conjunto de reactivos de ensayo seleccionado, cada uno de aquéllos debe contrastar con cada uno de los demás para determinar si los
reactivos se ajustan entre sí suficientemente para ser compatibles con el modelo de Guttman. En el caso de una relación perfecta entre dos reactivos, donde uno
es más difícil de ratificar que el otro, todos los sujetos que ratifican el reactivo con el marginal más pequeńo (el más difícil) deben ratificar también el
menos difícil.
El grado en que los reactivos satisfacen esta relación
perfecta se refleja en la "celdilla de error" de cada tabla cuádruple (véase figura 1). Ninguna celdilla de error debe contener más del 10% del número total
de sujetos. Y las celdillas de la diagonal principal (+ +) y (- -) de cada tabla deben contener al menos tantos casos como los que se encuentran en la celdilla
de error (Toby y Toby, 1954). El error del reactivo es la proporción de sujetos que ratifican el reactivo más difícil pero que fallan en el reactivo más fácil.
Una vez establecido el punto de corte de cada reactivo y su error, necesitan obtenerse los patrones de respuesta. Esto se logra determinando
las respuestas de cada sujeto en todos los reactivos. La sucesión de observaciones comienza con el reactivo menos frecuentemente ratificado y
continúa con los demás, en orden descendente de dificultad. Si se usa un clasificador de tarjetas y se tratan los reactivos en forma dicotómica, el
primer paso de las tarjetas por la máquina producirá dos grupos de tarjetas: uno representa a los sujetos que ratificaron el reactivo (+) y el otro, a aquéllos
que no lo ratificaron (-).
Cada grupo se corre después al segundo reactivo según su grado de dificultad. Esto puede producir cuatro grupos que representan a
quienes: 1. ratificaron el reactivo más difícil y el siguiente más difícil (+ +); 2. ratificaron el reactivo más difícil pero no el siguiente (+ -); 3. no
ratificaron el primero pero sí el segundo (- +), y 4. no ratificaron ninguno de los dos (- -). Luego, cada uno de estos grupos se corre al reactivo con la
tercera frecuencia más baja de ratificación, lo que podría generar ocho patrones de respuesta: 1. +++, 2. ++-, 3. +-+, 4. +- -, 5. -++, 6. -+-, 7. - -+, y 8. - -
-. E I procedimiento se continúa hasta concluir el examen de todos los reactivos que componen la escala. El número de patrones posibles de respuesta es una
función del número de reactivos.
Con respecto a reactivos dicotómicos, el número de patrones de respuesta posibles es 2n, donde n es igual al número de reactivos. Entonces
una escala de cuatro reactivos puede producir 16 patrones de respuesta (24) y una escala de ocho reactivos, 256 (28). Sin embargo, del número de patrones de
respuesta posibles, solamente n + 1 son tipos perfectos o puros, es decir, patrones de respuesta que indican tal consistencia de respuesta que si se
ratifica un reactivo en determinada posición escalar, todos los reactivos por debajo de él también lo serán. Por ejemplo, en una escala de cuatro reactivos,
los patrones de respuesta ++++, -+++, --++, - - -+ y - - - - son tipos puros. Los otros patrones donde se advierten fallas en presentar consistencia de
respuesta son tipos no escalares o de error. La colocación de los Tipos de
Error Habida cuenta de que, en realidad, la escala perfecta es sólo aproximada, inevitablemente existen algunos patrones de respuesta que no son
tipos aptos para una escala y deben asignarse a patrones de respuesta perfectos o puros. Existen varios métodos para clasificar las respuestas no escalares. El primer criterio que se usa en este procedimiento es
reducir al mínimo el error. En sentido estricto, el sujeto ha cometido error cuando se desvía en su patrón de respuesta del tipo escalar puro. El problema
consiste entonces en colocar su patrón de respuesta en uno de los tipos escalares puros, de manera que su desviación produzca la mínima cantidad de
error. Por ejemplo, usando este criterio, el patrón -+- - (del más al menos difícil, de izquierda a derecha) puede asignarse solamente al tipo escalar 0
(----). Cualquier otra asignación daría dos o más errores. Si fuera colocado en el grupo escalar 1 (-- -+), se admitirían dos errores asociados a los reactivos
2 y 4. Si se colocara en el tipo escalar 2, contendría tres errores que abarcarían los reactivos 2, 3 y 4.
El criterio de error mínimo resolverá el problema de clasificar las respuestas no escalares cuando no sea posible más que una asignación. Sin embargo, hay
patrones que pueden clasificarse en dos o más tipos escalares empleando este criterio. La respuesta +-++ podría considerarse ya sea como el tipo escalar 2
(--++), con un error asociado al primer reactivo, o como el tipo escalar 4 (++++), donde el segundo reactivo explica un error.
En aquellos casos en que el criterio de error mínimo asigna un patrón de respuesta a dos o más tipos escalares, se han desarrollado varias soluciones.
Cuando hay razón para creer en la presencia de error de respuesta sistemático en los reactivos con los marginales más grande y más pequeńo, podría emplearse la
técnica del valor medio, la cual confiere mayor valor a los reactivos intermedios. La decisión con respecto a la colocación de respuestas clasificadas
ambiguamente, por el criterio de error mínimo, se determina con las respuestas a los reactivos intermedios. Por ejemplo, el patrón +-++ podría colocarse ya sea
en el tipo escalar 2, o en el 4, con un error. Si se colocara en el tipo escalar 2, el reactivo 1, un reactivo extremo, explicaría el error. La asignación al
tipo escalar 4 colocaría el error en el reactivo 2. Si el análisis de reactivos descrito anteriormente hubiera indicado que el reactivo 1 estaba sujeto a error
considerable, suponer una probabilidad de error más grande en el reactivo 1 que en el 2 quedaría justificado. Por consiguiente, se tomaría la decisión, con base
en la confiabilidad más grande del reactivo 2, de asignar el patrón de respuesta al tipo escalar 2, dándosele así un valor mayor al reactivo intermedio. (Henry,
1952). Una segunda solución de la clasificación ambigua es la técnica de valor extremo. Supuestamente puede usarse cuando se sospecha de los reactivos intermedios. En
el ejemplo anterior, la respuesta +-++ se colocaría en el tipo escalar 4 cuando se usara la técnica de valor extremo en virtud de las diferentes suposiciones
con respecto a la ubicación del error. (Henry, 1952). Una solución alterna, el método de la distribución de tipos escalares perfectos,
se ha convertido tal vez en la técnica empleada más frecuentemente para clasificar patrones que se asignan a dos o más tipos escalares por medio de la
solución del error mínimo. De este método, se dice que "predice las soluciones de `Distancia Latente Modificada' con mucho mayor eficiencia... (Henry, 1952)"
que las técnicas de valor extremo o de valor medio y es mucho menos complejo que la técnica de distancia latente desarrollada por Lazarsfeld. La solución de la distribución de tipos escalares perfectos
es seleccionar entre ellos los tipos escalares seńalados por el criterio de error mínimo, es decir, el tipo escalar con la frecuencia mayor. Se hace el
seńalamiento por este tipo escalar si la diferencia entre las frecuencias de dos tipos puros es estadísticamente significativa (ji cuadrada, 1 g.l., a nivel de
.10) (Henry, 1952). En el ejemplo el patrón +-++ podría colocarse en los tipos escalares 2 o 4 con un error. Si el tipo escalar 2 contuviera 98 casos y el tipo
escalar 4 fueran 32 casos, el patrón se clasificaría como tipo escalar 2, porque ocurrió con mayor frecuencia. Cuando se usa esta técnica, el tipo no escalar se
asigna al tipo puro del que tiene mayor probabilidad de desviarse. Otra solución al problema de clasificar los tipos no
escalares cuando el criterio de error mínimo es ambiguo, es la técnica de seńalamiento de la clase media, sugerida por Borgatta y Hays (1952). Esta
técnica coloca un patrón ambiguo de respuesta en medio de las dos clases más extremas determinadas mediante el criterio de error mínimo. Borgatta y Hays
seńalan el cuidado que debe tenerse con cada una de las técnicas arbitrarias anteriores con respecto a la clasificación de patrones de respuesta no
escalares; ellos recomiendan, en lo posible, el análisis de distancia latente más complejo. Métodos para estimar la Consistencia Interna La estimación de la consistencia interna de un conjunto de
reactivos viene después de la colocación de los tipos no escalares. Como método para el propósito mencionado, Guttman (1950) propuso el coeficiente de
reproductibilidad 1 - (error total de colocación/sujetos sujetos X reactivos) y fijó algo arbitrariamente un mínimo de .90 como necesario para suponer
monodimensionalidad. De acuerdo con este estándar, la cantidad de error tolerado no excede al 10%. El coeficiente de reproductibilidad ha sido y continúa siendo
la estimación más frecuentemente usada de consistencia interna, aunque sus limitaciones sean reconocidas. Como demostraron Menzel (1953) y Borgatta (1955);
no se aproxima a cero en ausencia de consistencia interna. Para entender esta debilidad basta darse cuenta que un sólo reactivo no puede tener más error
que su respuesta modal. Por ejemplo, un reactivo ratificado por el 80% de los sujetos puede tener un máximo de 20% de error. De esta manera, un conjunto de
reactivos sin consistencia interna tendrá, necesariamente, cierta reproductibilidad, de acuerdo con la estimación de Guttman. Considerándose que la reproductibilidad es una función de a)
reactivos extremos, b) individuos extremos y c) la adaptabilidad de los reactivos -con respecto a los sujetos- a una escala, Menzel propuso como medida
más satisfactoria el coeficiente de adaptabilidad á la escala 1 - (error total de colocación /error máximo ). El error máximo se calcula con base en la
diferencia entre el total de respuestas y la suma de las categorías modales ya sea de los reactivos o de los sujetos. La menor de las dos diferencias se usa
para estimar el valor máximo, al parecer para evitar la sobreestimación de la consistencia interna. Menzel indica que el límite inferior de un coeficiente
satisfactorio de adaptabilidad a la escala se encuentra .60 y .65. El coeficiente de adaptabilidad a la escala, de Menzel, es
una dudosa mejora sobre el coeficiente de reproductibilidad pues posee las mismas limitaciones. Como demostró Borgatta, el índice de Menzel también fracasa
en aproximarse a cero en ausencia de un contenido común en los reactivos. Borgatta propuso, como sustituto, la proporción de error:
Este índice varía de cero a uno y puede compararse a las proporciones de error de otras escalas. La proporción de error es la "proporción de errores en la
escala dividida entre el número máximo de errores en una escala con las mismas frecuencias marginales" (Borgatta, 1955). El número máximo de errores se calcula
utilizando la ley de probabilidades independientes para determinar las frecuencias esperadas de cada tipo no escalar, a partir de las marginales de
cada reactivo. Así, para determinar la frecuencia esperada del tipo escalar 4 (++++), en una escala de cuatro reactivos con marginales de 20, 40, 60 y 80%
se multiplican los marginales (.20 X .40 X .60 X .80), para obtener la proporción esperada en el tipo escalar (en este caso .0384), la cual a su vez se
multiplica por el número de sujetos, En cuanto a los tipos no escalares, la frecuencia esperada debe multiplicarse por el número de errores de seńalamiento,
para determinar la suma de estos errores con respecto a la distribución esperada. Esta suma se usa como número máximo de errores.
Por ejemplo, en una escala de cuatro reactivos con marginales (la proporción de respuestas de +) de 20, 40, 60 y 80% , la frecuencia esperada
del patrón de respuesta -+-- se determina multiplicando la proporción de respuesta de - (.80), para el primer reactivo, por la proporción de respuestas
de + (.40) para el segundo reactivo, por la proporción de respuestas de - (.40) para el tercer reactivo, por la proporción de respuestas de - (.20) para el
cuarto reactivo. Este producto (.026) se multiplica después por el número total de sujetos (N) para determinar el número de éstos de quienes se espera tengan el
tipo no escalar -+--. La frecuencia esperada debe multiplicarse después por el número de errores de correlación. En este caso el patrón -+-- puede asignarse al
tipo escalar 0 (- - - -) con un error. Por tanto, el número total de errores de colocación esperados con respecto a este patrón de respuesta, suponiendo que N
sea 2 000 es: (.80) (.40) (.20) _ .026 Este procedimiento se sigue con cada tipo escalar; y la suma
de los errores de colocación esperados con respecto a los tipos no escalares se usa como número máximo de errores en la computación de la proporción de error,
número de errores donde el número de errores es la suma de errores de colocación observados. Por
tanto, la proporción de error será de 1.00 cuando el número de errores de colocación sea igual al número máximo de errores y será 0.00 cuando no haya
errores de colocación. Consecuentemente, cuanto menor es la proporción, tanto mayor es la consistencia interna. La proporción de error parece que significa una
mejora determinante con respecto al coeficiente de reproductibilidad y al coeficiente de adaptabilidad a la escala. Sin embargo, acaso deba usarse la
proporción de error junto con la medida de Guttman, en beneficio de quienes no
están familiarizados con el índice de Borgatta. Pruebas significativas Ninguna de las anteriores estimaciones de consistencia
interna -el coeficiente de escalabilidad, el coeficiente de reproductibilidad, y la proporción de error- son pruebas de importancia estadística. Los problemas de
la estabilidad de los datos o de si los patrones observados son o no resultado del azar, no se han resuelto satisfactoriamente, aunque varios investigadores
han dedicado sus energías a buscar una solución. Intentos notables han sido realizados por Sagi (1959), Goodman (1959), Schuessler (1961) y Chilton (1966).
El problema ha sido atacado de varias maneras, desde el punto de vista de una prueba significativa de ji cuadrada (Schuessler) hasta la
demostración, por medio de datos generados por computadoras, de que los coeficientes de reproducibilidad están distribuidos normalmente (Chilton).
Como lo indicaron Sagi y Chilton, deben hacerse estas pruebas antes de la depuración de una escala, pues primordialmente sirven de
instrumentos para determinar qué posibilidad de éxito tendrán los esfuerzos ulteriores para desarrollar una escala a partir de un conjunto de reactivos. Las
distribuciones de muestreo de estos índices constituye uno de los aspectos de la elaboración de escalas, de Guttman, que todavía no se ha desarrollado. La
clarificación de estas distribuciones de muestreo es indispensable; y una contribución decisiva a nuestro conocimiento de la medición de actitudes será el
establecimiento de dichas distribuciones.
Artículo Julio
2008
LA TÉCNICA CORNELL PARA EL ANÁLISIS DE ESCALAS Y DE INTENSIDAD Análisis de intensidad Cómo diferenciar los personas "favorables" de las `desfavorables". En virtud de que la opinión acerca del libro Una Nación de
Naciones es suficientemente factible de ser medida, es significativo decir que a un estudiante el libro le parece mejor que a otro. Existe una ordenación
jerárquica significativa de los estudiantes de acuerdo con su opinión del libro. Este orden se expresa por las puntuaciones escalares asignadas en el segundo
ensayo. Un estudiante con una puntuación más alta que otro expresa las mismas cosas o mejores acerca del libro (dentro del error escalar). Existe una pregunta ulterior de sumo interés para el investigador. Dado que los individuos pueden ser ordenados de acuerdo con su
grado de favorabilidad żhay algún punto de corte en este orden jerárquico, de tal manera que podamos decir que todas las personas a la derecha de ese punto
son "favorables" y todas las personas a la izquierda son "desfavorables"? Una persona puede ser más favorable que otra, no obstante que ambas sean favorables.
La sola obtención de un orden jerárquico no distingue entre ser favorable o desfavorable; meramente refleja que se es más favorable y menos favorable y no
dice si se ha alcanzado un punto después del cual el ser menos favorable significa realmente ser "desfavorable". Se da una respuesta objetiva a este problema mediante la función de intensidad. La teoría del análisis de intensidad será explicada con todos sus pormenores en la próxima publicación de la División de Investigación. Para
nuestros propósitos, todo lo que necesitamos saber es que proporciona una solución al problema tradicional de la "disposición". No importa cómo sean
expresadas o "cargadas" las preguntas, el uso de la función de intensidad dará al grupo la misma proporción de favorable y desfavorable. La función de
intensidad establece un punto cero invariante para actitudes y opiniones. Hay varias técnicas para obtener la intensidad de un cuestionario. La primera es la técnica de doblar y la segunda, la de
bipartición. La técnica de doblado es teóricamente menos admisible que la de bipartición. Tiene sin embargo, algunas ventajas prácticas en ciertos casos.
La técnica de doblar. La técnica de doblar consiste sencillamente en recalificar el contenido de las preguntas para obtener una
puntuación de Intensidad. Esto es muy fácil, a causa de la forma de la pregunta empleada para estudiar las opiniones sobre Una Nación de Naciones. Se
asignan los siguientes pesos a la lista de confrontación de respuestas: "Completamente de acuerdo" y "Completamente en desacuerdo" reciben un
valor 2; "De acuerdo" y "En desacuerdo" reciben el valor 1; y "En duda" recibe el valor 0. Estos valores pueden escribirse en tiras de papel
para poder ponerlos en la tabla 1 y agregarlos allí para obtener así una puntuación de intensidad para cada persona. Así, las respuestas aparentemente más intensas reciben valores mayores; y las aparentemente menos intensas reciben valores menores,
independientemente de que las respuestas parezcan "favorables" o "desfavorables". Valorar así las respuestas significa que, para obtener una puntuación de
intensidad, combinamos, de hecho, los extremos opuestos de la lista de confrontación, de modo que no hay sino tres categorías (combinadas) de
intensidad por pregunta. La intensidad, obtenida por este medio, no es en general factible de ubicarse en una escala. En vez de ello, forma lo que se
llama una "quasi" escala. En una "quasi" escala no hay ninguna relación exacta entre la respuesta de una persona a cada pregunta y su
puntuación en todas las demás; en su lugar, hay un gradiente. Cuanto mayor es la puntuación de una persona, tanto más probable es que dé una respuesta altamente
valorada en cada reactivo, pero no existe la clara certeza de que así ocurra en el caso de una escala. Tal puede advertirse en nuestro ejemplo. Al arreglar los
datos en un escalograma, de acuerdo con la puntuación total de intensidad, obtenemos la configuración que se ofrece en la tabla 4. Cada pregunta tiene
ahora tres categorías que representan los tres pasos de intensidad. Hay un gradiente de densidad de las respuestas. No hay líneas definidas en las columnas
de las categorías y, no obstante, disminuyen gradualmente las densidades que mezclan una categoría con la siguiente. La combinación de categorías no
producirá, sin embargo, un patrón mensurable.
De acuerdo con la teoría básica del análisis de intensidad, ésta debe ser una variable perfectamente mensurable por escala. Las ecuaciones
del análisis escalar muestran que, en toda escala de contenido, hay un segundo componente que es una función de las puntuaciones escalares en forma de U o J.
Este componente se ha identificado como la función de intensidad de la escala de contenido. Lo que intentamos hacer es obtener esta intensidad por medio de
métodos empíricos directos. El hecho de que nuestra intensidad observada no sea perfectamente mensurable por escala muestra que no es la intensidad intrínseca
pura lo que estamos buscando. Tampoco se ha encontrado ninguna manera perfecta de obtener la intensidad; pero se logran resultados satisfactorios hasta con
técnicas de intensidad imperfectas. En vez de una función perfecta de intensidad, obtendremos una en la que es posible obtener un error considerable
en su relación con las puntuaciones de la escala de contenido. Trazo de la intensidad en contraste con el contenido.
La función empírica de intensidad se obtiene ordenando las puntuaciones de intensidad resultantes en contraste con las puntuaciones de contenido, obtenidas
en la sección anterior durante el segundo ensayo de contenido. El diagrama de dispersión se presenta en la tabla 5. La frecuencia, en letras cursivas, en cada
columna de la tabla 5, corresponde a la posición de la mediana de intensidad de las columnas respectivas. Si se estuviera midiendo la intensidad intrínseca pura
con esta técnica, no habría dispersión alrededor de estas medianas; pero la intensidad sería entonces una función perfecta de las puntuaciones de contenido
en forma de U o J. No obstante la presencia de error, la forma aproximada de la función verdadera de intensidad es clara a partir de la forma de la curva que
pasa por las medianas de las columnas. La curva desciende desde la derecha, o sea de las puntuaciones más favorables de contenido, alcanza su punto más bajo
en el segundo intervalo de la izquierda (puntuaciones de contenido de 3-5) y después vuelve a elevarse en el primer intervalo de la izquierda. En
consecuencia, las puntuaciones de contenido 3-5 deben formar el intervalo aproximado que contiene la puntuación 0 de la actitud. Puede decirse que los
estudiantes a la izquierda de este intervalo tienen actitudes negativas hacia el libro de texto y los que están a la derecha tienen actitudes positivas hacia él.
Los estudiantes en el intervalo 3-5 no pueden dividirse en positivos y negativos sin la ayuda de preguntas adicionales que hagan distinciones más precisas entre
sus rangos. Con base en la tabla 5 podemos concluir, entonces, que
aproximadamente a 8 estudiantes no les gustó el libro de texto, a 35 sí les gustó, mientras que 7 estudiantes mantuvieron una posición intermedia. Esta
división de los estudiantes en actitudes favorables y desfavorables no depende de la manera particular como se expresaron las preguntas. La misma curva de
intensidad, con la misma proporción a la derecha y a la izquierda del punto cero, se habría obtenido si hubiéramos usado otras preguntas u otra forma de
expresarlas, con tal que éstas fueran susceptibles de medición escalar con las preguntas presentes.
Necesidad de una muestra más grande de personas. Es preciso hacer una advertencia importante. El ejemplo empleado debe considerarse
muy afortunado para los fines de esta exposición. Ciertamente es raro encontrar un error tan bajo como el que tenemos en la función de intensidad, lo cual da
margen a que aparezcan claramente la curva de intensidad y el punto cero con base en una pequeńa muestra de 50 casos. En general, es muy difícil que esto
suceda. Para realizar sobre seguro un análisis de intensidad, cuando hay un error sustancial -que es el caso habitual- generalmente se necesitan de uno a
tres mil casos para obtener medianas estables. Para realizar el análisis de escalograma es también más seguro utilizar más de 50 casos. Lo deseable es
utilizar un mínimo de cien casos en el pre-test, así como una docena de reactivos o poco más o menos, en lugar de los siete de nuestro ejemplo. Si el
pre-test ha demostrado que para el universo de reactivos es factible hacer una escala, debe hacerse el estudio final con el número acostumbrado de casos que se
emplean en las encuestas de opinión, en caso de que se quieran obtener resultados confiables con respecto a la intensidad. La hipótesis de factibilidad
de la escala puede probarse en pre-test con un número relativamente pequeńo de personas teniéndose en cuenta su carácter especializado. Sin embargo, las
proporciones de la población en un rango dado o a un lado del punto cero están sujetas al error de muestreo ordinario; para llegar a resultados confiables con
respecto a ellas, deben usarse muestras más grandes. Desventajas de la técnica de doblar. La técnica de doblar aplicada ala intensidad tiene dos desventajas teóricas, así como álgunas
de orden práctico. Primero, las puntuaciones obtenidas por medio de ella no son independientes, experimentalmente, de las puntuaciones de contenido, pues se
sirven de las mismas respuestas con respecto a ambas puntuaciones. Esto puede producir una relación algo espuria entre aquéllas. Segundo, se supone que "Completamente
de acuerdo" y "Completamente en desacuerdo" son aproximadamente iguales en intensidad y opuestas en dirección; y lo mismo puede decirse de "De
acuerdo" y "En desacuerdo", mientras que se supone que "En duda" está aproximadamente en el punto cero. Dichas suposiciones no necesitan ser
ciertas en forma absoluta. De hecho, la falsedad ocasional de estas suposiciones es una contribución al error de las puntuaciones de intensidad obtenidas. Si las suposiciones fueran verdaderas, las cosas serían mucho más fáciles para los investigadores. No sería necesario formular una serie de
preguntas para obtener un intervalo de cero, porque la categoría "En duda", con respecto a cualquier pregunta, suministraría tal intervalo. Pero claro está
que en una serie de preguntas sobre el mismo asunto las personas que están "En duda", sobre una pregunta, pueden estar "De acuerdo" en otra.
Únicamente porque no podemos interpretar la inclinación de una pregunta al examinar su contenido, es que una técnica como esa necesita de la función de
intensidad. No obstante que la técnica de doblar posea dos desventajas teóricas, parece promediar los errores implícitos en la violación de las
suposiciones anteriores y suministrar una curva adecuada de forma U o J en muchos casos. Se le ha encontrado una desventaja práctica a la técnica de doblar, en las situaciones de entrevistas de personas en la calle, donde las
personas evitarían casi en absoluto las categorías "Completamente", de modo que no podría obtenerse mucha diferenciación de intensidad. En tal caso es
necesaria una técnica de bipartición. Una ventaja de la técnica de doblar sobre la técnica de bipartición es que requiere menos espacio y tiempo para la
aplicación de los cuestionarios. Artículo Junio 2008
LA TECNICA CORNELL PARA EL ANÁLISIS DE ESCALAS Y DE INTENSIDAD La representación de la gráfica de barras
La técnica de Cornell es un procedimiento para probar la hipótesis de que un
universo de datos de cualidades es una escala con respecto a determinada
población de personas, por el método de escalograma. Extendiéndose su uso a probar la
hipótesis de qué los datos forman una "cuasi" escala. De las varias técnicas existentes para análisis de escalograma,
la descrita aquí parece ser una de las más sencillas y convenientes para uso general. No requiere equipo especial; se vale de sencillos procedimientos de
oficina, que pueden ser realizados cómodamente por personas sin preparación estadística. Las diversas técnicas mencionadas realizan el mismo trabajo, puesto que usan la misma teoría del escalograma; difieren solamente en la manera de llevarla a la
práctica. En una primera técnica se emplearon las complicadas
computaciones de los cuadrados mínimos. El procedimiento empleado por la División de Investigación de la Universidad de Pennsylvania involucra el uso de tablas de escalograma,
inventadas especialmente por el autor para este propósito; estas tablas son sencillas de calcularse y fáciles de operar. Otro miembro de la División de
Investigación ha inventado una técnica de tabulación. La técnica de Cornell fue inventada por el autor, al principio con fines didácticos, pero posteriormente ha
demostrado su utilidad en propósitos generales de investigación. Los pasos iniciales son comunes a todas. Se comienza definiendo el universo de contenido que se va a estudiar. En un estudio de
actitud u opinión, esto significa decidir el contenido general de las preguntas que se van a formular. Como segundo paso, se define la población de individuos.
En una encuesta de actitud u opinión significa la delimitación de la clase de personas que se van a entrevistar.
Vienen inmediatamente dos tipos de problemas de muestreo. Uno
es el problema ordinario del muestreo aleatorio de personas y otro, el muestreo de reactivos. En estos dos problemas es conveniente distinguir entre la etapa de
pre-test de un estudio y la encuesta final. Pueden emplearse mucho menos
personas en el pre-test que en la encuesta final; pero pueden usarse menos reactivos en ésta y más en el pre-test. En el pre-test de una encuesta, alrededor de 100 personas constituyen por lo común una muestra adecuada de la población para probar la
hipótesis de factibilidad de la escala. Si se acepta la hipótesis, los reactivos pueden usarse entonces en el estudio final de 3,000 personas generales poco más
a menos, para obtener proporciones confiables dentro de cada rango escalar. El otro problema de muestreo es de naturaleza completamente diferente; consiste en muestrear el universo de contenido. En una encuesta de
actitud u opinión se hace elaborando algunas preguntas que tienen el contenido general requerido. En un pre-test, cerca de una docena de preguntas constituyen
generalmente un muestreo adecuado de contenido. Toda vez que las preguntas son elaboradas por los investigadores, no encajan en ningún esquema estándar de
muestreo aleatorio y la teoría estándar de este muestreo no se aplica en este caso. En su lugar, la teoría del análisis escalar muestra que casi cualquier
muestra de alrededor de una docena de preguntas tomadas del universo es adecuada para probar la hipótesis de que el universo es factible de ser evaluado por
escala, con tal que la amplitud de contenido deseada sea cubierta por las preguntas. Si se acepta la hipótesis de que es posible una escala para ese
universo, podrán usarse menos preguntas en el estudio final en caso de que se necesiten efectivamente menos rangos para los propósitos de la investigación. Habiendo definido el universo de contenido y la población de individuos y habiendo sacado una muestra de cada uno, el quinto paso es observar
a cada persona de la muestra en cada reactivo o pregunta de la muestra de estos. En una encuesta de actitud u opinión, en que se usan cuestionarios, lo anterior
quiere decir que cada persona da sus respuestas a cada pregunta del cuestionario. La hipótesis de factibilidad de lo escala. El problema ahora es probar la hipótesis, con base en los datos de la muestra de prueba, de que el
universo entero de reactivos forma una escala con respecto a la población de individuos. Revisemos lo que implica esta hipótesis para entender lo que trata
de hacer la técnica de análisis. Se dice que el universo es mensurable por escala con respecto
a la población si es posible ordenar a las personas de mayor o menor, de manera que a partir del rango de una persona solamente podamos reproducir su respuesta
a cada uno de los reactivos de un modo sencillo. Se entiende que en la práctica no se espera encontrar escalas perfectas. Se considera que los datos son
suficientemente adaptables a la es-escala si son reproductibles en cerca del 90% y si se satisfacen otras condiciones (que serán explicadas posteriormente). Para
mayor claridad, sin embargo, consideremos primero una escala hipotética perfecta. Supongamos que una pregunta perteneciente al universo, concerniente a cierto asunto político, es formulada a una población y que las
respuestas son las siguientes: Si "En desacuerdo" significa una opinión más favorable que "En duda" y "En duda"
más favorable que "En desacuerdo", y si el universo es perfectamente adaptable a una escala, lo siguiente debe ser verdadero. El 60% superior de la gente debe
estar formado por quienes contestaron "De acuerdo"; el siguiente 10%, por quienes contestaron "En duda"; y el 30% inferior, por quienes contestaron "En
desacuerdo". Si se formula otra pregunta de este universo mensurable por escala y las respuestas son un 20% de "Si"' y un 80% de "No", y si "Sí" indica una
respuesta más favorable que "No", entonces el 20% superior de las personas debe haber dicho "Si"' y el 80% inferior debe haber contestado "No". Del rango de una
persona podemos deducir ahora cuál debe ser su respuesta a cada una de estas dos preguntas. Cualquier persona en el 20% superior de la población debe haber
contestado "De acuerdo" a la primera pregunta y "Sí" a la segunda. Cualquier persona por debajo del 20% superior, pero no por debajo del 60% superior,
contestó "De acuerdo" a la primera pregunta y "No" a la segunda. Cualquier persona por debajo del 60%° superior pero no del 70 contestó "En duda" a la
primera pregunta y "No" a la segunda, y las personas restantes, el 30% inferior,
contestaron "En desacuerdo" a la primera pregunta y "No" a la segunda. Las diferentes técnicas de análisis de escalograma son procedimientos para encontrar el orden jerárquico de las personas que reproducirán mejor las
respuestas de éstas a cada uno de los reactivos. Si el universo fuera una escala perfecta, todas las técnicas requerirían poco trabajo y no habría mucho que
escoger entre ellas. Es la presencia de la imperfecta reproductibilidad lo que plantea el problema de la técnica. La técnica de Cornell opera por aproximaciones sucesivas. Generalmente sólo son necesarias dos aproximaciones para rechazar o aceptar la hipótesis de
factibilidad de la escala. Se establece un primer orden jerárquico de las personas mediante un esquema sencillo de calificación. Con propósitos
ilustrativos, desarrollaremos en detalle un caso real. Este ejemplo no debe considerarse un modelo de investigación perfecta, sino tan sólo una ilustración
de los pasos que se seguirán. Un ejemplo de la técnica de Cornell. Se deseaba saber si los estudiantes de
cierta clase sobre relaciones raciales tenían una actitud que pudiera medirse hacia uno de sus libros de texto, Una Nación de Naciones, de Louis Adamic. Se
elaboró un cuestionario de siete preguntas y se aplicó al grupo de 50 estudiantes. Tanto el número de preguntas como el de estudiantes fueron menores
a los que se emplean ordinariamente en un pre-test; y se usan aquí por la única razón de que estos pequeńos números permiten desplegar los datos completos. Las siete preguntas fueron las siguientes: Una Nación de Naciones Preguntas 1.- Una nación de Naciones hace un buen análisis de los
grupos étnicos de ese país. Completamente de acuerdo.- 4. De acuerdo.- 3. En duda.- 2. En
desacuerdo.- 1. Completamente en desacuerdo.- 0 2.- En general, Una Nación de naciones no es tan bueno
como la mayoría de los libros de texto universitarios. Completamente de acuerdo.- 0 De acuerdo.- 1 En duda.- 2 En
desacuerdo.- 3 Completamente en descuerdo.- 4 3,- Adamic organiza y presenta perfectamente su material. Completamente de acuerdo.- 4 De acuerdo.- 3 En duda.- 2 En desacuerdo.- 1 Completamente en desacuerdo.- 0 4.- Como tratado de sociología el libro de Adamic no tiene mucho valor. Completamente de acuerdo - 0 De acuerdo.- 1 En duda.- 2 En desacuerdo.- 3 Completamente en desacuerdo.- 4 5.- Adamic no estudia ningún grupo con suficiente detalle para que el estudiante pueda lograr una comprensión real de los problemas de las
relaciones de los grupos étnicos de ese país. Completamente de acuerdo.- 0 De acuerdo.- 1 En duda.- 2 En
desacuerdo.- 3 Completamente en desacuerdo.- 4 6.- Al ofrecer un panorama de los diferentes grupos, Una
Nación de Naciones da al estudiante una buena perspectiva de las relaciones de !os grupos étnicos de ese país. Completamente de acuerdo.- 4 De acuerdo.- 3 En duda.- 2 En desacuerdo.- 1 Completamente en desacuerdo.- 0 7.- Una Nación de Naciones es lo bastante bueno para usarse como libro de texto en este curso. Completamente de acuerdo.- 4 De acuerdo.- 3 En duda.- 2 En
desacuerdo.- 1 Completamente en desacuerdo.- 0 Análisis del contenido de la escala Ahora describiremos, paso a paso, cómo se realiza el análisis
de respuestas por medio de la técnica de Cornell: 1. En el primer ensayo se asignan valores a cada categoría de
cada pregunta, empleando los enteros sucesivos a partir de 0. En este ejemplo, como cada conjunto de respuestas tiene cinco categorías, los valores van de 0 a
4. En cada pregunta, se asignan los valores más altos a las categorías que se considera expresan una actitud más favorable. Este juicio sobre (os rangos de
las categorías no se considera definitivo. El análisis subsecuente verificará el juicio o bien determinará cómo realizarlo. 2. Se obtiene la puntuación total de cada persona sumando los
pesos de las categorías donde cae. En nuestro ejemplo, ya que el valor máximo para cada persona es 4 y el número total de preguntas es 7, las puntuaciones
totales pueden variar de 0 a 28. 3. Los cuestionarios se colocan en orden jerárquico conforme a las puntuaciones totales. En nuestro ejemplo, los hemos ordenado de mayor a
menor. 4. Se prepara una registro como la tabla 1, con una columna para cada categoría de cada pregunta y un renglón para cada persona. Ya que cada
una de las preguntas tiene cinco categorías y existen siete preguntas, tenemos 35 columnas en nuestra tabla. Son 50 estudiantes; así que debemos tener 50
renglones. Las primeras cinco columnas son para las cinco categorías de la primera pregunta, las siguientes cinco columnas para las cinco categorías de la
segunda pregunta, etc. 5. La respuesta de cada persona a cada pregunta se indica en la tabla con una X, en su renglón correspondiente, en la columna de cada
categoría en que cae. En nuestro ejemplo, hemos denominado las columnas empleando las preguntas y los valores de las categorías. La primera persona es
la que tiene la puntuación más alta, que es 28. Marcó la respuesta con valor 4 en todas las preguntas, así que tiene siete X en su renglón y en las columnas
respectivas de las categorías con valor 4. Hubo dos personas con una puntuación de 25. El arreglo de las personas con la misma puntuación es arbitrario. De las
dos personas de nuestro ejemplo con una puntuación de 25, la colocada primero dio una respuesta marcada con 4, en las dos primeras preguntas, una respuesta de
3 a la tercera pregunta, una de 4 a la cuarta pregunta, respuestas de 3 a la quinta y sexta pregunta y una de 4 a la séptima pregunta. De manera similar las
demás X de la tabla 1 indican las respuestas que las personas restantes dieron a cada pregunta. Cada persona contesta a cada preguntas; de manera que hay siete X
en cada renglón. Si en alguna ocasión las personas no contestan cierta pregunta, se agrega otra categoría titulada "Sin respuesta", que será valorada y tratada
como cualquiera de las otras categorías de esa misma pregunta. La tabla 1 da un registro completo de todos los datos
obtenidos en la encuesta.
6. Al final de la tabla 1 están las frecuencias de respuesta
de cada categoría. La categoría 4 de la pregunta 1 contiene nueve personas, mientras que la categoría 3 de la misma pregunta contiene 27 personas, etc. La
suma de las frecuencias de las cinco categorías de cada pregunta es siempre igual al número total de personas de la muestra, que en este caso es 50.
7. Ahora pasemos a la prueba de factibilidad de la escala. Si el universo es una escala y si el orden en que hemos colocado a las personas es
el orden jerárquico escalar, entonces la estructura de las X en la tabla 1 debe ser particularmente sencilla. Consideremos la primera pregunta de la tabla. Si
la respuesta de valor 4 es mayor que la de 3 y si la de 3 es mayor que la de valor 2, y si la de 2 es mayor que la de 1 (la respuesta de 0 no tiene ninguna
frecuencia en este caso), entonces las nueve personas de la categoría 4 deben ser las nueve personas superiores. Efectivamente, seis de ellas son superiores y
las otras tres están por debajo. De manera similar, las 27 personas de la categoría 3 deben estar debajo de las primeras nueve personas y descienden hasta
la trigésima sexta persona (36 = 9 + 27). Pero esto no es completamente cierto para nuestros datos. Un examen semejante con respecto a los demás reactivos
muestra que hay un error sustancial de reproductibilidad en su forma actual. En esta etapa no necesita contarse el número aproximado de errores, ya que es,
evidentemente, mayor que el 15% del total de 350 respuestas (350 = 7 X 50, el número de preguntas por el número de personas) de la tabla 1. 8. Rara vez se ha encontrado que un reactivo con cuatro o
cinco categorías sea suficientemente reproductible si las categorías se consideran diferentes. Una razón de esto son los hábitos verbales de las
personas. Algunas personas contestan "Completamente de acuerdo" donde otras dicen "De acuerdo", pese a que tienen esencialmente la misma posición en el
continuo básico aunque difieran en un extrańo factor de hábitos verbales. Combinando categorías pueden reducirse al mínimo las variables extrańas de
segunda importancia. Al examinar el traslapamiento de las X dentro de las columnas de cada pregunta, puede determinarse la mejor manera de combinar las
categorías para reducir al mínimo el error de reproductibilidad de las combinaciones. En la pregunta 2, por ejemplo, las categorías 4 y 3 parecen
entrelazarse, de modo que se combinan. Igualmente, y en la misma pregunta, parecen entrelazarse las categorías 1 y 0, por lo que también se combinan. Por
otra parte, en la pregunta 4, combinamos las categorías 3, 2 y 1, dejando aparte las categorías 4 y 0. La manera de combinar categorías se determina por separado
en cada pregunta. Las combinaciones escogidas en este ejemplo con base en la tabla 1 se dan en la tabla 2. TABLA 2 1
2
3
4
5
6
7
(4) (3) (2,1,0)
(4,3) (2,1,0)
(4,3,2) (1,0)
(4) (3,2,1) (0)
(4,3,2) (1,0)
(4,3) (2,1,0)
(4) (3) (2,1,0) Si se desean conservar muchos tipos escalares, debe hacerse la menor combinación posible. Sin embargo, si no se desean muchos tipos
escalares, pueden combinarse las categorías en el grado en que uno desee, aunque esto puede no mejorar la reproductibilidad. No es malo combinar las categorías
que de otra manera permanecerían diferentes con respecto al error escalar; todo lo que se pierde con tal combinación es un tipo escalar. Por otra parte, las
categorías pueden requerir combinación para reducir el error; deben combinarse de la manera indicada en la tabla 1 y no arbitrariamente. 9. Un segundo orden jerárquico de las personas puede
establecerse ahora con base en las categorías combinadas. Esto se realiza al reasignar valores. La primera pregunta tiene ahora tres categorías (es decir,
tres combinaciones), a las que se asignan los valores 0, 1 y 2. La pregunta 2 tiene ahora dos categorías. Podemos asignarle los valores 0 y 1. En el ejemplo
presente se usaron, en vez de aquéllos, los valores 0 y 2, ya que mantener relativamente constante la amplitud de los valores, de un reactivo a otro, ayuda
a menudo a establecer una ordenación mejor de las personas cuando existe error de reproductibilidad. En una escala perfecta, cualquier conjunto de valores, con
tal que tengan el orden de rango apropiado con respecto a las categorías, dará una correcta ordenación de rango de las personas. 10. A cada persona se da ahora una nueva puntuación que
representa su segundo rango de ensayo. Se le asigna al recalificar sus respuestas conforme a los nuevos valores. Esta recalificación se hace fácilmente
basándose en la tabla 1. Usando una tira de papel tan ancha como la tabla, pueden escribirse directamente los nuevos valores de las categorías anteriores
en la orilla de la tira. Colocando la tira a través del renglón de una persona, se suman los valores según donde caigan las X. En nuestro ejemplo, la tira
tendría en sus primeras cinco columnas los valores 2, 1, 0, 0, 0, colocándose el valor 2 en la columna donde estaba la vieja categoría 4, el valor 1 en la
columna donde estaba la vieja categoría 3, y los de 0 en las antiguas columnas de 2, 1 y 0 que después se combinaron. En la pregunta 2 la tira tendría en las
cinco columnas los valores 2, 0, 0, 0. De manera semejante pueden escribirse los nuevos valores de las otras preguntas que se emplearon en las columnas
anteriores de la tabla 1. La persona que era anteriormente la primera en dicha tabla, con una puntuación de 28, tiene ahora una puntuación de 2 + 2 + 2 + 2 +2
+ 2 + 2 = 14. La segunda persona de la tabla 1 también obtiene una puntuación de 14. La tercera persona de la tabla 1 tiene ahora una puntuación de 2 + 2 + 2 + 1
+ 2 + 2 + 2 = 13; y así sucesivamente con las demás. 11. Después se ordena a las personas conforme al orden
jerárquico de sus nuevas puntuaciones, y se prepara la tabla 3 a partir de los datos combinados, exactamente como se preparó la tabla 1 a partir de los datos
originales. La pregunta 1 tiene ahora tres columnas, la pregunta dos tiene dos columnas, etc. Los datos de la tabla 1 se modificaron para conformar la
tabla 3 según las combinaciones indicadas en la tabla 2. La columnas de la tabla 3 se refieren a las categorías combinadas y las puntuaciones de ésta son las
puntuaciones de segundo ensayo obtenidas precisamente en el paso anterior. 12. El error de reproductibilidad de la tabla 3 parece ser
mucho más pequeńo que el de la tabla 1, y en seguida contaremos los errores efectivos. Esto se hace estableciendo puntos de corte en el orden jerárquico de
las personas, los cuales las separan conforme a las categorías donde caerían si la escala fuera perfecta. En la pregunta 1, que tiene tres categorías,
necesitamos tres puntos de corte. El primero parece caer entre la última persona que tiene puntuación 12 y la primera persona que tiene puntuación 11. Todas las
personas que están por encima de este punto de corte deberían estar en la categoría 2, y todas las que están por debajo no deberían estar en esa
categoría. Pero como hay una persona, en la categoría 2, por debajo de este punto, tenemos un error en aquella. Se necesita un segundo punto de corte para
separar la categoría 1 de la categoría 0; no obstante, estas dos categorías se traslapan, por lo que su ubicación exacta no es esencial; así que mover el punto
ligeramente hacia arriba o hacia abajo no cambiará la cantidad de error. Debe colocarse de manera que éste se reduzca al mínimo; y tal reducción puede
lograrse de varias maneras similares. Una es colocar el punto de corte entre la segunda y la tercera persona con puntuación 4. Por debajo de este punto
encontramos tres errores en la categoría 1; y por encima de él, encontramos cinco errores en la categoría 0. El número total de errores en la pregunta 1 es
1 + 3 + 5 = 9. Dado que tenemos 50 respuestas a la pregunta 1, esta cifra significa un error del 18%. Claro que este error podría reducirse combinando las
dos últimas columnas y convirtiendo la pregunta 1 en una dicotomía. Habría así únicamente un error en la primera columna. Esta ulterior dicotomización se evita
cuando existe un error relativamente pequeńo en las otras preguntas, de modo que el error en el total de éstas no resulta muy superior al 10%. La pregunta 2 tiene dos categorías en el segundo ensayo; y el
punto de corte que reducirá al mínimo el error está entre las dos últimas puntuaciones de 6, lo cual produce dos errores en la primera columna y cuatro en
la segunda columna de la pregunta 2. Similarmente, la pregunta 3 tiene un punto de corte entre la última puntuación de 2 y la primera de 1; y suma tres errores
en su segunda columna. La pregunta 4 tiene dos puntos de corte; las preguntas 5 y 6, uno; y la 7, dos. El número total de errores en la tabla 3 es de 40, que es
el 11% de todas las respuestas. Por tanto, podemos concluir que en vista de que gran parte del error se presenta en la pregunta 1 y de que aquél puede
eliminarse combinando dos categorías en esa pregunta, esta área de actitud es factible de medirse por escala. A partir del orden jerárquico de una persona
podemos reproducir su respuesta a cada pregunta en términos de categorías combinadas con el 89% de exactitud (o mejor, si combinamos las dos últimas
columnas de la pregunta 1). 13. El porcentaje de reproductibilidad no es suficiente por sí mismo para llevar a la conclusión de que el universo de contenido es
mensurable. La frecuencia de respuestas a cada reactivo diferente también debe tenerse en cuenta por una razón muy sencilla. La reproductibilidad puede ser
artificialmente alta debido tan sólo a que una categoría de cada reactivo tiene una frecuencia muy alta. Puede demostrarse que la reproductibilidad de un
reactivo nunca puede ser menor que la frecuencia más alta de sus categorías, independientemente de si el área es mensurable o no. Por ejemplo, la pregunta 3
de la tabla 3 tiene un tipo de distribución completamente extrema. Cuarenta y tres estudiantes están en una categoría y siete en la otra. Entonces, en ninguna
circunstancia eran posibles más de siete errores en este reactivo, pese a que exista o no un patrón escalar. O también la pregunta 4 de la tabla 3 tiene 37
casos en su categoría modal y 13 en las otras dos categorías. Entonces, en ninguna circunstancia el reactivo 4 podía tener más de tres errores. Claro está
que cuanto más uniformemente estén distribuidas las frecuencias entre las categorías de un reactivo dado, tanto más difícil será que su reproductibilídad
sea espuriamente alta, Las preguntas 5 y 6 de la tabla 3 tienen una alta reproductibilidad, cada una presenta cinco errores; y no es artificialmente alta
porque la pregunta 5 solamente tiene 28 casos en su categoría más frecuente y la pregunta 6 tiene 30 casos en su frecuencia modal. El máximo error posible de la
pregunta 5 es 22 y de la pregunta 6, 20. El patrón escalar representa una reducción sustancial de este error máximo. La regla empírica que se ha adoptado
para juzgar lo espurio de la reproductibilidad escalar es la siguiente: ninguna categoría debe tener más errores que aciertos. Por tanto, la categoría con valor
2 en la pregunta 1 (tabla 3) tiene ocho aciertos y un error; la categoría con valor 1 en esta misma pregunta tiene 24 aciertos y 3 errores; la categoría 0
tiene nueve aciertos y cinco errores. De esta manera, la pregunta 1 satisface la regla. Pero la pregunta 3 está muy cerca de no cumplirla. Mientras que la
primera columna de la pregunta 3 (en la tabla 3) no tiene errores, la segunda columna tiene tres, junto con cuatro aciertos. De manera similar, la primera
columna de la pregunta 4 tiene un error en comparación con dos aciertos. Y como preguntas distribuidas uniformemente, como la 5 y la 6, tienen pocos errores; y
también porque los errores en las otras preguntas, como la 3 y la 4, no se apartan mucho de lo que debería ser, consideramos que esta área se puede medir
por escala. Al construir una muestra de reactivos que se usarán en una
prueba de factibilidad de la escala, por lo menos deben elaborarse algunos, si no es posible que todos, para obtener una distribución uniforme de frecuencias.
Tales reactivos dan una buena prueba de factibilidad. Sin embargo, es preciso disponer igualmente de reactivos con frecuencias no uniformes para obtener tipos
escalares diferenciados; por tal razón deben usarse los dos tipos de reactivos. Cuanto mayor es el número de categorías que se conservan en un reactivo, tanto
más severa es la prueba de factibilidad de la escala, porque el error -si realmente lo hay- tiene mayor posibilidades de aparecer cuando mayor número de
categorías haya. Artículo Mayo 2008 BASE PARA ELABORAR ESCALAS CON DATOS CUALITATIVOS
La representación de la gráfica de barras Otra manera de dibujar la escala dicotómica de la muestra de tres reactivos
sería la siguiente: supongamos que el 80% de la población contestó correctamente la primera pregunta, 40% la segunda y 10% la tercera.
Las distribuciones univariadas de los tres reactivos correspondientes podrían presentarse por medio de la gráfica de barras de la figura 3
Figura 3. Las barras muestran las distribuciones de porcentaje de las preguntas
respectivas. La distribución multivariada de las tres preguntas, dado que forman una escala de la población, también puede indicarse én la misma gráfica, ya que
todos los que se encuentran en el grupo que contestó correctamente una pregunta difícil, de la misma manera se encuentran en el grupo que contestó correctamente
una pregunta fácil. Así, podemos dibujar nuevamente la gráfica pero uniendo las barras con líneas interrumpidas como se ve en la figura 4. Aquí podemos apreciar
cómo las tres preguntas son funciones sencillas de las puntuaciones. De las frecuencias marginales de los distintos reactivos, junto con el hecho de que los
reactivos forman una escala, podemos deducir que el 10% de las personas obtuvieron una puntuación 3. El 10% que contestó correctamente la pregunta más
difícil se incluye entre los que contestaron correctamente las preguntas más fáciles. Esto se indica por la línea interrumpida de la derecha, entre las
puntuaciones 2 y 3, que delimita al mismo 10% de los individuos (los que tienen una puntuación 3), a través de las tres barras. El 40% que contestó
correctamente la segunda pregunta incluye al 10% que acertó en la pregunta más difícil y al 30% que contestó erróneamente la pregunta más difícil; pero todo el
40% acertó en la pregunta más fácil. Esto nos deja con el 30% que acertó sólo en la primera y en la segunda pregunta. Y así sucesivamente. De esta manera podemos
imaginar una ordenación de las personas a lo largo de un eje horizontal, y que cada reactivo es un corte sobre dicho eje. Todos los que están a la derecha del
punto de corte contestaron correctamente la pregunta y los que están a la izquierda la contestaron erróneamente. Por tanto, hay una correspondencia de uno
a uno entre las categorías de un reactivo y los segmentos del eje. O podemos decir que cada atributo es una función sencilla del orden jerárquico en el eje.
Figura 4. El hecho de que todos los reactivos de la muestra pueden
expresarse como funciones sencillas de la ordenación de las personas es lo que posibilita que formen una escala. Cada reactivo está perfectamente
correlacionado con la ordenación sobre el eje o es reproductible a partir de ella. Sin embargo, las correlaciones de punto entre los reactivos no son de
ninguna manera perfectas. Por ejemplo, la tabla cuádruple entre el primero y segundo reactivos es la siguiente:
La correlación de punto entre los dos reactivos es .41. De hecho, la correlación de punto entre dos reactivos dicotómícos puede ser cualquier valor desde
prácticamente 0 hasta la unidad y, no obstante, ambas pueden ser funciones perfectas de la misma variable cuantitativa. Esto, de aspecto paradójico, podría
explicarse por un inadecuado tratamiento de variables cualitativas en los cursos y textos convencionales de estadística.
Un coeficiente tetracórico con respecto a la tabla cuádruple anterior sería la unidad, suponiendo una distribución normal bivariada. Sin embargo, esta no es la
correlación entre los reactivos, pues no dice si podemos predecir un reactivo a partir del otro. La tetracórica expresa la correlación entre dos variables
cuantitativas de las cuales son funciones los reactivos, con tal que sean verdaderas las suposiciones de normalidad. La razón de que en este caso el
tetracórico sea la unidad es que las variables cuantitativas, de las cuales son funciones los reactivos, son una sola variable, a saber la variable escalar.
Adviértase, sin embargo, que la distribución de la variable escalar conforme al orden jerárquico de ninguna manera es normal. Una de las contribuciones de la
teoría de elaboración de escalas es que hace a un lado las hipótesis no probadas e innecesarias sobre distribuciones normales. Es la correlación de punto y no la
tetracórica la que interviene en el análisis matemático de la elaboración de escalas. Un rasgo importante de esta tabla cuádruple es la frecuencia de cero, en la
celdilla de la esquina superior derecha. Ninguno de los que contestaron correctamente la tercera pregunta falló en la segunda. Esta celdilla cero debe
presentarse siempre en una tabla cuádruple de dos reactivos dicotómicos, los cuales son funciones sencillas de la misma variable cuantitativa.
Otro ejemplo de escala Demos ahora un ejemplo de escala más complicada. Supongamos que tenemos interés
por saber en qué grado desean los soldados regresar a la escuela cuando la guerra termine. Supongamos que, del universo de atributos que definen este
deseo, seleccionamos la siguiente muestra de cuatro preguntas para formar con ellas un cuestionario.
1. Si le ofrecieran un buen empleo, żqué haría usted? a) Aceptaría el empleo b) Lo rehusaría si el gobierno me ayudara para poder ir a la escuela
c) Lo rehusaría y regresaría a la escuela sin más. 2. Si le ofrecieran algún empleo improductivo, żqué haría usted?
a) Lo aceptaría b) Lo rechazaría si el gobierno me brindara ayuda para ir a la escuela c) Lo rehusaría y regresaría a la escuela sin más.
3. Si no pudiera conseguir ningún empleo, żqué haría usted? a) No regresaría a la escuela b) Si el gobierno me brindara ayuda, regresaría a la escuela
c) Regresaría a la escuela aún sin ayuda del gobierno. 4. Si usted pudiera hacer lo que quisiera al terminar la guerra, żregresaría a
la escuela? a) S i b) No Supongamos que las respuestas de los sujetos a estas preguntas toman la forma de
una escala como la indicada en la figura 5.
Figura 5. Ya sabemos cómo leer esa gráfica. El 10% de los hombres dijeron que rehusarían un buen trabajo para regresar a la escuela; el 20% declaró que rehusarían un
buen trabajo solamente si recibieran ayuda gubernamental; el 70% manifestó que aceptaría un buen trabajo; y así sucesivamente. El 10% que dijo que rehusaría un
buen trabajo está incluido en el 20% que afirmó que declinaría algún trabajo, y este 20% está incluido en el 25% que manifestó que regresarían a la escuela si
no consiguieran ningún trabajo; y este 25% está contenido en el 50% que declaró que le gustaría regresar a la escuela.
Con respecto a tres preguntas tricotómicas y una dicotómica hay 3 X 3 X 3 X 2 = 54 tipos posibles. Para que formen una escala -puede demostrarse- a lo más deben
presentarse ocho tipos. La gráfica presenta los ocho tipos, que se han calificado de 0 a 7. La carta indica las características de cada tipo. Por
ejemplo, el tipo con la puntuación 3 incluye a todos los individuos con los siguientes cuatro valores: dicen que preferirían aceptar un buen trabajo que
regresar a la escuela; que rehusarían algún trabajo si el gobierno los ayudara para regresar a la escuela; que regresarían a la escuela si el gobierno los
ayudara en caso de que no pudieran conseguir ningún trabajo; y que les gustaría regresar a la escuela. Por tanto, leyendo las categorías cruzadas por las líneas
interrumpidas que encierran a cada tipo, podemos leer sus características. Nótese que cada uno de los cuatro atributos es una función sencilla de las
puntuaciones escalares. Por ejemplo, la pregunta de un "buen trabajo" tiene categorías que corresponden a los siguientes tres intervalos de puntuaciones
escalares: 0-3, 4-6, 7. Podría plantearse la pregunta de qué tan frecuentemente se encuentran escalas en
la práctica. żNo es demasiado esperar que se encuentre en la vida real una estructura siquiera aproximada a la de la gráfica anterior? En respuesta a esto
solamente podemos citar hasta ahora la experiencia en la investigación dentro del ejército. Literalmente se han encontrado docenas de escalas
suficientemente perfectas en varias áreas de actitud, opinión y conocimiento. El ejemplo anterior, acerca del deseo de ir a la escuela, es una versión ficticia
de un conjunto de preguntas similares que han podido ser mensurables en el ejército. Muchas variedades de datos han resultado mensurables y muchas no. Los
datos factibles de medirse pudieron relacionarse después muy fácilmente con otras variables. Los que estaban en el caso contrario requirieron un análisis
más complejo para manejarlos adecuadamente. El muestreo del universo de atributos
Una propiedad importante de un universo mensurable por escala es que la ordenación de las personas, basada en una muestra de reactivos, es de suyo igual
a la basada en el universo. Si el universo es una escala, la adición de reactivos solamente dividiría cada tipo dado entre la muestra en tipos
diferenciados; pero no intercambiaría el orden de los tipos encontrados en la muestra. Por ejemplo, en la figura 5, el tipo 6 siempre tendría un orden
jerárquico más alto que el tipo 5. Las personas del tipo 6 pueden ordenarse, dentro de su tipo, en más subcategorías; las personas que pertenecen al tipo 5
también podrían ordenarse en más subcategorías; pero todas las del tipo 6 tendrían un orden jerárquico más alto que todas las del tipo 5. Esto puede verse
a la inversa, por ejemplo, suprimiendo una de las preguntas y haciendo notar que todo lo que sucede es reducir los tipos a un número más pequeńo, de manera que
dos tipos vecinos puedan hacerse indistinguibles; pero tipos cualesquiera que estén separados dos pasos conservarán el mismo orden entre sí
Por consiguiente, estamos seguros de que si una persona tiene un rango más alto que otra, en una muestra de reactivos, tendrá también un rango más alto en el
universo de reactivos. Esta es una propiedad importante, de las escalas, que consiste en que de una muestra de atributos podemos sacar inferencias sobre el
universo al qué pertenecen. Uno de los criterios para seleccionar una muestra de reactivos es escoger una
muestra con bastantes categorías para proporcionar la cantidad deseada de diferenciación entre los individuos. De esta manera, si deseamos que se
diferencien los individuos, por ejemplo, solamente en 10 grupos, deben escogerse reactivos que produzcan 10 tipos. Claro está que no consideramos los problemas
de confiabilidad en el aspecto de observaciones repetidas de los mismos atributos. Por conveniencia supondremos tácitamente perfecta la confiabilidad.
La forma de distribución de los rangos en una muestra de atributos dependerá, por supuesto, de la muestra. Una muestra de atributos puede dar una forma de
distribución, mientras que una segunda puede dar otra diferente. Esto carece de importancia, toda vez que nuestro principal interés se encuentra en la
ordenación de las personas, no en la frecuencia relativa de cada posición. Sería logico preguntarse cómo podemos saber que el universo forma una escala si
todo lo que conocemos es una muestra de él. En la actualidad parece totalmente claro que, en general, la probabilidad de encontrar por azar una muestra de
atributos que formen una escala con respecto a una muestra de individuos es ínfima, aunque haya solo tres reactivos dicotómicos en la muestra y
aproximadamente cien individuos. Desarrollar la teoría completa de probabilidad requeriría dos cosas: primero, la definición de un
proceso de muestreo para seleccionar reactivos; y, segundo, la definición de lo que significa que no existe una escala. La definición del proceso de muestreo es
difícil porque los reactivos, por lo común, se desarrollan en forma intuitiva. Establecer una hipótesis de nulidad, de que no existe una escala, conduce a
muchas formulaciones analíticas posibles porque pueden imponerse diferentes condiciones limitantes a la distribución multivariada de los reactivos. Por
ejemplo, żdeben considerarse fijas las frecuencias marginales en todas las
muestras? żDeben considerarse fijas las frecuencias bivariadas? , etc. Estas preguntas pueden esclarecerse a medida que se desarrolle la teoría de
elaboración de escalas y mejoren nuestros conceptos de lo que implica la observación de los fenómenos sociales.
Parece seguro generalizar que, si se selecciona una muestra de atributos sin conocimiento de sus interrelaciones empíricas y se encuentra que forma una
escala en cualquier muestra aleatoria de individuos de tamańo comparativamente grande, entonces el universo del cual se seleccionan los atributos es mensurable
en toda la amplitud de la población entera de individuos. Elaboración de escalas y predicción
Es importante distinguir entre dos asuntos estrechamente relacionados, la elaboración de escalas y la predicción. Descubrir que se puede hacer una escala
para un universo de atributos y aplicarla a una población significa que es posible derivar una variable cuantitativa, partiendo de una distribución
multivariada tal que cada atributo sea una función sencilla de esa variable. Podríamos expresar esto de otra manera, diciendo que cada atributo es predecible
(perfectamente) a partir de la variable cuantitativa. Es esto lo contrario del problema ordinario de la predicción. En un problema
ordinario de esta especie, existe una variable externa, definida independientemente, que va a predecirse o partir de los atributos. Por ejemplo,
cuando se quieren predecir los ingresos de un estudiante, cinco ańos después que se graduó en la universidad, a partir de su conocimiento actual de matemáticas.
Para hacerlo, habría que obtener una muestra experimental en la que se conocieran los salarios de cada persona cinco ańos después de la universidad y
las respuestas a cada reactivo de la prueba de matemáticas. Si se adopta el criterio de mínimos cuadrados, entonces la mejor predicción con base en la
muestra sería la regresión múltiple del ingreso sobre los tres reactivos de la muestra. La distribución multivariada de los tres reactivos y la variable
externa nos darían los elementos necesarios para computar la regresión, curva o lineal, que sería la mejor para predecir la variable externa. Si deseáramos
predecir alguna otra variable externa a partir de los mismos reactivos, tendría que obtenerse una nueva regresión múltiple a partir de la distribución
multivariada de los tres reactivos de la nueva variable externa. En general y ordinariamente, se esperaría que la primera de estas regresiones diferiría de la
segunda. En absoluto, los pesos que se usan para predecir una variable externa fundándose en un conjunto de atributos difieren de los que se usan para predecir
otra variable externa; debe efectuarse una nueva regresión múltiple para cada variable externa. Esto subraya una propiedad importante de las escalas. Si los reactivos tienen
una distribución multivariada, que sea mensurable por escala, puede verse fácilmente que no importa cuál sea la variable externa; y es posible dar a los
reactivos los mismos pesos de predicción. Por tanto, nos hallamos frente a una propiedad notable de la medición por escala, a saber, que proporciona una
cuantificación invariante de los atributos con respecto a la predicción de cualquier variable externa. No importa a qué propósito de predicción vayan a
servir los atributos, las puntuaciones escalares servirán a dicho propósito. Acerca del "análisis de reactivos"
Es muy importante la distinción que acabamos de hacer. Al elaborar una escala, reproducimos los atributos partiendo de una variable cuantitativa. En la
predicción, pronosticamos una variable a partir de los atributos. Es una diferencia clara que nos permite evitar gran parte de la confusión que parece
prevalecer en la literatura anterior sobre la elaboración de escalas. Parece haberse creído que los reactivos de un universo son solamente escalones para
obtener puntuaciones. Se pensaba que era una deficiencia embarazosa carecer de una variable particular para predecir a partir de los reactivos, de modo que,
como mal necesario, uno tenía que recurrir a los métodos de consistencia interna para derivar las puntuaciones.
Esto explica los enfoques corrientes de "análisis de reactivos" en el proceso de elaborar escalas. Se siguen procedimientos que consisten generalmente en lo que
sigue: se asigna un conjunto de valores de prueba a las categorías, lo cual da lugar a un conjunto de puntuaciones de ensayo. Posteriormente se examina cada
reactivo para determinar qué tan bien puede discriminar por sí sólo estas puntuaciones, es decir, si pueden predecirse las puntuaciones a partir del
reactivo. Los reactivos que mejor discriminan individualmente se conservan y los demás se eliminan.
El carácter confuso de estos procedimientos puede verse en los ejemplos de escalas anteriores. Hemos seńalado que las intercorrelaciones
entre atributos de una escala pueden estar tan cerca de cero como uno desee. También puede verse cómodamente que la razón de correlación de las puntuaciones
de la escala con cualquier reactivo aislado puede estar igualmente tan cerca de cero como uno quiera. La predictibilidad de la variable escalar con fundamento
en un atributo no dice si el atributo es o no predecible a partir de la variable escalar. El uso de los procedimientos de "análisis de reactivos" en conexión con las
escalas parece una carga lamentable en el problema de la predicción ordinaria de una variable externa. En tal problema, los reactivos no son ciertamente sino
escalones que permiten hacer predicciones. Se sabe' ' que el análisis de reactivos ofrece una primera aproximación a la correlación múltiple (o a la
función discriminante) y que un reactivo interesa solamente en el grado que sirve a la regresión múltiple.
Nuestra insistencia en la medición por escala es muy diferente. En ésta, nos interesamos en cada uno de los atributos del universo por los propios méritos de
estos. Si no fuera así, no trabajaríamos con tal universo. Los atributos son las cosas importantes; y si son mensurables por escala, entonces las puntuaciones
serán solamente una estructura compacta para representarlos. La estructura compacta que hemos descrito tiene la propiedad adicional e
importante de ser un dispositivo eficaz para predecir cualquier variable externa de la mejor manera posible a partir de determinado universo de atributos.
La relatividad de las escalas Un problema interesante asociado con las escalas es el de żpor qué un universo
forma una escala con respecto a determinada población? Por ejemplo, tomemos la muestra de tres preguntas de matemáticas dada anteriormente. żPor qué pueden
incluirse en una escala estas tres preguntas? No hay una razón lógica necesaria para que una persona deba conocer el área de un círculo antes de que conozca lo
que es una derivada y, en particular, la derivada de ex. La razón para la existencia de una escala, en este caso, en gran parte parece cultural. Nuestro
sistema educativo es de tal tipo que la sucesión en que aprendemos nuestras matemáticas en las preparatorias y universidades es que primero aprendemos cosas
como el área del círculo, después el álgebra y posteriormente el cálculo. Y la cantidad de práctica que poseemos de cada una de estas materias probablemente
también está en ese orden. Sin embargo, sería muy posible para un marciano llegar a este mundo y estudiar cálculo sin tener que aprender el área de un
círculo de modo que no podría ser un tipo escalar, conforme a la escala presentada arriba; o un estudiante podría haber tenido un incidente personal en
el cuál, de alguna manera, lo haya impresionado con gran fuerza la derivada de ex; pero en el curso ordinario de las circunstancias la habría olvidado más
rápidamente de lo que olvidó el área de un círculo. El análisis escalar separará esos tipos desviados o no escalares. Naturalmente
que, si estos tipos no escalares son demasiado numerosos, diremos que no existe una escala. En la práctica encontramos escalas, aunque nunca escalas perfectas,
porque ha habido suficiente uniformidad de experiencia en la población de individuos, de manera que los atributos significan esencialmente lo mismo a los
diferentes individuos. De hecho, un estudio de las desviaciones es un subproducto interesante del análisis escalar. El análisis escalar separa
efectivamente a los individuos para hacer estudios de casos. Un universo puede formar una escala en una población, en un momento dado, pero
no hacerlo en otra ocasión. Por ejemplo, los reactivos de la escala de expresión del deseo de los soldados norteamericanos de regresar a la escuela después de la
guerra, posiblemente no resultaran susceptibles de conformarse a una escala si se les preguntara una segunda vez al terminar la guerra.
Un universo puede formar una escala en una población de individuos, pero no en otra. O los atributos pueden formar escalas, en dos poblaciones, de manera
diferente. Por ejemplo, una muestra de reactivos de satisfacción con respecto a la vida en el ejército, que formó una escala con relación a los pertrechos de
combate en la Fuerza Aérea, no formó una escala en los individuos de las escuelas técnicas de la misma rama. La estructura de la vida militar de estos
dos grupos fue muy diferente en los mismos reactivos, y no tuvo por eso el mismo significado en ambas situaciones.
Si un universo es mensurable por escala, en una población, pero no en otra, o forma una escala de manera diferente, no podemos comparar las dos poblaciones en
cuanto a grado, y decir que una es más alta o más baja en promedio con respecto al universo. Difieren en más de una dimensión o en clase, más que en grado.
Solamente si dos grupos o dos individuos caen en la misma escala podemos ordenarlos de mayor a menor. Una consideración similar es válida para las
comparaciones de tiempo. Una contribución importante de la teoría presente relativa a la elaboración de escalas es subrayar estas propiedades de
relatividad. Resumen 1. La distribución de frecuencia multivariada de un universo de atributos con
respecto a una población de objetos es una escala cuando es posible derivar de la distribución una variable cuantitativa que caracterice a los objetos, de tal
manera que cada atributo sea una función sencilla de la variable cuantitativa. 2. Tiene un significado inequívoco el orden de las puntuaciones escalares. Un
objeto con una puntuación más alta que otro se caracteriza por valores más altos de cada atributo, o por lo menos equivalentes.
3. Tiene un significado inequívoco el orden de los valores del atributo. Una categoría de un atributo es más alta que otra si caracteriza a los objetos en
posiciones más altas en la escala. 4. Puede demostrarse que si los datos son susceptibles de conformarse a una
escala, la ordenación de los objetos y de las categorías es, en general, única (excepto por la dirección). Las dos ordenaciones surgen del análisis de los
datos y no de consideraciones a priori. 5. La predictibilidad de cualquier variable externa a partir de las puntuaciones
escalares es igual a la predictibilidad a partir de la distribución multivariada usando los atributos. La correlación de orden cero con la puntuación escalar es
equivalente a la correlación múltiple con el universo. Por consiguiente, las puntuaciones escalares proporcionan una cuantificación invariante de los
atributos para predecir cualquier variable externa. 6. Las escalas son relativas con respecto al tiempo y a la población. 7. En la distribución multivariada de una muestra de atributos con respecto a una muestra de objetos, se pueden hacer inferencias concernientes a la
distribución completa del universo con respecto a la población. 8. Las escalas perfectas no se encuentran en la práctica. 9. En las escalas imperfectas, el análisis escalar separa los tipos desviados o
no escalares para estudio de casos. Artículo Abril 2008 BASE PARA ELABORAR ESCALAS CON DATOS CUALITATIVOS
INTRODUCCIÓN En gran parte de la investigación que se realiza en el campo
de las ciencias sociales y psicológicas, el interés se centra en ciertas clases importantes de observaciones cualitativas. Por ejemplo, la investigación sobre
el matrimonio atiende a una clase de conducta cualitativa llamada adaptación matrimonial, que incluye un número indefinidamente grande de interacciones entre
marido y mujer. La investigación de la opinión pública se ocupa de importantes clases de conducta que son expresiones de la opinión de los norteamericanos
sobre asuntos como la capacidad de lucha de los británicos, por ejemplo. La psicología educativa incluye los tests de aprovechamiento en dichas clases de
conducta. A menudo, en estos campos se desea, resumir los datos diciendo, por ejemplo, que
una pareja matrimonial está mejor ajustada que otra; que esta persona tiene mejor opinión de los británicos que aquélla; o que un estudiante tiene mejor
conocimiento de la aritmética que otro. Se ha discutido ampliamente la utilidad de estas ordenaciones de personas; pero no es nuestra intención pasar revista a
esas discusiones, sino enfocar el problema sobre una base nueva que parece la adecuada para cuantificar datos cualitativos.
Este enfoque se usó satisfactoriamente en la investigación de la moral y otros problemas, que llevó a cabo la sección de investigación de la División de
Servicios de Moral del Ejército de los Estados Unidos, dentro del propio campo de las fuerzas armadas. Aunque este enfoque de la cuantificación conduce a
ciertos cálculos interesantes, no se requieren conocimientos matemáticos especiales para analizar los datos con toda eficacia. Se han establecido rutinas
sencillas que no requieren conocimientos de estadística y que llevan menos tiempo que las diversas manipulaciones empleadas actualmente por diferentes
investigadores (por ejemplo razones críticas, correlaciones biseriales, análisis factorial, etc.), las cuales proporcionan un cuadro completo de los datos, que
por cierto no es ofrecido por esas otras técnicas. La palabra "cuadro" puede interpretarse aquí literalmente, porque los resultados del análisis se presentan
y se asimilan fácilmente en la forma de un "escalograma", que ofrece a primera
vista la configuración de los datos cualitativos. Las nociones de variable, función y función sencilla
Veamos en primer
lugar algo sobre el significado de variable, ya sea
cualitativa o cuantitativa. Usamos el término en su acepción convencional,
lógica o matemática, para denotar un conjunto de valores. Estos valores pueden
ser numéricos (cuantitativos) o no numéricos (cualitativos). Usaremos en forma
intercambiable los términos "atributo" y "variable cualitativa". Los valores de
un atributo (o de una variable cuantitativa, que para el caso es lo mismo) son
sus subcategorías o simplemente categorías.
Un ejemplo de atributo es la religión. Una persona puede tener el valor
"católico", "budista", "judío", "mormón", "ateo", o algún otro valor de esta
variable. No hay un orden intrínseco particular en estos valores. Otro ejemplo
es la expresión de una opinión. Una persona puede decir, "Me gustan los
ingleses", "No me gustan los ingleses", o "No sé si me gustan o no los
ingleses". Una ilustración más consiste en que se puede observar que una persona
sonríe al conocer a otra, o que no lo haga.
Las variables cuantitativas se reconocen fácilmente.
Se dice que una variable y es función de un sólo valor de la variable x si a
cada valor de x corresponde un sólo valor de y. Por tanto, si y toma los
distintos valores Y1, Y2, ... , Ym, y si X toma los diferentes valores
X1, X2, . . . , Xn, donde m y n pueden ser diferentes,
decimos que Y es una función monovalente de X, y en tal caso podrá hacerse una
tabla de correspondencia semejante a la que sigue:
_____________________________________
x x1 x2 x3... xnn
_____________________________________
y y1 y2 y3... ym
_____________________________________
Para cada valor de X hay un valor de Y y solamente uno. (Lo contrario no
necesita ser cierto: para un valor de Y puede haber dos o más valores de
X).
Obviamente, si Y es una función monovalente de X, se deduce que m
≤ n.
En particular, supongamos que Y es un atributo, por ejemplo el atributo anterior
sobre la expresión de simpatía por los ingleses. Si m = 3, y podemos expresar con
Y1 la afirmación "Me gustan los ingleses"; con
Y2, la afirmación, "No me gustan
los ingleses"; y por Y3 "No sé si me gustan o no los ingleses"; y si
X es una
variable cuantitativa que toma más de m valores (n > m), y si podemos dividir
los valores de X en m intervalos que se hallen en correspondencia de uno a uno
con los valores de Y, entonces decimos que el atributo Y es una función sencilla
de X . Por ejemplo, supongamos que X toma los diez valores 0, 1, 2, 3, 4, 5, 6,
7, 8, 9; la tabla de correspondencia sería entonces como la siguiente:
_____________________________________
X 0 1 2 3 4 5 6 7 8 9
_____________________________________
Y Y1 Y1 Y1 Y3 Y3 Y2 Y2 Y2 Y2 Y2
_____________________________________
Asimismo, podríamos representar esto gráficamente dibujando los valores de X en
una línea recta que dividiríamos en intervalos: Para variables estadísticas es
posible otra representación, consistente en un gráfico de barras de frecuencia La definición de escala
Con respecto a determinada población de objetos, la distribución de frecuencia
multivariada de un universo de atributos se llamará escala, si es posible
derivar de la distribución, una variable cuantitativa para caracterizar los
objetos de modo que cada atributo sea una función sencilla de esa variable
cuantitativa. Esa variable cuantitativa es la variable escalar.
No esperamos obtener en la práctica escalas perfectas. La
desviación de
la perfección se mide por el coeficiente de reproductibilidad, que sencillamente
es la frecuencia empírica relativa con que los valores del atributo corresponden
a los intervalos adecuados de una variable cuantitativa. En la práctica, se
han empleado escalas con un 85% de perfección o aun mejores como aproximaciones
eficientes a escalas perfectas. Un valor de una variable escalar se llamará una puntuación
escalar o simplemente puntuación. La ordenación de los objetos de acuerdo con el
orden numérico de sus puntuaciones escalares se llamará su orden escalar.
Obviamente, cualquier variable cuantitativa, que es una
función creciente (o decreciente) de una variable escalar, también es una
variable escalar. Por ejemplo, anteriormente se consideró a X como una
variable escalar. A cada una de las puntuaciones de X podría restársele o
agregársele una constante cualquiera, Y y seguiría siendo una función
sencilla de la X transformada. Así, las puntuaciones 0, 1, 2, 3, 4,
5, 6, 7, 8, 9 podrían reemplazarse por las puntuaciones respectivas -5, -4, -3,
-2, -1, 0, 1, 2, 3 y 4. o podrían multiplicarse las puntuaciones de X por
cualquier constante, o extraerse sus raíces cuadradas o tomarse sus logaritmos;
puede, en fin, hacerse cualquier transformación continua o discontinua en tanto
que permanezca perfecta la correlación de orden jerárquico entre la X original y
la variable transformada. Todas esas transformaciones producen variables
escalares, cada una de las cuales es igualmente eficaz para reproducir los
atributos. Por consiguiente, el problema de la métrica no es aquí de
importancia particular para elaborar escalas. En ciertos problemas, como
predecir variables externas a partir del universo de atributos, puede ser
conveniente adoptar una métrica particular, por ejemplo, la de cuadrados
mínimos, cuyas propiedades resultan convenientes para ayudar a analizar
correlaciones múltiples. Sin embargo, debe seńalarse que la selección de la
métrica es asunto de conveniencia; cualquier métrica predecirá una variable
exterior tan exactamente como lo haría cualquier otra. En la práctica, se ha usado el orden jerárquico como variable
escalar. (De hecho, es una métrica de cuadrados mínimos, aplicable a una
distribución rectangular de puntuaciones escalares). El universo de atributos Las palabras población y universo se usan por lo común en
forma intercambiable en los estudios estadísticos. En cuanto a las escalas es
necesario referirse tanto a un conjunto completo de objetos como a un conjunto
completo de atributos; así que será conveniente reservar población para lo
primero y universo para lo segundo. En la investigación social, los objetos son
por lo común personas, de manera que para ellos es apropiado usar población. Un concepto básico en la teoría de las escalas es el de
universo de atributos. En la investigación social, un universo es generalmente
una clase importante de conducta como la descrita en la introducción. El
universo es el concepto cuya factibilidad de medirse por escala se investiga,
como el ajuste matrimonial, la opinión sobre la capacidad de lucha de los
británicos, el conocimiento de la aritmética, etc. El universo consiste en todos
los atributos que define el concepto. Otra manera de describir el universo es
expresando que comprende todos los atributos de interés para la investigación y
qué tienen un contenido común, de manera que se clasifican bajo un sólo título
que indica el contenido. Por ser de fácil examen, tomemos un ejemplo de la
investigación de opinión, donde se desea observar la población de individuos de
manera estandarizada par medio de una lista de confrontación de preguntas. La
conducta que interesa en la investigación son las respuestas de los individuos a
tales preguntas. Supongamos que el universo de atributos abarca todas las
preguntas posibles que podrían contestarse en la lista concerniente a la
capacidad de lucha de los británicos. Esas preguntas podrían ser: "żPiensa usted
que el ejército británico es tan poderoso como el alemán? "; "żPiensa usted que
la fuerza aérea británica es superior a la alemana? " Y así sucesivamente. Hay
un número indefinidamente grande de tales preguntas que pertenecen al universo;
pero en una investigación particular generalmente sólo se usa una muestra de
aquél. Un atributo pertenece al universo en virtud de su contenido.
El investigador indica el contenido de interés por el título que selecciona para
el universo; y todos los atributos con ese contenido pertenecen a tal universo.
Por de contado, habrá en la práctica casos límites en que será difícil decidir
si un reactivo pertenece o no al universo. La evaluación del contenido es así un
asunto que puede decidirse por consenso de los peritos o por algún otro medio.
Esto se ha reconocido antes, aunque no necesita considerarse como un pecado
contra el Espíritu Santo del operacionalismo puro ". Es posible que el análisis
formal de factibilidad de una escala ayude a esclarecer las regiones dudosas de
contenido. Sin embargo, se ha encontrado que actualmente es más útil valerse de
la experiencia informal y del consenso, en su mayor grado, para definir el
universo. Un aspecto importante de este enfoque es que el criterio para
que un atributo pertenezca al universo no es la magnitud de las correlaciones de
ese reactivo con otros atributos que se sabe pertenecen al universo. Los
atributos del mismo tipo de contenido pueden tener intercorrelaciones de
cualquier amplitud y que varían, prácticamente, desde 0 hasta la unidad. La población de objetos Definir el universo de atributos es un problema similar al
problema típico de definir la población de objetos o individuos de interés para
la investigación. Un investigador debe siempre delimitar la población con la que
trabaje. Por ejemplo, en el caso de la opinión sobre los británicos como
soldados, debe decidir de quiénes desea determinar las opiniones, żEstá
interesado en individuos de cualquier parte o solo de los de los Estados Unidos?
żEstá interesado en cualquier individuo de los Estados Unidos o solo en los
adultos? Si sólo en los adultos, żcómo se definirá un adulto? Además, a veces
será difícil decidir si un individuo particular pertenece a una población o no;
y las decisiones deberán tomarse antes de que empiece la investigación, pues de
otra manera el investigador no sabrá a quién observar. Métodos de observación Supongamos que hemos definido un universo de atributos y una
población. Podemos entonces comenzar a realizar observaciones sobre la conducta
de la población con respecto al universo. (En la práctica esto se hace
generalmente sólo con muestras. Una muestra de individuos de la población es
observada en su conducta con respecto a una muestra de atributos del universo).
Cómo se hagan las observaciones, aquí no interesa. En la investigación de
opinión y en otros campos se han usado cuestionarios e inventarios. Pero puede
usarse cualquier técnica de observación que proporcione los datos de interés
para la investigación. En el caso de las ciencias sociales y psicológicas, las
técnicas pueden ser historias de casos, entrevistas, introspección y cualquier
otra técnica para registrar observaciones. Lo importante no es cómo se alleguen
las observaciones, sino que éstas sean de interés central para la investigación. El uso de un cuestionario implica que el investigador está
interesado en cierto tipo de universo de conducta verbal. La observación
participante puede implicar que el investigador se interesa por cierto tipo de
universo de conducta no verbal. Estos distintos universos pueden investigarse en
forma individual. Con frecuencia es de interés averiguar qué tan bien se
correlaciona un universo con otro; pero esa correlación no puede determinarse
sino hasta que cada universo se defina y observe separadamente. Los ejemplos de escalas de este artículo contienen
observaciones hechas por medio de cuestionarios. No debe inferirse, sin embargo,
que la elaboración de escalas se refiere solamente a esa técnica. El análisis de
la elaboración de escalas es un análisis formal y, por tanto, se aplica a
cualquier universo de datos cualitativos de cualquier ciencia obtenidos por
cualquier forma de observación.
El propósito de la elaboración de escalas Es patente la laboriosidad que implica el registro del gran
número de observaciones que existen en un universo de atributos con respecto a
una población de individuos. El registro requiere una tabla con un renglón para
cada individuo y una columna para cada atributo. (En teoría, la tabla puede ser
indefinidamente grande). Sería conveniente que pudiésemos representar las
observaciones del modo más compacto que, a su vez, nos permitiera reproducir la
tabla siempre que lo deseáramos. Una representación compacta, si pudiera
obtenerse, tendría dos grandes ventajas: primero, una ventaja mnemotécnica,
porque una representación de tal tipo sería más fácil de recordar que una tabla
grande; y segundo, si deseáramos relacionar el universo y otras variables sería
más fácil hacerlo por medio de la representación compacta que usando la
distribución multivariada de los atributos en el universo. De ella se derivan
otras ventajas que se advertirán cuando aumente el conocimiento del lector sobre
las escalas. Una representación particularmente sencilla de los datos
sería asignar a cada individuo un valor numérico y a cada categoría de cada
atributo otro valor numérico, de manera que, dado el valor del individuo y los
valores de las categorías de un atributo, pudiéramos reproducir las
observaciones del individuo sobre el atributo. Esto será posible solamente en
tipos restringidos de datos, en que cada atributo del universo puede expresarse
como una función sencilla de la misma variable cuantitativa, es decir, donde el
universo de atributos forma una escala con respecto a la población de
individuos. Un ejemplo de escala dicotómica Como era de esperarse, el universo de atributos debe formar
una configuración especializada con respecto a la población de individuos para
que sea mensurable por escala. Antes de describir un caso más general, demos un
pequeńo ejemplo. Considérese una prueba de matemáticas compuesta de los
siguientes problemas: a.- Si r es el radio de un círculo, żcuál es su área? b.- żCuáles son los valores de X que satisfacen la ecuación ax2 + bx + c = 0?
c.- żCuál es la dex/dx
Si esta prueba se aplicara a la población de miembros de la Sociedad
Norteamericana de Sociología, quizá encontraríamos que forma una escala en esa
población. Las respuestas a cada una de estas preguntas pueden presentarse como
una dicotomía, correcta o incorrecta. Hay 2 x 2 x 2 = 8 tipos posibles para tres
dicotomías. Realmente, en esta población de sociólogos probablemente
encontraríamos cuatro de los posibles tipos. Existiría el tipo que contestó
correctamente las tres preguntas, el tipo que contestó correctamente la primera
pregunta y la segunda, el que solamente contestó correctamente la primera y el
que no contestó correctamente ninguna de las preguntas. Supongamos que esto es
lo que realmente hubiese sucedido. Es decir, supondremos que no sucederían los
otros cuatro tipos, como el tipo que contesta correctamente la primera y la
tercera pregunta, pero que se equivoca en la segunda. En este caso, es posible
asignar a la población un conjunto de valores numéricos como 3, 2, 1, 0. A cada
miembro de la población se le asignará uno de estos valores. Este valor numérico
se denominará la puntuación de la persona. A partir de esa puntuación, sabríamos
entonces precisamente cuáles son los problemas cuyas respuestas conoce y cuáles
son las que desconoce. Así, una puntuación de 2 no significaría solamente que la
persona contestó correctamente dos preguntas, sino que contestó correctamente
dos preguntas determinadas, a saber, la primera y la segunda. La conducta de una
persona en estos problemas es reproductible a partir de su puntuación.
Específicamente, cada pregunta es una función sencilla de la puntuación.
El significado de "más" y "menos"
Adviértase que tiene un significado muy definido decir que una persona sabe más
matemáticas que otra con respecto a esta muestra. Por ejemplo, una puntuación 3
significa más que una puntuación 2, porque la persona con una de 3 sabe lo que
una persona con una puntuación 2 y algo más.
También tiene un significado definido decir que contestar correctamente una
pregunta indica mayor conocimiento que contestarla erróneamente; la importancia
de esto posiblemente sea demasiado obvia. Las personas que contestan
correctamente una pregunta tienen, todas, puntuaciones escalares más altas que
las personas que contestan erróneamente. En realidad, no necesitamos conocer de
antemano cuál es la respuesta correcta y cuál la errónea para establecer un
orden adecuado entre los individuos. Por conveniencia, supongamos que se dio a
las preguntas la forma de "verdadero-falso, (suponemos que nadie da una
respuesta correcta por adivinación; mas adelante se mostrará cómo el análisis
escalar puede separar efectivamente las respuestas correctas dadas por
adivinación), con respuestas indicadas 2II r, (- b ± √b2-
4ac )/ 2a, y xex-1 para las preguntas respectivas. Cada persona pone una V o una F
después de cada pregunta, según crea que las respuestas propuestas sean
verdaderas o falsas. Si las respuestas de la población forman una escala, no
tenemos por qué saber cuáles son las respuestas correctas para ordenar
jerárquicamente a los sujetos (solamente que no sabremos si los hemos ordenado
de mayor a menor o de menor a mayor). Mediante el análisis escalar, que
esencialmente se basa en clasificar las combinaciones que se presentan de los
tres reactivos simultáneamente, encontraríamos solamente 4 tipos de personas.
Un tipo sería F1 V2 F3, donde los subíndices indican las preguntas; es decir,
este tipo dice F a la pregunta 1, V a la pregunta 2 y F a la pregunta 3. Los
otros 3 tipos serían F1 V2V3, F1 F2V3 y V1 F2 V3 . Podrían representarse estos
tipos en una gráfica (un "escalograma"), en la que hay un renglón para cada
tipo de persona y una columna para cada categoría de cada atributo. Sin entrar
en detalles, el análisis escalar establecería un orden entre los renglones y las
columnas que presentaría este aspecto:
F3 T2 F1 T3 F2 T1
O, alternativamente, tanto los renglones como las columnas podrían estar
ordenados en s forma completamente invertida. Cada respuesta a una pregunta se
indica por una marca. ` Cada renglón tiene tres marcas porque cada pregunta se
contesta, ya sea correcta o incorrectamente. La estructura de "paralelogramo" de
la gráfica (Esta gráfica, donde se usa una columna para cada categoría de un
atributo, la llamamos escalograma. Las tablas de escalograma empleadas en los
procedimientos prácticos son sencillamente dispositivos para trasladar renglones
y columnas, a fin de encontrar un patrón escalar en caso de que exista.) es
necesaria y suficiente para que un conjunto de atributos dicotómicos sean
expresables como funciones senI cillas de una sola variable cuantitativa.
De esta gráfica podemos deducir que F1, V2 y F3, son todas respuestas correctas
o todas incorrectas. Es decir, si dijéramos que F1 es una respuesta correcta,
inmediatamente sabríamos que V2 y F3 también lo serían. Esto significa que
podemos ordenar a los individuos conforme a su conocimiento, aunque no sepamos
cuáles son las respuestas correctas y cuáles las incorrectas, solamente que no
sabremos si los hemos ordenado de mayor a menor, o viceversa. Excepto por la
dirección, la ordenación es una consecuencia puramente formal de la
configuración de la conducta de la población con respecto a los reactivos. La
importancia de este hecho se hace más evidente en los casos más complicados
donde los atributos no son dicotómicos sino que tienen más de dos categorías. No
tenemos espacio para extendernos sobre este punto, pero diremos, sencillamente,
que el análisis escalar decide automáticamente, por ejemplo, dónde debe ir
colocada una respuesta de "en duda" en una encuesta de opinión pública, si debe
ir por encima de "sí", debajo de "no", si entre éstas, si es equivalente a "si",
o es equivalente a "no".
COMPARACIONES EMPÍRICAS ENTRE LAS DISTINTAS TÉCNICAS PARA MEDIR ACTITUDES LA COMPARACION DE EYSENCK Y CROWN En 1949, Eysenck y Crown dieron a conocer algunos de sus hallazgos en la investigación que habían realizado durante los tres ańos
anteriores. Entre otros, la escala de actitud que elaboraron para medir el antisemitismo. Inicialmente, siguieron el procedimiento de Thurstone, reuniendo
150 reactivos de "comentarios escritos y hablados acerca de los judíos, de publicaciones periódicas, de estudiantes y de personas ajenas al medio
académico". A continuación, 80 personas, principalmente ajenas al medio citado, juzgaron los reactivos, colocándolos sobre un continuo de once puntos favorables
hacia los judíos. Después que la escala se aplicó a la manera de Thurstone a 200 estudiantes universitarios, se encontró que la confiabilidad de división a la
mitad era de .83 (corregida). Por
considerar insatisfactoria esta confiabilidad, Eysenck y Crown decidieron reaplicar la escala, solicitando respuestas del tipo
Likert a un segundo grupo de 200 estudiantes. La confiabilidad de división a la mitad fue de .90 (corregida). Por tanto, el procedimiento de calificación de
Likert mostró nuevamente una confiabilidad más alta que el de Thurstone. El procedimiento de Eysenck y Crown es algo diferente al procedimiento original de
Thurstone. Elaboraron solamente una escala y calcularon después una confiabilidad de división a la mitad, como se hace comúnmente con las escalas de
Likert. No elaboraron dos escalas de formas paralelas ni calcularon después una confiabilidad de formas paralelas.
Como seńalaron Eysenck y Crown, "esto no es estrictamente una
comparación entre las escalas de Thurstone y Likert... es una comparación entre los métodos de calificación de Thurstone y Likert de reactivos seleccionados
según el método de aquél" (1949). Como tal, es una réplica de una de las dos comparaciones hechas por Likert (1932) y de la comparación de Likert, Roulow y
Murphy (1934); sin embargo, el contenido (antisemitismo) no se tomó de los estudios precedentes. Eysenck y Crown también se ocuparon del problema de la validez. Sin embargo, es de poco interés aquí porque solamente se obtuvieron
impresiones subjetivas, es decir, se comparó el conocimiento previo de los entrevistadores acerca de las actitudes de los sujetos, con sus puntuaciones
escalares (dos medidas no totalmente independientes). No hicieron, además, ninguna comparación, ni siquiera subjetiva entre las evaluaciones de los
entrevistadores con respecto al antisemitismo de los sujetos y las puntuaciones de las escalas de Thurstone o Likert. LA COMPARACION DE BANTA En 1961, Banta publicó un resumen de la investigación que acababa de realizar. Gran parte de aquélla no está relacionada este tema; sin
embargo, planteó en ella una pregunta significativa: żen qué condiciones prácticas los diferentes métodos de calificación de escalas de actitud idénticas
no producen resultados semejantes?. La extensión de esta pregunta conduce a otra igualmente importante: żen qué condiciones las diferentes técnicas de
construcción de escalas de actitud no producen escalas que den resultados semejantes? Banta se "ocupó de medir actitudes sociales en las que se varió deliberadamente la ambigüedad del referente en el cuestionario de actitud"
(1961). Se ocupó de las variaciones en la ambigüedad de los referentes de las escalas de actitud, es decir, la escala se tomó como un todo. Pero no se ocupó
de las variaciones en la ambigüedad de los reactivos que forman la escala. Formuló la hipótesis de que cuanto más ambiguo fuese el referente con respecto a
la escala de actitud, tanto menos se correlacionarían los diferentes métodos de calificación de determinada escala de actitudes. Para probarla, Banta usó tres cuestionarios de 20 reactivos cada uno; el primero medía las actitudes hacia el presidente Eisenhower; el
segundo, hacia las fraternidades universitarias y el último, hacia las personas en general. Según Banta, la ambigüedad del referente de las tres escalas se
incrementa respectivamente. Los tres cuestionarios se aplicaron a tres grupos de estudiantes. Cada grupo completó cada cuestionario tres veces, siguiendo cada
vez diferentes instrucciones. Los procedimientos de calificación de Thurstone y Likert constituyeron dos de los tres grupos de instrucciones. Cada estudiante
completó por escrito los nueve cuestionarios. Posteriormente, en el análisis, se eliminaron los efectos de orden. Es importante seńalar que en todas las condiciones de ambigüedad del referente de la escala de actitud los métodos de Thurstone y de
Likert se correlacionaron altamente, aunque el patrón tendió a seguir las predicciones de Banta. En el orden de ambigüedad creciente, los métodos de
calificación se correlacionaron en un .89 (presidente Eisenhower .89 fraternidades universitarias) y .72 (las personas en general). Aunque estos
datos no ofrecen un fuerte apoyo a las hipótesis de Banta, no deben tomarse como representativos de sus resultados. Sería injusto juzgar las conclusiones de
Banta por lo que se presenta aquí ya que solamente se cubre una pequeńa porción de aquellos. Por lo que toca a la comparación de la calificación de Thurstone y
Likert, los resultados de Banta parecen no concluyentes. Pero, aunque los resultados hubieran sido más patentes, algunos de los procedimientos de Banta
siguen siendo dudosos; y sería difícil generalizar confiablemente sus resultados. Primero, reduce los posibles valores escalares de Thurstone, de 11 a 5. Dado que algunos autores han seńalado el poco número de pasos en la
calificación de Thurstone como la razón de que sea menos confiable que el método de Likert, parecería insensato reducir aún más los pasos. Segundo, Banta compara escalas que fueron elaboradas para adecuarse a diferentes técnicas de calificación. De las tres, una fue elaborada
para calificarse por el método de Thurstone, otra por el método de Likert y otra por un tercer método. Otros autores se han prevenido contra la calificación de
una escala de actitud con una técnica diferente a la empleada en su elaboración. Ferguson, por ejemplo, seńala que los reactivos seleccionados para las escalas
de Likert no suelen ser adecuados para la calificación de Thurstone, porque los reactivos de Likert, por lo común, no caen en las categorías neutrales de la
escala de Thurstone. Tercero, y más importante, Banta parece no darse cuenta de la
diferencia entre ambigüedad del referente de la escalo de actitud y de la ambigüedad del reactivo. Como no lo menciona, debemos suponer que no determinó
los valores Q (o alguna medida similar de ambigüedad de reactivo) de los reactivos en las tres escalas. Por consiguiente, no demuestra que lo que varía
es la ambigüedad del referente de la escala de actitud, sino la de los reactivos particulares de cada escala. Un diseńo de investigación más adecuado para
examinar la ambigüedad del referente de la escala de actitud, mientras se mantiene constante la ambigüedad del reactivo, consistiría en usar una sola
escala de, digamos, 20 reactivos, variándose el referente de la escala de actitud mientras se mantiene constante el resto del reactivo; "el presidente
Eisenhower es amistoso", se cambiaría a "la gente en general es amistosa", etc.
Por tanto, lo mismo la ambigüedad del reactivo que la ambigüedad del referente de la escala de actitud pudieron producir los resultados. En resumen, Banta ha planteado una cuestión pragmática importante, es decir, żcuándo no producen resultados similares los métodos de
Thurstone y Likert? El conocimiento científico suele avanzar solamente después que se han planteado interrogantes que vengan al caso. Por consiguiente, no
debemos quitarle importancia a esta pregunta; pero a partir de los datos presentados no parece haberse dado ninguna respuesta. LA COMPARACION DE BARCLAY Y WEAVER Desde la investigación de Edwards y Kenney (1946), no habían recibido consideración empírica dos cuestiones significativas. La primera se
refiere a la eficiencia relativa de los dos métodos, żCuál de ellos produciría una escala de actitud satisfactoria en la menor cantidad de tiempo?. La segunda
fue: żCuál produciría la escala de actitud más válida, determinada por la correlación entre la puntuación de la escala de actitud y los criterios externos
adecuados?. Barclay y Weaver (1962) se ocuparon de la primera de estas dos preguntas. Poppleton y Pilkington (1964) trataron la segunda. Los dos primeros compararon dos aspectos de los métodos de Thurstone y Likert. Ambas comparaciones tienen importancia potencial. Empezaron
comparando la confiabilidad de las escalas elaboradas por las técnicas de Thurstone y Likert a partir de una colección común de reactivos. Este fue el
primer estudio que utilizó tal clase de colección reunida especialmente con ese propósito. Dicho de otra manera, esta fue la primera comparación hecha con
escalas elaboradas por dos métodos, en la que los autores comenzaron desde el principio. Segundo, compararon la eficiencia relativa de los dos métodos. Como
lo expresaron Barclay y Weaver, "La cuestión de la eficiencia relativa de las dos técnicas nunca se ha resuelto por completo. El propósito de este estudio es
obtener mayor testimonio sobre el asunto", (1962). Para llevar a cabo estas dos comparaciones, reunieron una
colección de 250 aseveraciones sobre Hawai, las cuales provenían de turistas y visitantes militares de la isla. A partir de estos reactivos se elaboraron
cuatro escalas de actitud: "Se elaboraron dos usando la técnica original desarrollada por Thurstone y Chave (1929), y las otras dos usando la técnica
inventada por Likert (1932) y modificada por Edwards y Kenney (1946)". Para elaborar las dos escalas de Thurstone de formas paralelas, seleccionaron a 100 estudiantes del último ańo de preparatoria,
estudiantes graduados, instructores y profesores, que habrían de actuar como peritos. Estos siguieron los procedimientos generales de clasificación de las
aseveraciones. Posteriormente, se aplicaron las pruebas Q y los otros procedimientos indicados por Thurstone para la selección de reactivos. Más
tarde, se aplicaron las dos escalas de Thurstone a un solo grupo de 46 turistas. Para controlar la confusión de la muestra se aplicó la colección entera de
reactivos (un cuestionario de nueve páginas) al mismo grupo de sujetos. De esta manera, los turistas sirvieron como sujetos y peritos de Thurstone y como
sujetos de Likert. Además de los turistas, se aplicó el cuestionario a 29 estudiantes que actuaron como sujetos de Likert, pero que no contestaron el
cuestionario de Thurstone. Barclay y Weaver encontraron que el coeficiente de
confiabilidad de las escalas de Thurstone fue de .66 (no corregido). Con respecto al método de Likert, el coeficiente de confiabilidad fue de .97 (no
corregido). La probabilidad de obtener estos resultados por azar es apenas de .01, Para evaluar la eficiencia comparativa de los dos métodos, Barclay y Weaver
dedicaron un tiempo prudente a las diversas actividades requeridas en la elaboración de las escalas. El tiempo total de elaboración de las escalas de
Thurstone fue de 8.049 minutos. El método de Likert requirió 5.620 minutos, exceptuándose lo siguiente: "Debido a que se emplearon los mismos reactivos en
la construcción de ambas escalas, el tiempo empleado en reunirlos no se adjudicó a ningún método". Por tanto, "La diferencia de tiempo en favor de la técnica de
Likert es de 2.429 minutos (40 horas y 29 minutos) y representa el 43.2% del tiempo requerido por la técnica de Likert. Esto es, sin duda, una ventaja
considerable" . Barclay y Weaver concluyen: "Ninguno de los estudios
publicados anteriormente habían resuelto la cuestión de cuál método empleaba más tiempo, así que esta investigación se diseńó para dar una respuesta definida al
problema, que es lo que se ha hecho". Una conclusión más conservadora con respecto a sus hallazgos
concuerde quizá con el procedimiento adecuado. Primero, su procedimiento para comparar la eficiencia relativa de los dos métodos es técnicamente anticuada.
Seashore y Hevner (1933) y Jurgensen (1943) -entre otros- han indicado métodos para acelerar el proceso de elaboración de las escalas de Thurstone. Además,
parece poco necesario para las comparaciones futuras de eficiencia, que estén maniatadas por computaciones manuales. La determinación de los valores Q, los
valores escalares y otros cálculos pueden hacerse por medio de computadoras. Por medio de ellas y del uso de artefactos de lectura óptica -indicados por Webb
(1951) -el proceso manual de los datos es virtualmente anticuado. Varios errores técnicos disminuyen además el valor de su conclusión. Como se indicó anteriormente, no agregaron el tiempo empleado en
reunir la colección original de reactivos a ninguno de los métodos. En efecto, sustrajeron una constante del tiempo empleado en construir cada escala; y esto
tiene el efecto de inflar el porcentaje de la diferencia de tiempo entre los dos métodos. Para tomar un caso extremo, por ejemplo, 20 es el 200 por ciento de 10.
Si sustraemos 5 de cada número, encontramos que 15 es el 300 por ciento de 5. Su conclusión con respecto al número de peritos requerido no tiene en cuenta la investigación previa. Afirman que "la misma naturaleza de la
técnica de Thurstone requiere el uso de un número moderadamente grande de personas para que juzguen el conjunto entero de aseveraciones de actitud".
Edwards (1957), después de revisar las investigaciones de Nystrom (1933), Ferguson (1939), Rosander (1936), Uhrbrock (1934) y Edwards y Kenney (1946),
concluyó: "La evidencia apunta a la conclusión de que puede usarse un número relativamente pequeńo de peritos para obtener valores escalares confíables de
las aseveraciones al usar el método de intervalos aparentemente iguales". Finalmente, Barclay y Weaver seleccionaron un número desigual de personas para que actuaran como peritos de Thurstone y de Likert. Emplearon
100 personas como peritos de Thurstone y 75 como peritos de Likert. Del análisis de sus resultados, se desprende que esta desigualdad parece explicar
aproximadamente 700 minutos de los 2.429 de diferencia de tiempo. Por consiguiente, se debe concluir que la comparación de Barclay y Weaver,
concerniente a la eficacia relativa de los dos métodos, no es completamente satisfactoria. En vista de los adelantos recientes habidos en las técnicas de
procesar datos es dudosa la significación de las
comparaciones que usan el tiempo como criterio. LA COMPARACION DE POPPLETON-PILKINGTON La comparación más reciente entre los dos métodos la hicieron Poppleton y Pilkington (1964), quienes elaboraron dos formas paralelas de una
escala para medir actitudes religiosas usando el método de Thurstone para la recopilación de las aseveraciones. En un examen preliminar, se aplicaron
cuestionarios a 120 sujetos. Luego de un análisis de reactivos se obtuvieron dos escalas finales, cada una compuesta de 22 reactivos. Acto seguido, se aplicaron las dos escalas a dos grupos de 60 sujetos cada uno. A un grupo se le aplicó la forma A; y tres semanas después la
forma B. Al segundo grupo se le aplicó la forma B; y la forma A tres semanas después. A todos los sujetos se les pidió que respondieran cada uno de los 22
reactivos en una de las siguientes formas: "completamente de acuerdo", "de acuerdo", "en duda", "en desacuerdo", y "completamente en desacuerdo". El cuestionario se calificó por métodos diferentes: 1. "la calificación ordinaria de Thurstone de los reactivos que fueron apoyados"; 2.
"la calificación de Likert. Las categorías de respuesta se valuaron en la forma: 5-4-3-2-1; y los valores se invirtieron en el punto medio de la escala". Se
utilizaron otros dos métodos de calificación, que no se describen aquí. La comparación de confiabilidad de Poppleton y Pilkington se encuentra en la tabla 4. En términos generales, encontraron que el método de
Likert de calificación de una escala de actitud, elaborada por el método de Thurstone, era más confiable que el método de este último, pues los coeficientes
de confiabilidad fueron de .95 en contraste con .85 (no corregidos).
Para analizar la validez de las puntuaciones de sus escalas de actitud, seleccionaron cinco clases de conducta religiosa que sirvieran como
criterios comparativos de las puntuaciones de las escalas y obtuvieron medidas de informe de sí mismo sobre ellas. Las puntuaciones de actitud obtenidas por
los dos métodos se correlacionaron con las conductas religiosas informadas por sí mismo. La tabla 5 resume sus resultados. El método de Likert fue ligeramente más válido en cuatro de los cinco criterios, y con la misma validez el de Thurstone en un solo criterio.
En vista de que el propósito de su trabajo era evaluar la confiabilidad y la validez comparativa de los cuatro métodos de calificación, y ya que ninguno de
los métodos produjo consecuentemente la validez más alta o más baja, concluyeron que ninguno de los cuatro métodos demostró ser claramente superior a los demás.
De los datos de Poppleton y Pilkington se puede concluir que
los métodos de Thurstone y de Likert tienen aproximadamente igual validez y que su validez predictiva es
razonablemente alta. Sin embargo, con respecto a las comparaciones de validez es conveniente advertir que las escalas que se comparen deben tener coeficientes de
validez similares. La confiabilidad y validez no son independientes entre sí. (Bohrnstedt). Específicamente, puesto que la escala de Thurstone fue menos
confiable que la de Líkert, los autores no compararon en su totalidad la validez ,de los dos métodos en un nivel determinado de confiabilidadl'. Aunque la
crítica sea poco significativa, es algo difícil generalizar sus hallazgos porque su comparación está más o menos limitada a sus propios datos.
CONCLUSION Al comparar los métodos de Likert y Thurstone, aquél propuso inicialmente tres
hipótesis acerca de su método para elaborar escalas de actitudes contrastándolo con el método de Thurstone; que su método (el de Likert) era 1ş más rápido, 2ş
tan confiable o más y 3ş tan válido o más que el de Thurstone. Aunque ya hay algunas investigaciones sobre las tres hipótesis, la información empírica varía
tanto en calidad como en cantidad. Algunas preguntas pueden considerarse contestadas; otras, que han recibido poca atención empírica, todavía no pueden
considerarse resueltas; algunas más, aunque no contestadas, tampoco parecen suficientemente importantes para garantizar atención futura; y hay, finalmente,
preguntas aún en espera de ser formuladas. Quedan dos problemas que parecen estar ya resueltos empíricamente. Primero, el
método de Likert para la calificación de una escala de actitud con cualquier número de reactivos produce consistentemente resultados más confiables que el
método de calificación de Thurstone, (Likert, 1932; Likert, Roslow y Murphy, 1938; Ferguson, 1941). Testimonios adicionales demuestran que el método de
elaboración de la escala no altera la confiabilidad consecuentemente superior de la calificación de Likert. Por consiguiente, si la consideración principal en la
elaboración de una escala de actitud es una alta confiabilidad, el método de calificación de Likert es preferible al de Thurstone, ya sea que la escala se
haya construido por el método de uno u otro. Como lo indica la fórmula de Spearman-Brown, la confiabilidad está
relacionada con el número de reactivos de una escala de actitud. Por consiguiente, para producir escalas con gran semejanza en sus coeficientes de
confiabilidad se necesita ajustar solamente el número de reactivos a cada escala.
Segundo, se ha demostrado que si se elabora y califica una escala por el método de Likert, bastan ordinariamente 20 o 25 reactivos para producir una coeficiente
de confiabilidad de .90 o más, el cual, como regla empírica, se considera suficientemente alto: Sin embargo, una escala de 20 o 25 reactivos, elaborada y
calificada por el método de Thurstone, no es por lo común lo bastante larga para lograr un coeficiente de confiabilidad de .90. Para lograr este nivel de
confiabilidad (.90), una escala calificada por el método de Thurstone necesita contener aproximadamente 50 reactivos o itemes. Una cuestión que necesita mayor estudio es la cantidad de tiempo que requiere construir una escala de Thurstone o de Likert, especialmente si se recurre a la
tecnología de las computadoras. Aunque el tiempo de elaboración de la escala no es de importancia capital
cuando se va a decidir qué método usar, las estimaciones realistas del tiempo que toma la elaboración serían útiles para planificar los horarios de
investigación y para propósitos pedagógicos. Aunque muchos investigadores han indicado que el método de elaboración de Likert es más rápido que el de
Thurstone -Likert, Edwards y Kenney, y Barclay y Weaver- no conocen datos referentes a la cantidad real de tiempo que toma elaborar una escala de
Thurstone o de Likert. Usar la calificación de Likert en escalas obtenidas por la técnica de
Thurstone tiene la desventaja de mezclar modelos teóricos. Es mejor evitar este eclecticismo teórico. Sin embargo, para citar precedentes, otros autores -Eysenck
y Gpwn (1949) y Castle (1953)- han combinado estos modelos teóricos en investigaciones empíricas sobre escalas de mayor confiabilidad. Algunas consideraciones parecen justificar una especial atención al problema. Una de ellas es que la construcción de escalas por el método de Likert y su
calificación por el método de Thurstone, como lo hizo Ferguson, resultó insatisfactoria según lo mostró este autor. Otra es que la comparación del
tiempo de elaboración de una escala, usando el procedimiento original de Thurstone, como lo hicieron Barclay y Weaver, ha sido invalidada por las muchas
innovaciones de ahorro de tiempo, Edwards (1967), así como por el empleo de computadoras. Finalmente, quedan todavía por estudiarse determinadas materias. Por ejemplo, Fishbein (1967) indica que las técnicas de Thurstone y de Likert son
teóricamente diferentes y no susceptibles de esfuerzos combinados. Sin embargo, los datos indican que la calificación de Likert a las escalas de Thurstone
incrementa la confiabilidad de éstas. Que pueda o no darse un fundamento teórico a este procedimiento útil y pragmático queda aún por considerar. No ha habido
tampoco comparaciones empíricas de las confiabilidades de test-retest de las escalas de Thurstone y Likert; ni ha habido ninguna comparación empírica de la
validez de criterio de las escalas elaboradas con esas técnicas. Esto no significa que la confiabilidad de test-retest y la validez de criterio nunca se
hayan determinado para las escalas elaboradas por las técnicas de Thurstone y Likert. Sin embargo, no existen estudios en la bibliografía existente que
comparen la confiabilidad de test-retest o la validez de criterio de las dos técnicas. En conclusión, se puede seńalar que no se pueden comparar directamente los métodos de Thurstone y de Likert. Solamente se pueden comparar las escalas que
se han elaborado y calificado por un mismo método y las escalas elaboradas y calificadas por el otro. Por consiguiente, una comparación aislada de varias
escalas (o varias comparaciones de varias escalas) difícilmente se presta para generalizar sin restricciones. Para contestar las preguntas anteriores hacen
falta muchas comparaciones y muchos investigadores que las realicen, usando escalas para numerosos campos de la actitud.
BIBLIOGRAFIA Artículo Febrero 2008
COMPARACIONES EMPÍRICAS ENTRE LAS DISTINTAS TÉCNICAS PARA MEDIR ACTITUDES Tecnicas
de Thurstone y Likert Dos de los métodos mas importantes y permanentes para construir escalas de actitudes fueron desarrollados por Louis Thourstone y Rensis Likert. No obstante las innovaciones
recientes, como la escala de Guttman, sus métodos continúan usándose mucho y sigue la discusión sobre las ventajas de uno sobre otro. Analicemos algunos de los estudios tendientes a establecer directa y
empíricamente la validez, confiabilidad y eficiencia relativas de las técnicas de Thurstone y Likert en la construcción de escalas de actitudes.
El método de Thurstone tiene origen en los intentos de los psicofísicos de finales del siglo XIX y principios del XX que se proponían relacionar los
juicios psicológicos y los continuos físicos siguiendo el método de comparación por pares. La "ley del juicio comparativo", de Thurstone (1927), aportó el
fundamento para colocar los estímulos psicológicos sobre un continuo independiente de cualquier orden físico subyacente. Esto represento un avance
importante en el desarrollo de la medición psicológica dado que la base del continuo psicológico ya no estaba ligada directamente a sensaciones físicas.
Como resultado directo de estos primeros esfuerzos, Thurstone y Chave (1929) produjeron su obra clásica sobre la medición de actitudes, donde sugirieron una
opción mas breve y sencilla que el método de comparación por pares. Este método mas sencillo se conoce comúnmente como método de Thurstone o método de
intervalos aparentemente iguales. Por ejemplo, en la exploración de la relación entre los juicios psicológicos y
el continuo físico de peso, se pidio a un sujeto qua pusiera en orden jerárquico a diez objetos. En el método de comparación por pares, el sujeto tuvo qua
comparar cada pareja posible de objetos y decir cual de los dos que estaba sosteniendo era el mas pesado. Este procedimiento produce n(n - 1)/2
comparaciones; con 10 objetos produce 45 comparaciones; y con 50 objetos se necesitan 1225 comparaciones. En el modelo inicial, Thurstone y
Chave no lo consideraron definitivo para la construcción de escalas de actitudes, e indicaron que "la escala ideal tendría que construirse
exclusivamente por votación" En 1932, Likert informó de un método de construcción de escalas de actitud al
que considero mas sencillo y que usaba la votación solamente. Y desde entonces se discute si el método de Likert es o no una opción adecuada o superior al
método de Thurstone. Aunque las comparaciones conceptuales y teóricas de ambos son extensas, ha
habido pocos intentos por someter a prueba empírica sus características relativas; tampoco se tiene noticia de que en fechas recientes se hayan tratado
de resumir tales comparaciones. Esta escasez de comparaciones empíricas directas es sorprendente. McNemar (1946) encontró que entre el principio de la medición
de actitudes y los datos de su articulo, se habían escrito mas de 800 artículos, estudios y libros acerca de la medición de actitudes y de opinión publica. La
tasa de producción se ha declinado, ciertamente, después de esa época. Sin embargo, después de una extensa búsqueda de estudios que aludieran a la
construcción, aplicación, o ambas, de las escalas de Thurstone y Likert como base de una comparación empírica directa de los dos métodos, solamente se
encontraron ocho artículos. En orden cronológico Son los siguientes: La comparación de Likert
La primera comparación de los métodos de Thurstone y Likert la hace este mismo
al proponer su método de construcción de escalas (Likert, 1932). Realmente, desarrollo dos métodos, el "método sigma" y el "método de
1-2-3-4-5". El segundo resulto mas sencillo y se correlaciono altamente con el método sigma (Likert, 1932). El método de 1-2-3-4-5 se conoce generalmente como
el método de Likert o el método de estimaciones sumatorias. En esta primera comparación, seńalo que el método de Thurstone. "es... excesivamente laborioso"
. Y además indico: "Parece legitimo preguntar si efectivamente trabaja mejor que las escalas mas sencillas que pueden emplearse, y de la misma manera averiguar
sino es posible construir escalas igualmente confiables sin hacer suposiciones estadísticas innecesarias". No obstante, concluyo: "Estoy muy lejos de pensar que
los datos que aquí se ofrecen pongan termino a la cuestión". Aun mas concretamente, Edwards y Kenney (1946) seńalan las cuatro hipótesis cardinales que hace Likert al
referirse a su método de estimaciones sumatorias: Mas comúnmente, el método de estimaciones sumatorias parece evitar muchos de los defectos de los métodos
existentes de medición de actitudes, pero al mismo tiempo conserva la mayoría de las
ventajas de los métodos actuales. Estas afirmaciones, debe seńalarse, han sido
vigorosamente discutidas, principalmente por Bird (1940) y Ferguson (1941).
(Edwards y Kenney, 1946,).
De orientación pragmática, la hipótesis 1 afirma que el método de Likert evita
las dificultades que se originan por el empleo de peritos. Si esto es verdad,
debe reflejarse en confiabilidades, cifras de validez y equivalencias entre las
escalas mas altas, y en disminución de gasto de tiempo y dinero. Por
consiguiente, la hipótesis 1. puede incluirse dentro de las tres siguientes. En
resumen, las hipótesis restantes afirman, muy generalmente, que el método de
Likert es tan confiable, tan valido y tan fácil de aplicar, o mas, que el método
de Thurstone. Cada una de estas hip6tesis esta sujeta a verificación empírica
directa. Por consiguiente, se usa como base para examinar las comparaciones
empíricas de ambos métodos.
Para probar las hipótesis anteriores, Likert (1932) uso los datos obtenidos en
un proyecto de investigación que inicio en 1929 junto con Gardner Murphy. En
cuanto al aspecto principal de la investigación, se reunieron preguntas sobre
cinco áreas de actitudes: relaciones internacionales, relaciones raciales,
conflicto económico, conflicto político y religión. Para ello elaboraron tres
escalas a partir de los reactivos reunidos, es decir, una escala de
internacionalismo (24 reactivos), una escala de imperialismo, (12 reactivos) y
una escala sobre los negros (15 reactivos). Con estas escalas, se aplicaron
cuestionarios que comprendían las tres escalas, a mas de 2000 estudiantes en
nueve universidades. De estos 2000 cuestionarios se seleccionaron, al azar, 650
para análisis completo. En la actualidad se emplea la tecnología de las
computadoras. Al mismo tiempo, aplico la escala de Thurstone-Droba sobre la
guerra (Droba, 1930) a dos de los nueve grupos de estudiantes universitarios.
Con estos datos, Likert contrastó de dos maneras los métodos de Thurstone y
Likert para construir escalas. Primero, comparó las confiabilidades de dos
escalas que se elaboraron independientemente por las dos técnicas de
construcción de escalas; la escala de internacionalismo de Likert se comparo con
la escala de Thurstone-Droba sobre la guerra. Segundo, comparo las
confiabilidades producidas por el par de técnicas cuando se califico la misma
escala (la escala sobre la guerra, de Thurstone-Droba).
Para la primera comparación, entre las confiabilidades de la escala de
internacionalismo y la escala de Thurstone-Droba (formas A y B; con 22 (temas o
reactivos cada una), se utilizaron datos de los grupos C y F a los que se habían
aplicado ambas escalas. Nótese que la confiabilidad de división a la mitad de la
escala de internacionalismo (en los dos grupos que completaron tanto la escala
de internacionalismo como la escala de Thurstone-Droba sobre !a guerra) fue la
misma en cada grupo: .88 (corregida por atenuación mediante la formula de
Spearman-Brown). Por comparación, las confiabilidades de los mismos dos grupos
en la escala sobre la guerra fueron de .88 y .85 (corregidas). Usando cerca de
la mitad del numero de reactivos, la técnica de Likert produjo una escala con
una confiabilidad de división a la mitad igual a la de la escala de Thurstone, o
dio una confiabilidad mas alta usando el mismo numero de reactivos. La
interpretación de estos resultados es que innegablemente es posible construir
una escala de actitud por el método de Likert, que proporciona confiabilidades
tan altas o mas que las producidas por el método de Thurstone.
Likert encontró asimismo que estas dos escalas, elaboradas independientemente,
se correlacionaron a .67 o .78 (corregida). Sin embargo, seria incorrecto
interpretar estos datos como indicación de que los dos métodos produjeron
escalas igualmente validas, puesto que inicialmente no se desarrollaron para
medir la misma cosa. Indicar posteriormente que parecen medir la misma cosa es
un análisis post hoc que no puede considerarse prueba de validación
convergentes.
La segunda comparación de Likert consideró los procedimientos de calificación
utilizados por ambos métodos. A uno de los grupos, el grupo C, se le aplicó la
escala sobre la guerra una segunda vez. Sin embargo, se modificaron las
instrucciones pidiéndose a los sujetos que indicaran sus actitudes por el método
de Likert, quien encontró que en cada forma de la escala de Thurstone-Droba sobre
la guerra había cuatro reactivos que no podían calificarse significativamente
usando su propio método. Por consiguiente, los excluyó dejando 18 reactivos en
cada forma de la escala. Sin embargo, Likert encontró que tres de sus escalas
correlacionaban entre si (de .34 a .63, sin corregir); y también advirtió que
esto probablemente indicaba la presencia de un factor común en todas ellas.
La tabla 2 resume los resultados obtenidos. En general, Likert encontró que su
método de calificación produjo una confiabilidad mas alta que la del método de
calificación de Thurstone en la misma escala. Explico este resultado indicando
que en el procedimiento de calificaci6n de Likert, "cada aseveración se
convierte en una escala". También encontró que los dos métodos de
calificación
de la misma escala se correlacionaban altamente: .92 (corregida). No se hace
ninguna consideración, sin embargo, sobre la cuestión de que tan válida puede
ser una puntuación en sentido absoluto. Es decir, no se analiza si las escalas
miden efectivamente lo que se proponen medir.
La comparación de Likert, Roslow y Murphy
Para comprobar mejor las hipotesis de Likert, de que su procedimiento de
calificacion produce resultados mas confiables que el procedimiento de
calificacion de Thurstone cuando se aplica a una escala de este mismo, Likert,
Roslow y Murphy (1934) seleccionaron diez escalas de actitudes, que habían
construido por el procedimiento de Thurstone. Después trataron de determinar si
el "metodo de calificación de Likert mostraba consistentemente que era
satisfactorio". Las escalas median actitudes hacia el control de la
natalidad, los chinos, el comunismo, la evolucion, los alemanes, Dios (2), los negros y la guerra (2). Los autores no explican su
motivación para seleccionar
estas escalas particulares.
Cada una de las diez escalas de Thurstone constaba de dos formas paralelas; en
total eran 20 escalas. Con respecto a cada una de estas, se elaboró una escala
modificada (adecuada para la calificación de Likert). Como indico Likert (1932)
algunos reactivos seleccionados para una escala de Thurstone no son adecuados
para una escala del primero. Likert descubrio que algunos reactivos de doble
significado hacían imposible determinar que valor asignar, si el 1 o el 5, e la
opcion "completamente de acuerdo". Por ejemplo, las personas qua se rechazan
fuertemente y las quo favorecen vigorosamente al adiestramiento militar
obligatorio podían estar completamente de acuerdo con la aseveración: "el
adiestramiento militar obligatorio en todos los países debe reducirse pero no
eliminarse". Dos personas con actitudes opuestas acaso apoyaran la aseveración,
según la parte de esta ("no eliminarse" o "reducirse") a la que la persona
respondiese.
Por consiguiente, para modificar cada una de las de
Thurstone, se excluyeron entre 1 y 6 reactivos. De esta manera se derivo un
total de 20 escalas adecuadas para el procedimiento de evaluación de Likert, a
partir de las 20 de Thurstone, o sea, Un total de 40 escalas. Debe seńalarse,
empero, que solamente se aplicaron las 20 escalas de Thurstone a los sujetos.
Las de Likert se formaron después que se habían llenado los cuestionarios, que
se calificaron luego, sencillamente, conforme al metodo de Likert y excluyendo
los reactivos que se consideraron inconvenientes.
Estas escalas se administraron a 12 grupos de estudiantes
universitarios varones, en Nueva York, así como a un grupo de estudiantes
varones del ultimo ańo de preparatoria, que se supone vivían también en Nueva
York (13 grupos en total). Pero no todas las escalas de actitudes se aplicaron a
todos los grupos. Las dos formas de cada escala se aplicaron a grupos que
variaban desde 1 hasta 7 estudiantes. Algunos grupos completaron solamente las
formas paralelas de una sola escala, mientras otros completaron las formas
paralelas de cinco.
Se instruyo a los estudiantes como sigue: "Si esta de acuerdo
con una aseveración ponga un signo de mas; si esta completamente de acuerdo con
la aseveración, ponga un signo de mas rodeado por un circulo; si está en
desacuerdo con una aseveración ponga un signo de menos; si esta totalmente en
desacuerdo con la aseveración ponga un signo de menos rodeado por un circulo; si
se encuentra indeciso, ponga un signo de interrogación". Despues que los
estudiantes indicaron sus reacciones, se calificaron las escalas por los métodos
de Thurstone y Likert. En la calificación de las escalas por el metodo del
primero, se considero cada signo de mas una ratificación; los signos de menos y
los de interrogación se consideraron no ratificaciones. En la calificación por
el metodo de Likert se determino primero la dirección del reactivo.
Concretamente los investigadores preguntaron: żuna respuesta de + (completamente
de acuerdo) indica una actitud favorable o desfavorable?. Después se asignaron
valores numéricos (1-2-3-4-5) a cada respuesta en la forma habitual de Likert.
La tabla 3 presenta los resultados típicos obtenidos. En
general, el metodo de ratificación de Likert produjo confiabilidades más altas
que las del metodo de Thurstone: En las 27 comparaciones solamente una vez el
metodo de Thurstone produjo una escala con una confiabilidad igual a la del
metodo de Likert y nunca una confiabilidad mas alta.
Una posible explicacion de estos resultados seria que los
reactivos mas inconfiables de la escale de Thurstone (los que tienden a caer
cerca de las categorías neutrales) son excluidos de la escala mas a menudo
cuando se califican por el metodo de Likert. "En general, las aseveraciones
cuyos valores escalares en el método de calificacion de Thurstone cayeron en
medio de la escala (de 8.0 a 6.0) fueron las que resultaron insatisfactorias. .
:" (Likert, Roslow y Murphy, 1934). En el grado en que se excluyeron los
reactivos menos confiables, de la calificación de Likert, la escala, como un
todo, se hizo más confiable. En verdad, si este fuera el caso, uno esperaría
que, cuando se excluyeran muchos reactivos inconfiables, la calificación de
Likert resultaría mas favorable que el metodo de Thurstone, y no así al
excluirse solamente uno o unos cuantos reactivos inconfiables, y viceversa.
Después de examinar los datos, este no parece ser el caso. Por consiguiente,
rechazamos esta hipótesis alterna.
Al mismo tiempo, los autores concluyeron que "Las puntuaciones obtenidas por los
dos metodos se correlacionan en alto grado, lo que indica que miden la misma
cosa". Estos resultados prestan mas apoyo a la hipótesis de Likert de que cuando
se califica una escala construida por el procedimiento de Thurstone, el método
de calificacion de Likert da resultados mas confiables que el método de aquel.
Puesto que los dos metodos se correlacionan altamente, son casi equivalentes o,
dicho en otra forma, igualmente validos.
La comparación de Ferguson
Ferguson indica que las conclusiones de Likert (1932) derivadas de sus datos
carecían parcialmente de fundamento. Ya que el articulo de Likert, Roslow y
Murphy (1934) fue una extensión del trabajo de Likert, las criticas de Ferguson
son aplicables a los dos artículos. Ferguson sostuvo que "procurando simplificar
este laborioso procedimiento (el método de Thurstone), Likert (1932) ideo una
técnica que, según el, eliminaba la necesidad de un grupo de peritos" (1941).
Sin embargo, mientras el indico, como lo hizo Likert, que aumentando el numero
de respuestas posibles en la escala se incrementa la confiabilidad, este hecho
no supera la necesidad de un grupo de peritos. Para hacer esta afirmación,
Ferguson sostuvo que: "Likert uso una escala que fue construida por el método de
intervalos aparentemente iguales, de Thurstone. Como las aseveraciones habían
sido seleccionadas por el procedimiento de clasificación, parece infundado
concluir que el método de Likert elimina la necesidad de peritos.
Aunque la critica
de Ferguson parece valida e importante, debe seńalarse que se aplica solamente
al procedimiento de comparar escalas elaboradas primero por el método de
Thurstone y calificadas después por ambos metodos. Este es el procedimiento
seguido por Likert (1932) en su comparación de las calificaciones de Thurstone y
Likert con respecto a la escala de Thurstone-Droba sobre la guerra; y es el
mismo aplicado por Likert, Roslow y Murphy, al comparar las confiabilidades de
las calificaciones de Thurstone y Likert en 10 escalas originales de Thurstone.
Como se indico antes, estos procedimientos comparan solamente el método de
calificación, no los métodos de elaboración de escalas. La critica no se aplica
a la comparación de Likert entre su escala de internacionalismo, derivada
independientemente, y la escala de Thurstone-Droba sobre la guerra, hecho qua no
advierten ni Ferguson (1941) ni Edwerds y Kenney (1946). Esta comparación, sin
embargo, tampoco satisface las indicaciones de Ferguson y Edwards y Kenney para
una comparación adecuada, ya qua no se pretende expresamente qua las dos escalas
sean medidas de la misma actitud. Por consiguiente, no se demostró que el metodo
de Likert para construir escalas fuese una alternativa igual o superior al
método de Thurstone.
Ferguson indico mas tarde que, para probar las hipótesis de Likert, "Se deben
comparar escalas construidas (independientemente del método de Thurstone) por la
tecnica de Likert con las elaboradas por el método de intervalos aparentemente
iguales". Ferguson complementó la indicación anterior al proponer: "Puede
lograrse una prueba mas conveniente reordenando una escala, construida con la
técnica de Likert, por el metodo de Thurstone. Si la técnica del primero excluye
la necesidad de un grupo de peritos, los dos metodos de tratar las aseveraciones
tendrán que arrojar los mismos resultados" [Edwards y Kennedy seńalan la
inconsistencia clue se revela entre la lógica de la critica que Ferguson hace a
las conclusiones de Likert y los medios de que se vale para complementar su
propia sugerencia (1946)]
Para hacer su comparación, Ferguson seleccionó la escala de la Encuesta de
Opiniones, de Minnesota (Rundquist y Sletto, 1936). Las escalas fueron cinco:
acerca de moral, familia, relación social, nivel económico y educación. El
cuestionario se aplico a 100 sujetos. Una vez que estos completaron el
cuestionario, se les pidió evaluar cada una de las escalas, es decir, que
colocaran los ítemes o reactivos de cada una formando un continuo de once
puntos, desde favorable hasta desfavorable (como lo hacen los peritos en el
procedimiento de Thurstone). Mas tarde se calcularon los valores escalares y los
valores Q, representando cada una de las aseveraciones en su escala
correspondiente. Ferguson encontró que, de las cinco escalas, solamente una de
ellas -la de nivel económico- poseía valores escalares mas o menos dispersos y
distribuidos uniformemente en el continuo. Las otras cuatro contenían
afirmaciones que "representan únicamente actitudes muy favorables o muy
desfavorables en el continuo". Por ejemplo, "en la escala de moral hay siete
aseveraciones entre los puntos 7 y 8 de la escala, pero solamente dos entre los
puntos 3 y 4. En la escala de familia hay ocho aseveraciones entre 7 y 8, y
ninguna entre 3 y 6"
Ferguson seńala,
del mismo modo, que "Si una persona concuerda con una aseveración cercana a los
puntos 7 y 8, teoricamente debe concordar con todas las que se agrupen alrededor
del mismo valor; de manera que, si no hay un numero igual de aseveraciones en
otras posiciones, la escala esta cargada artificialmente". Y termina con esta
conclusión algo dudosa:
Ya que la escala de nivel económico tiene la distribución mas adecuada de
aseveraciones sobre el continuo (pero también los valores Q mas altos), las
puntuaciones determinadas por los dos metodos se correlacionaron entre si y el
valor encontrado fue de .70, lo que confirma ampliamente la conclusión de que la
tecnica de Likert para construir escalas de actitud no evita la necesidad de un
grupo de peritos,
En resumen,
Ferguson planteo una cuestión importante acerca de la adecuación de la mayoría
de las comparaciones previas. Edwards y Kenney, como Ferguson, pasan por alto la
comparación hecha por Likert de la escala de Thurstone-Droba sobre la guerra y
la escala de internacionalismo de Likert. Hizo ver que los estudios
anteriores habían comparado solamente los procedimientos de calificación, pero
no los métodos completos de construcción de escalas de actitud.
Desafortunadamente, este diseńo de investigación estuvo mal adaptado a la tarea
que se propuso.
La comparación de Edwards y Kenney
Como se indicó antes, Edwards y Kenney (1946) resumieron la comparación de
Likert acerca de la mayor conveniencia del metodo de Likert sobre el metodo de
Thurstone en cuatro hipótesis:
la hipótesis 1, se
incluyo en las otras tres.
Edwards y Kenney estuvieron de acuerdo con Ferguson (1941) en su critica de
Likert: "Ya que las aseveraciones (utilizadas por Murphy y Likert) habían sido
seleccionadas por el procedimiento de clasificación (el de Thurstone), parecería
infundado concluir que el metodo de Likert eliminó la necesidad de un grupo de
peritos" (Ferguson, 1941). Además, Edwards y Kenney concordaron con la
sugerencia de Ferguson sobre una prueba mas adecuada: "Para probar este aspecto
adecuadamente, deben compararse las escalas construidas (independientemente del
metodo de Thurstone) por la técnica de Likert y las construidas por el metodo de
intervalos aparentemente iguales".
Pero, mientras Ferguson no explica enteramente su propia sugerencia, Edwards y
Kenney si lo hacen. Afirman que "Una comparaci6n valida de las técnicas de
Thurstone y Likert, en nuestra opinión, debe partir de un grupo original de
reactivos, no de los reactivos ya seleccionados por el procedimiento de
Thurstone y después calificados por el metodo de Likert; y no con reactivos
seleccionados por el procedimiento de Likert para luego hacer la escala por la
técnica de Thurstone". (Edwards y Kenney, 1946).
Por consiguiente, Edwards y Kenney dividieron al azar a 72 estudiantes en dos
grupos iguales. A un grupo se le pidio que juzgara las aseveraciones conforme al
procedimiento de Thurstone, mientras que al otro se le pidio que diera
respuestas, del tipo de Likert, a las mismas aseveraciones. Las aseveraciones
fueron la colección entera de reactivos usados originalmente por Thurstone y
Chave en la construccion de una escala para medir actitudes hacia la iglesia.
Dos días después, el primer grupo dio respuestas de Likert a las mismas
aseveraciones y el segundo actúo como un grupo de peritos de Thurstone. Usando
estos datos, se emplearon los procedimientos típicos para formar das escalas
equivalentes de Thurstone, de 20 reactivos cada una, y una escala de Likert de
25 reactivos. De los 25 reactivos usados en la escala de Likert, se tomaron 5
para una u otra escala de Thurstone. Después, 80 nuevos estudiantes elegidos al
azar fueron asignados a dos grupos aproximadamente iguales. El primer grupo
completo un cuestionario que contiene las dos escalas de Thurstone seguidas por
la escala de Likert. El procedimiento se invirtió en el segundo grupo.
Edwards y Kenney encontraron que la escala de Likert produjo una confiabilidad
de división a la mitad de .94, mientras que las escalas de Thurstone produjeron
una confiabilidad de formas paralelas de .88 (no corregida). Encontraron que la
forma 11 se correlaciono en un .72 con la escala de Likert (.79 no corregida) y
que la forma B se correlaciono en un .92 con la misma escala (1.00 corregida).
Concluyeron entonces que "es posible construir escalas por los dos métodos y
producir aun puntuaciones semejantes. Esto es lo que queremos dar a conocer"
A partir de sus datos, Edwards y Kenney llegaron además a la conclusión de que: El problema importante es el de si las
puntuaciones obtenidas en las dos escalas construidas en forma diferente son semejantes y la evidencia que se tiene indica que si lo son. Hasta donde fue
posible investigar, no hay nada de carácter practico que indique que un grupo de peritos, en el sentido de Thurstone, sea un prerrequisito para la construcción de una escala adecuada de actitud,
Artículo Enero 2008
UNA TÉCNICA PARA MEDIR ACTITUDES INTRODUCCIÓN Los
esfuerzos por medir los rasgos de carácter y personalidad datan casi de la misma época que las técnicas para medir la capacidad intelectual; pese a ello, muy
difícil sería sostener que aquéllos hayan logrado un éxito similar. La dificultad radica, al menos en parte, en las dificultades estadísticas que se
encuentran al considerar desde el punto de vista matemático los aspectos cotidianos de la conducta social que, ordinariamente se tratan como aspectos
cualitativos. La presente exposicion, aunque parte de una investigación más amplia emprendida en 1929 por Gardner Murphy, se ocupa principalmente de la
solución de un problema técnico que ha surgido en relación con los aspectos cuantitativos del estudio de las actitudes sociales.
La historia y la posición actual de la investigación sobre los rasgos de personalidad en general y las actitudes sociales en particular han sido
revisadas extensamente por Murphy (21, págs. 381-386 y 22, págs, 558-690), Bain, Vetter (41), Katz y Allport (16), Watson (43).
Sin embargo, entre los centenares de esfuerzos dirigidos a medir las actitudes sociales realizados durante los últimos ańos, han recibido atención especial,
con todo derecho, los cuidadosos procedimientos desarrollados por Thurstóne (34, 38). Se caracterizan por el empeńo especial tendiente a igualar los intervalos
de una actitud y otra, en la escala de actitud, usando para tales determinaciones los métodos familiares de la psicofísica. Los métodos de
Thurstone han demostrado una confiabilidad satisfactoria y, en términos de correlaciones entre puntuaciones e historias de casos evaluadas por peritos, una
validez igualmente satisfactoria Existen muchas afinidades obvias entre esta presentación y los de Thurstone; no
obstante, el presente informe constituye en cierta forma una separación radical de los conceptos que ha publicado Thurstone, como, por ejemplo, el empleo de
peritos. Se han hecho varias suposiciones estadísticas en la aplicación de sus escalas de
actitudes -por ejemplo, que los valores escalares de las aseveraciones son independientes de la distribución de actitud de los lectores- que clasifican
dichas aseveraciones -, las cuales, como seńala Thurstone, no han sido verificadas. El método es además excesivamente laborioso. Parece legítimo.
preguntar si efectivamente trabaja mejor que las escalas más sencillas y también si no es posible construir otras igualmente confiables sin hacer suposiciones
estadísticas innecesarias. Ya que tanto se ha publicado acerca de la medición de actitudes, vale la pena hacer estas preguntas e informar de algunos resultados
relativos al problema. PROCEDIMIENTO
El proyecto concebido en 1929 por Gardner y Murphy y Lickert, se ocupó primeramente de presentar una amplia variedad de problemas que tienen que ver
con estas cinco "áreas de actitud" importantes: relaciones internacionales, relaciones raciales, conflicto económico, conflicto político y religión.
El método por el cual se elaboró el cuestionario es el siguiente: después de haber decidido estudiar intensivamente el asunto de las actitudes
internacionales, interraciales y económicas y, en menor grado, las actitudes políticas y religiosas, entre grandes números de estudiantes en
universidades norteamericanas típicas, se hizo un examen de los cuestionarios aplicados, con los mismos propósitos, por otros psicólogos. Entre los que se
encontraron particularmente útiles están los de G.B. Neumann, C.W. Hunter y R.W. George. Además, durante el otońo de 1929, se examinaron rápidamente cerca de 200
periódicos y revistas; se entresacaron declaraciones de opinión, prefiriéndose marcadamente los tipos más dogmáticos de opinión, encontrados a menudo en los
editoriales. Se incluyó un número pequeńo de preguntas tomadas de libros, discursos y panfletos y otro elaborado por los investigadores mismos. Siempre
que fue posible usar material de cuestionario, que ya hubiera sido probado extensamente y dispusiese asimismo de alguna especie de "normas", se emplean las
preguntas exactamente como se expresaron. En pocos casos fue necesario abreviar y simplificar las preguntas para estar seguro de que solamente se consideraba un
asunto y de que se evitaba la ambigüedad. En todos los casos en las preguntas se buscaron principalmente la sencillez, claridad y brevedad.
En tosas se presentaron las preguntas en tal forma que permitían un "juicio de valor" y no "juicios descriptivos". Frases como "los Estados Unidos deben", o
"deberíamos", o "a ninguna persona se le debe permitir", aparecieron constantemente. En pocos casos se percibe a primera vista que cierta pregunta se
refiere a hechos precisos; pero un análisis más cuidadoso revelará el carácter altamente arbitrario de tales "hechos". Es probable que la menos deseable de
todas las preguntas aplicadas fue la siguiente: "żEs la guerra actual una necesidad biológica? " Esta pregunta pareció a muchos que era categóricamente
una pregunta descriptiva; por ejemplo, desde el punto de vista neomalthusiano puede considerarse que sólo puede recibir una respuesta afirmativa. Sin embargo,
el término "necesidad" se refiere aquí más a las actitudes del estudiante hacia varios deseos que hacia algunos tipos de necesidad discutidas por físicos o
lógicos. No es ésta una defensa al uso de este reactivo particular, que creemos debe ser omitido; se da esta explicación solamente para esclarecer que, por lo
menos en la gran mayoría de los casos y esperamos que en todos, la pregunta tiene que referirse a los deseos, anhelos, disposiciones voluntarias de los
sujetos, y no a sus opiniones con respecto a situaciones de hecho.
Con la colaboración de instructores, se aplicaron los tests de actitudes a estudiantes no graduados (principalmente varones) de nueve universidades que se
extienden desde Illinois a Connecticut y de Ohio y Pennsylvania a Virginia. El número total de individuos que participaron fue algo superior a 2000 pero los
datos analizados ampliamente correspondieron solamente a 650 personas. El test de actitudes, llamado "Encuesta de Opiniones", se aplicó primero a fines del
otońo de 1929 (a todos los grupos, con excepción del grupo C y el grupo F, a quienes se les aplicó en 1931), y mediante arreglos con los instructores se
aplicó un retest 30 días después. Algunos reactivos del primero y muchos reactivos nuevos se incluyeron en el segundo test. El primero requirió en
promedio 40 minutos aproximadamente y el retest un poco más.
El tipo de material del cuestionario que se usó se clasifica en cuatro categorías principales. En la primera, las preguntas se contestaron con un sí,
con una marca en la pregunta o con un no; por ejemplo "żApoya usted la entrada inmediata de los Estados Unidos a la Liga de las Naciones? " "żSí o no? " En
seguida venía una serie de preguntas de selección múltiple en las que se escogía una de cinco respuestas posibles, por ejemplo: "Usando el término "armamentos"
para significar equipo diseńado para la guerra y no para fines policíacos, nuestra política debe propiciar: a) el desarme absoluto e inmediato de todas las
naciones, b) la reducción rápida y drástica del armamento en todas las naciones, c) la reducción lenta pero firme de todo armamento, d) mantener durante largo
tiempo el actual poderío militar y naval, e) nuestra libertad militar y expansión naval estorbada por los acuerdos con otras naciones". Tercero, había
una serie de proposiciones para ser contestadas con las palabras a) aprobada totalmente, b) aprobado, c) en dudo, d) desaprobado, e) desaprobada totalmente;
por ejemplo: "todos los individuos que tengan oportunidad deben alistarse en los Campos de Adiestramiento Militar". Cuarto, una serie de narraciones
periodísticas abreviadas sobre conflictos sociales, que concluían en una oración que describía el resultado de este conflicto; se le pidió al estudiante que
indicara w respuesta a este resultado; por ejemplo: "Un grupo de agricultores japoneses del sur de California, debido a su laboriosidad y a su bajo nivel de
vida, puede vender más barato que sus competidores norteamericanos. Los agricultores norteamericanos insisten en que ES DEBER DE TODAS LAS PERSONAS
BLANCAS COMPRAR SOLAMENTE A LOS AGRICULTORES BLANCOS". Esta forma de pregunta utiliza el mismo grupo de cinco respuestas mencionado, aprobado totalmente,
aprobado, en duda, desaprobado y desaprobado totalmente.
RESULTADOS El método sigma de calificación
Para comparar un tipo de aseveración con otro, por ejemplo el de "selección múltiple" con el de "aprobado totalmente", fue necesario idear una técnica
especial. Con tal motivo se advirtió que un gran número de las aseveraciones de cinco puntos, es decir, las de "selección múltiple" o "aprobado totalmente" (en
cada caso se le ofrecían al sujeto cinco alternativas para que escogiera una), producían una distribución semejante a la normal (véase tabla 1).
Con base en esta evidencia experimental y en los resultados de otros autores, parece estar justificado, para fines experimentales, suponer que las actitudes
están distribuidas en forma claramente normal y extender esta suposición a la operación de combinar las diferentes aseveraciones. Nos percatamos plenamente de
los posibles peligros inherentes en esta suposición; y por ello se formula sencillamente como parte de un enfoque experimental de la medición de actitud.
Se espera que el trabajo subsecuente en este campo la hará innecesaria o probará su validez.
El porcentaje de individuos que marcaron cierta posición en una aseveración particular se
convirtió en valores sigma. Esto se repitió con cada una de las aseveraciones de cinco puntos que se refieren al internacionalismo. La tabla 22 de las tablas de Thorndike facilita grandemente el cálculo. Estas tablas suponen que el 100% de los casos caen entre-3 y + 3 sigma. Los valores dados en la tabla son los
valores sigma promedio de los intervalos representados por los porcentajes indicados; se considera que el origen está en la media. Las desviaciones sigma
se tomaron siempre a partir de la media y se asignó el valor positivo al extremo que parecía propiciar el internacionalismo; y el negativo al extremo que
favorecía el nacionalismo. Para evitar el uso de valores negativos se colocó el cero arbitrario en -3 sigma y no en la media. Estos signos se designaron de una
manera arbitraria y después se verificaron objetivamente. Los valores sigma se computaron a partir de los porcentajes obtenidos en una muestra de 100 casos,
todos varones, seleccionados dentro de una sola universidad. La tabla 2 registra el porcentaje de individuos que marcaron cada una de las diferentes opciones y
los valores sigma correspondientes a la aseveración número 16 de la escala de internacionalismo.
Las aseveraciones elegidas fueron examinadas en cuanto a consistencia interna o "agrupamiento" determinando la confiabilidad al contrastar las aseveraciones
impares con las pares. Las 14 aseveraciones de cinco puntos que se emplearon produjeron confiabilidades moderadamente altas al probarse en tres grupos
diferentes de 30 a 35 sujetos cada uno. Dos de estos grupos eran de la misma universidad y el tercero de otra, que está en una región geográfica
completamente diferente. Estos resultados indican la existencia de un "grupo" o variable de actitud que justifica tratarla como una unidad, esto por lo que toca
a los tres grupos. Las confiabilidades obtenidas en estos grupos se dan en la tabla 3. Estos resultados y las consideraciones siguientes parecen justificar la
afirmación de que la técnica de calificación sigma es la más satisfactoria para medir las actitudes. No solo parece evitar muchas de las dificultades que
revisten los métodos actuales sino que conserva al mismo tiempo la mayoría de las ventajas de aquéllos.
En primer lugar, el método de calificación sigma satisface el requisito seńalado por Thurstone:
Idealmente, la escala debería construirse solamente por medio de la votación. Es posible formular el problema de manera que los valores escalares de las
aseveraciones puedan extraerse de los registros de votación efectiva. Si esto fuera factible, el procedimiento presente para establecer los valores escalares
por clasificación sería inútil. Se evitan, además, las dificultades que se encuentran cuando se recurre a un
grupo de peritos para elaborar la escala. Varias de estas dificultades han sido seńaladas por Rice; la cita siguiente se refiere a uno de los defectos
principales de cualquier técnica que emplee cierto número de peritos: Las dificultades para elaborar escalas como la de Thurstone y aplicarlas a la
medición de las actitudes de grupos sociales aumentan tan pronto como dejamos la clase, el club de debates y otros grupos pequeńos, relativamente poco frecuentes
y muy selectos, que disfrutan con la práctica de experimentar consigo mismos. Estos grupos ya han desarrollado maneras de articular sus actitudes. En cambio,
los grupos de trabajo más numerosos de la sociedad son inaccesibles a las medidas controladas; es con respecto a sus actitudes que el científico social
necesita mucho mayor información. En relación con la tarea de clasificación de las tarjetas que contienen las proposiciones, a los estudiantes se les puede
pedir simplemente que lo hagan, a los profesores se les puede halagar y a las personas necesitadas se les pagaría por ello. Pero es difícil imaginar cómo
obtener juicios semejantes o medidas satisfactorias, en la aplicación final, de albańiles, hombres de negocios, italo-norteamericanos, monjas, estibadores o
costureras. Y, a menos que la escala se base en diferencias aparentemente iguales de una muestra al azar que pertenezca al grupo que se va a medir, su
validez -el grado en que mide lo que se propone medir- queda a consideración.
Otra ventaja decisiva de la técnica sigma es que, con un menor número de reactivos, produce confiabilidades tan altas como las obtenidas por otras
técnicas. Esto es posible porque enfrenta el problema de modo diferente al convencional. Ya desde antes se pretendía encontrar el valor escalar de cada
aseveración particular a lo largo de un continuo; entonces, la puntuación de una persona se determinaba por el valor escalar de las aseveraciones que admitía.
Sin embargo, en este estudio cada aseveración se convierte en una escala y la reacción de cierta persona a cada una de aquéllas da una puntuación. Después se
combinan estas puntuaciones usando la mediana o la media. El estudio de Eggan, del cual informa Thurstone, aporta mayores pruebas en apoyo del método
presentado. Al considerar este
método para medir las actitudes es necesario darse cuenta que, cuanto más fuerte es el grupo genérico en un extremo u otro del continuo de actitud, tanto más
influye en las reacciones específicas. Cuando el grupo genérico no es fuerte, los reactivos específicos determinan en gran parte la reacción. A pesar de ello,
en el último caso rara vez es muy intensa la reacción en favor o en contra; más bien es moderada. Es decir, las reacciones individuales, por lo que toca a esa
actitud particular, no se desvían mucho del promedio.
La técnica sigma produce también puntuaciones cuyas unidades son iguales en toda la extensión de la amplitud. Además, se pueden obtener las clases de medidas con
otras de las técnicas actuales. Por tanto, es posible obtener la medida más típica de la actitud de un individuo y también la amplitud o dispersión de la
misma. Es innecesario decir que la construcción de una escala de actitud mediante el método sigma es
mucho más fácil que usando un grupo de peritos para que coloquen las aseveraciones en grupos y de ahí calcular los valores escalares.
Entre las características más notables del método de Thurstone para construir escalas de actitud están las pruebas objetivas que desarrolló con respecto a la
ambigüedad e inadecuación. Si así se desea pueden aplicarse pruebas objetivas similares en la técnica sigma.
Método simplificado de calificación Aunque la técnica sigma parece completamente satisfactoria para el uso
propuesto, se decidió ensayar otra más sencilla para determinar si los resultados eran semejantes a los de aquélla. En tal caso, el método simplificado
ahorraría mucho trabajo en un estudio de encuesta del tipo que hemos realizado. La técnica simplificada consiste en asignar valores de 1 a 5 a cada una de las
cinco posiciones diferentes de las aseveraciones de cinco puntos. El extremo 1 se asignaría siempre al extremo negativo de la escala sigma; y el extremo 5, al
positivo de dicha escala (véase tabla 2). Después de asignar así los valores numéricos a las respuestas posibles, se
determinó la puntuación de cada individuo encontrándose el promedio de los valores numéricos de las posiciones que marcó. En realidad se usó la suma de las
puntuaciones numéricas y no la media porque el número de aseveraciones fue igual en todos los individuos. La confiabilidad de impares en contraste con los pares,
produjo esencialmente los mismos valores que los obtenidos con el método sigma de calificación. Las puntuaciones obtenidas con este y con el método sigma se
correlacionaron casi perfectamente como puede apreciarse en la tabla 4.
Tales resultados parecen justificar el uso de métodos más simples de
calificación ya que producen resultados casi idénticos a los del método sigma y
no contienen los errores que probablemente sí se presentan en las técnicas que
usan expertos, peritos o evaluadores.
Comparación entre el método simplificado y el método de calificación de
Thurstone A los
grupos C y F se les aplicó la escala sobre la guerra de Thurstone-Droba así como
la Encuesta de Opiniones. La tabla 5 presenta los coeficientes de confiabilidad
obtenidos con la escala y con la encuesta en ambos grupos. Los coeficientes de
confiabilidad del test de Thurstone, obtenídos correlacionando la forma A y la
B, fueron respectivamente de .78 y de .74 en dichos grupos. La confiabilidad de
las dos formas combinadas. Determinada por la fórmula de Spearman-Brown, es .88
y .85, respectivamente. Se obtuvo la misma confiabilidad con nuestra escala de
internacionalismo de 24 reactivos que la obtenida al combinar ambas formas de la
escala de Thurstone-Droba con un total de 44 reactivos. En consecuencia,
siguiéndose el método aquí descrito, en el que se pide a la persona que responda
a la mitad de los reactivos, se obtiene una medida de la actitud, tan confiable
como la proporcionada por el método de Thurstone. Los coeficientes de
correlación entre la Escala de Internacionalismo y la escala de Thurstone-Droba
se dan también en la tabla 5.
En virtud de que el método presentado aquí, al ser comparado con el método de
Thurstone, dio pruebas de producir la misma confiabilidad con menos reactivos, o
confiabilidades más altas con el mismo número de reactivos, se decidió aplicar
el método de calificación de 1 a 5 en la escala, de Thurstone-Droba, sobre la
guerra para confrontarlo con el método de calificación de Thurstone. A cada
individuo del grupo C se le pidió que indicara si estaba completamente de
acuerdo, de acuerdo, en duda, en desacuerdo o completamente en desacuerdo, con
cada aseveración de la escala de Thurstone-Droba sobre la guerra, formas A y B.
No se calificaron cuatro aseveraciones de cada forma porque fue virtualmente
imposible determinar si debería asignarse el valor 1 o 5 a la opción
"completamente de acuerdo". Un ejemplo de estas aseveraciones es la número 5 de
la forma A: "El adiestramiento militar obligatorio en todos los países debe
reducirse pero no eliminarse". Es imposible decir si una persona concuerda o
discrepa con el sentido de "reducción" que aparece en esta aseveración o con el
sentido de "no eliminarse". Una persona que se oponga completamente al
adiestramiento militar obligatorio discreparía mediana o fuertemente con el
aspecto "no eliminarse'; mientras que una persona que lo apoye discreparía
mediana o fuertemente con el aspecto "reducción"; que está en esa aseveración.
Evidentemente, con respecto al método de calificación de 1 a 5, la aseveración
tiene doble significado y es de poco valor porque no distingue a las personas en
término de sus actitudes. Las personas en cualquier extremo del continuo de
actitud pueden marcar fácilmente la misma opción.
Otro ejemplo de
aseveración que no pudo usarse es la número 17 de la forma B: "Las guerras a
menudo corrigen tremendos errores". Podía considerársela una aseveración
relativa a un hecho y así ser aceptada o rechazada por una persona
independientemente de su actitud. Las otras aseveraciones que no se usaron
fueron: .- Forma A,
aseveraciones 8, 10 y 17.
.- Forma B,
aseveraciones 5, 10 y 20.
El criterio de consistencia interna se usó como prueba objetiva para ver 1. si
los valores numéricos se asignaron adecuadamente y 2. si cada aseveración
diferenciaba los extremos de la manera esperada.
Se obtuvo los
resultados esperados, los cuales se incluyen en la tabla 6. El método de
calificación de 1 a 5 con menos reactivos, usado en cada forma, produjo un
coeficiente de confiabilidad tan alto, en una forma, como el método de Thurstone
en las dos formas combinadas.
Los dos métodos de
calificación se correlacionan muy estrechamente a .83, cifra que al ser
corregida por atenuación se convierte en .92. Es posible que si se hubieran
usado las mismas aseveraciones en ambos métodos y no eliminando las cuatro
mencionadas en cada forma con respecto a la calificación de 1 a 5, se hubiera
obtenido un coeficiente de correlación entre ambos métodos todavía más alto
BIBLIOGRAFÍA
Tabla 1.- Coeficientes de confiabilidad de las puntuaciones de actitud del diferencial semantico (D) y de las puntuaciones de las
escalas de Thurstone (T). Los subíndices 1 y 2 se refieren al primero y segundo examen
Objeto de actitud
rs1t1
rs2t2
rt1t2
rs1s2
La iglesia
.74
.76
.81
.83
La pena capital
.81
.77
.78
.91
Los negros
.82
.81
.87
.87
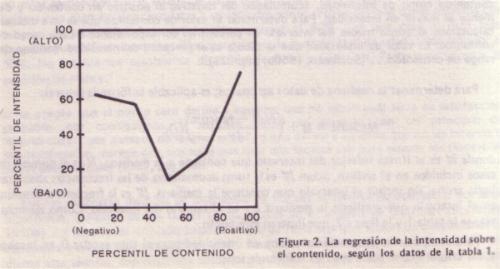
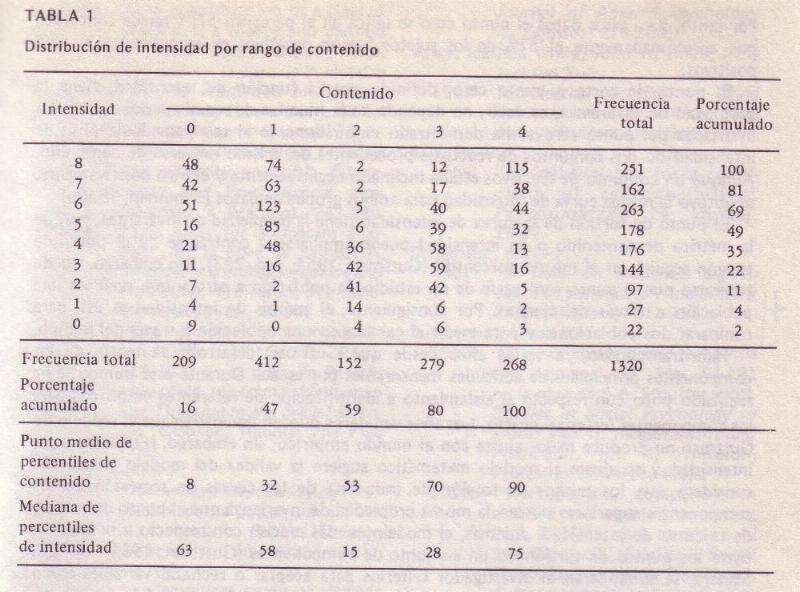

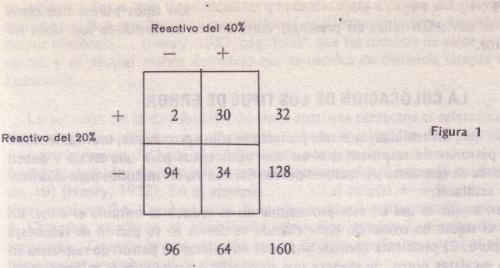
.026 X 2000 = 52
52x1=52
número máximo de errores
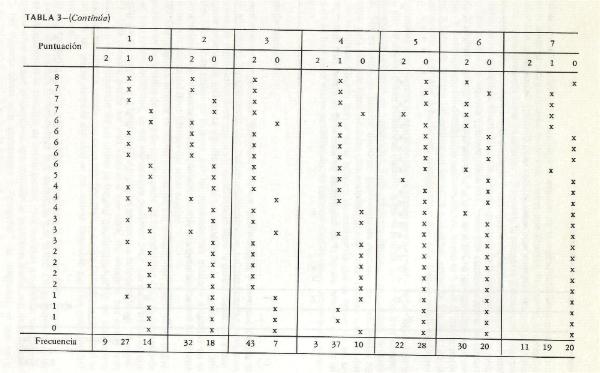
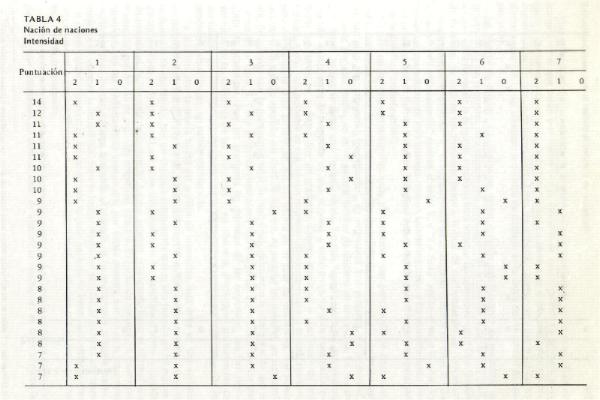
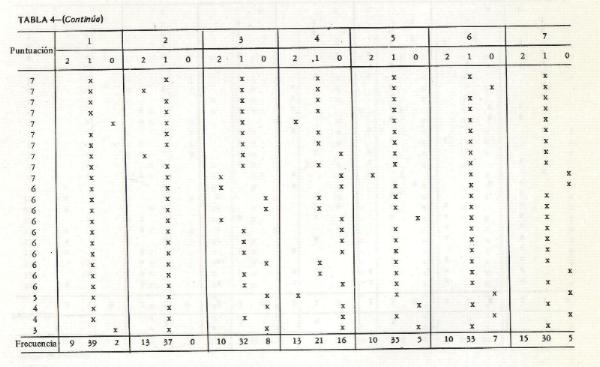
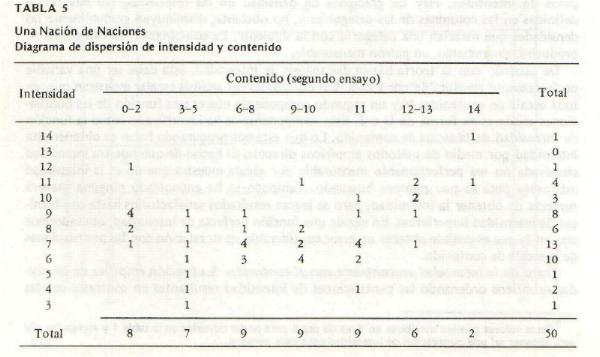
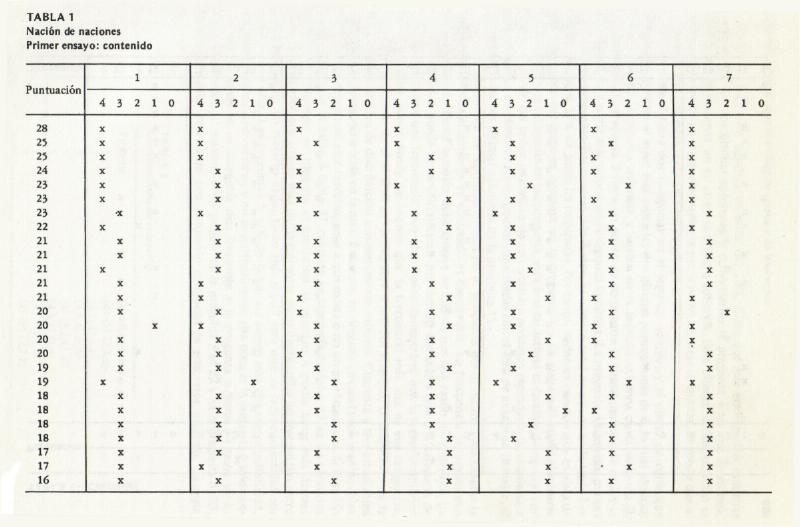
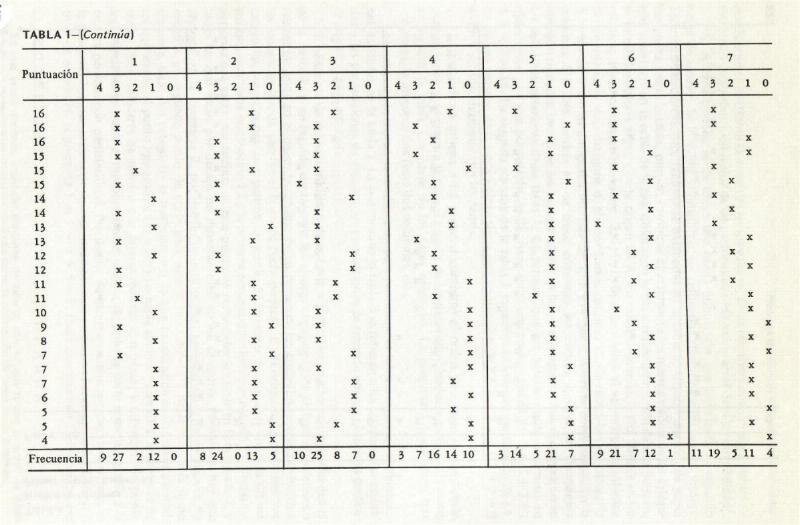
Combinaciones de categorías
Pregunta
Combinaciones
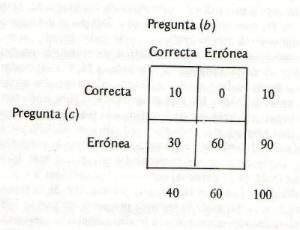

V V V
V V V
V
V V
V V V

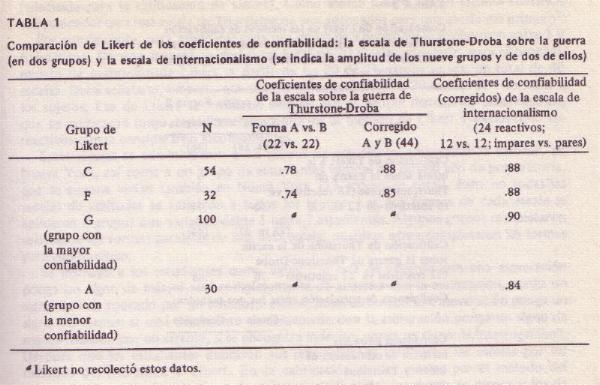


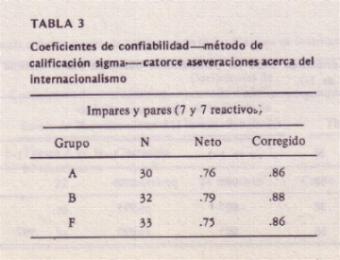
Los mismos resultados se obtuvieron cuando se asignaron los valores, 1, 3, 4, 5
y 7 a las diferentes posiciones que corresponden respectivamente a 1, 2, 3, 4 y
5. En el primer caso, se advertirá que se dio a los extremos un peso ligeramente
mayor. Este método se correlacionó asimismo altamente con el método sigma y con
el método de 1 a 5 como se indica en la tabla 4.


